 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinaTools: Open Source Toolkit for Arabic Natural Language Processing
Nov 03, 2024
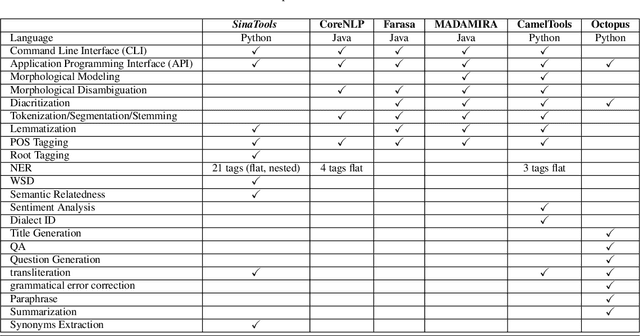
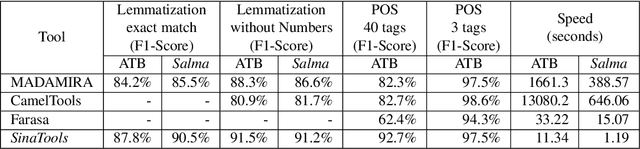
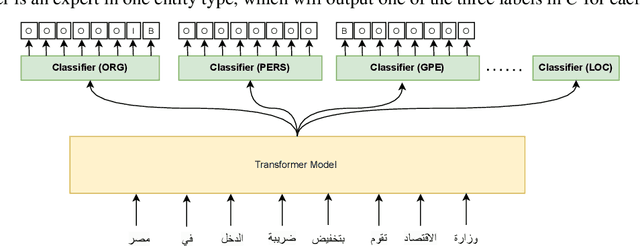
We introduce SinaTools, an open-source Python package for Arabic natural language processing and understanding. SinaTools is a unified package allowing people to integrate it into their system workflow, offering solutions for various tasks such as flat and nested Named Entity Recognition (NER), fully-flagged Word Sense Disambiguation (WSD), Semantic Relatedness, Synonymy Extractions and Evaluation, Lemmatization, Part-of-speech Tagging, Root Tagging, and additional helper utilities such as corpus processing, text stripping methods, and diacritic-aware word matching. This paper presents SinaTools and its benchmarking results, demonstrating that SinaTools outperforms all similar tools on the aforementioned tasks, such as Flat NER (87.33%), Nested NER (89.42%), WSD (82.63%), Semantic Relatedness (0.49 Spearman rank), Lemmatization (90.5%), POS tagging (97.5%), among others. SinaTools can be downloaded from (https://sina.birzeit.edu/sinatools).
Qabas: An Open-Source Arabic Lexicographic Database
Jun 06, 2024


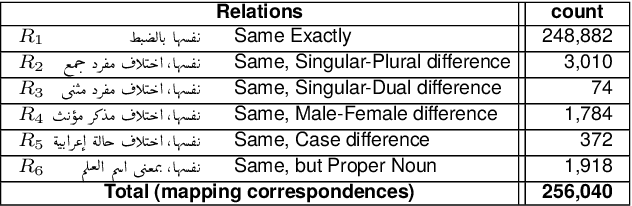
We present Qabas, a novel open-source Arabic lexicon designed for NLP applications. The novelty of Qabas lies in its synthesis of 110 lexicons. Specifically, Qabas lexical entries (lemmas) are assembled by linking lemmas from 110 lexicons. Furthermore, Qabas lemmas are also linked to 12 morphologically annotated corpora (about 2M tokens), making it the first Arabic lexicon to be linked to lexicons and corpora. Qabas was developed semi-automatically, utilizing a mapping framework and a web-based tool. Compared with other lexicons, Qabas stands as the most extensive Arabic lexicon, encompassing about 58K lemmas (45K nominal lemmas, 12.5K verbal lemmas, and 473 functional-word lemmas). Qabas is open-source and accessible online at https://sina.birzeit.edu/qabas.
SALMA: Arabic Sense-Annotated Corpus and WSD Benchmarks
Oct 29, 2023SALMA, the first Arabic sense-annotated corpus, consists of ~34K tokens, which are all sense-annotated. The corpus is annotated using two different sense inventories simultaneously (Modern and Ghani). SALMA novelty lies in how tokens and senses are associated. Instead of linking a token to only one intended sense, SALMA links a token to multiple senses and provides a score to each sense. A smart web-based annotation tool was developed to support scoring multiple senses against a given word. In addition to sense annotations, we also annotated the corpus using six types of named entities. The quality of our annotations was assessed using various metrics (Kappa, Linear Weighted Kappa, Quadratic Weighted Kappa, Mean Average Error, and Root Mean Square Error), which show very high inter-annotator agreement. To establish a Word Sense Disambiguation baseline using our SALMA corpus, we developed an end-to-end Word Sense Disambiguation system using Target Sense Verification. We used this system to evaluate three Target Sense Verification models available in the literature. Our best model achieved an accuracy with 84.2% using Modern and 78.7% using Ghani. The full corpus and the annotation tool are open-source and publicly available at https://sina.birzeit.edu/salma/.
Nabra: Syrian Arabic Dialects with Morphological Annotations
Oct 26, 2023
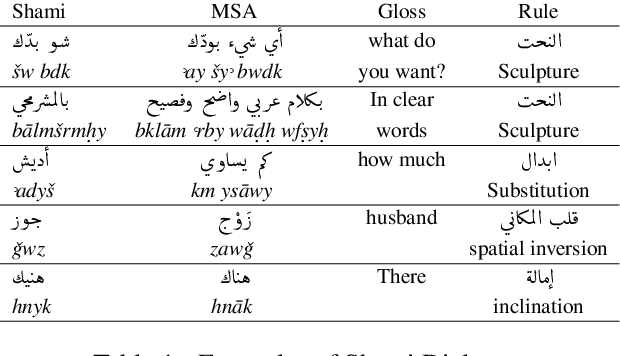

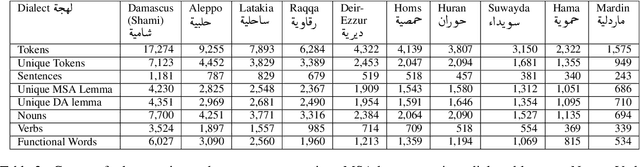
This paper presents Nabra, a corpora of Syrian Arabic dialects with morphological annotations. A team of Syrian natives collected more than 6K sentences containing about 60K words from several sources including social media posts, scripts of movies and series, lyrics of songs and local proverbs to build Nabra. Nabra covers several local Syrian dialects including those of Aleppo, Damascus, Deir-ezzur, Hama, Homs, Huran, Latakia, Mardin, Raqqah, and Suwayda. A team of nine annotators annotated the 60K tokens with full morphological annotations across sentence contexts. We trained the annotators to follow methodological annotation guidelines to ensure unique morpheme annotations, and normalized the annotations. F1 and kappa agreement scores ranged between 74% and 98% across features, showing the excellent quality of Nabra annotations. Our corpora are open-source and publicly available as part of the Currasat portal https://sina.birzeit.edu/currasat.
Lisan: Yemeni, Iraqi, Libyan, and Sudanese Arabic Dialect Copora with Morphological Annotations
Dec 17, 2022This article presents morphologically-annotated Yemeni, Sudanese, Iraqi, and Libyan Arabic dialects Lisan corpora. Lisan features around 1.2 million tokens. We collected the content of the corpora from several social media platforms. The Yemeni corpus (~ 1.05M tokens) was collected automatically from Twitter. The corpora of the other three dialects (~ 50K tokens each) came manually from Facebook and YouTube posts and comments. Thirty five (35) annotators who are native speakers of the target dialects carried out the annotations. The annotators segemented all words in the four corpora into prefixes, stems and suffixes and labeled each with different morphological features such as part of speech, lemma, and a gloss in English. An Arabic Dialect Annotation Toolkit ADAT was developped for the purpose of the annation. The annotators were trained on a set of guidelines and on how to use ADAT. We developed ADAT to assist the annotators and to ensure compatibility with SAMA and Curras tagsets. The tool is open source, and the four corpora are also available online.
Curras + Baladi: Towards a Levantine Corpus
May 19, 2022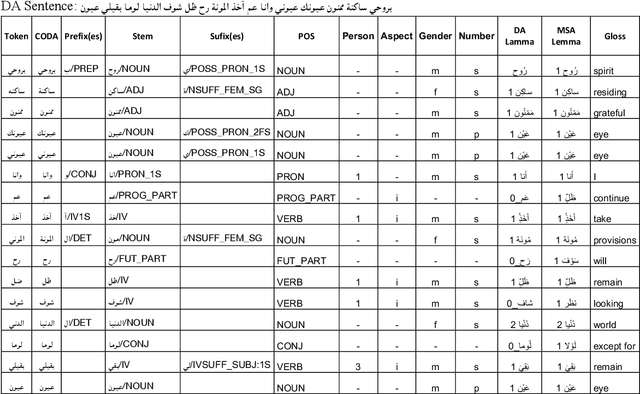
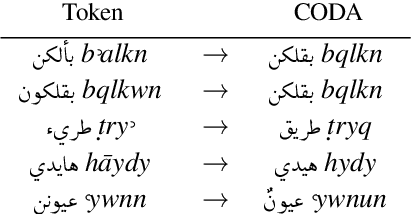
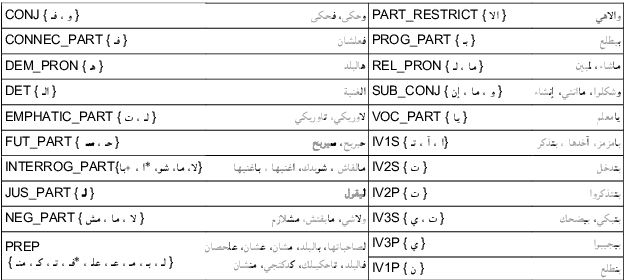
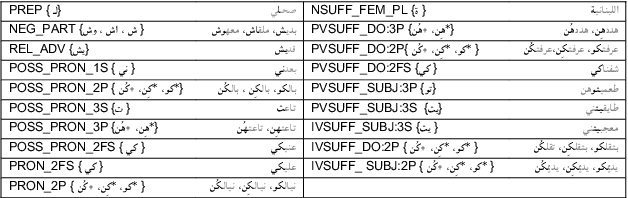
The processing of the Arabic language is a complex field of research. This is due to many factors, including the complex and rich morphology of Arabic, its high degree of ambiguity, and the presence of several regional varieties that need to be processed while taking into account their unique characteristics. When its dialects are taken into account, this language pushes the limits of NLP to find solutions to problems posed by its inherent nature. It is a diglossic language; the standard language is used in formal settings and in education and is quite different from the vernacular languages spoken in the different regions and influenced by older languages that were historically spoken in those regions. This should encourage NLP specialists to create dialect-specific corpora such as the Palestinian morphologically annotated Curras corpus of Birzeit University. In this work, we present the Lebanese Corpus Baladi that consists of around 9.6K morphologically annotated tokens. Since Lebanese and Palestinian dialects are part of the same Levantine dialectal continuum, and thus highly mutually intelligible, our proposed corpus was constructed to be used to (1) enrich Curras and transform it into a more general Levantine corpus and (2) improve Curras by solving detected errors.