 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerendipitous Recommendation with Multimodal LLM
Jun 09, 2025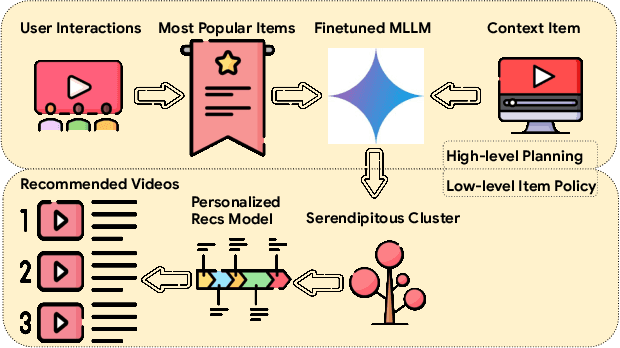
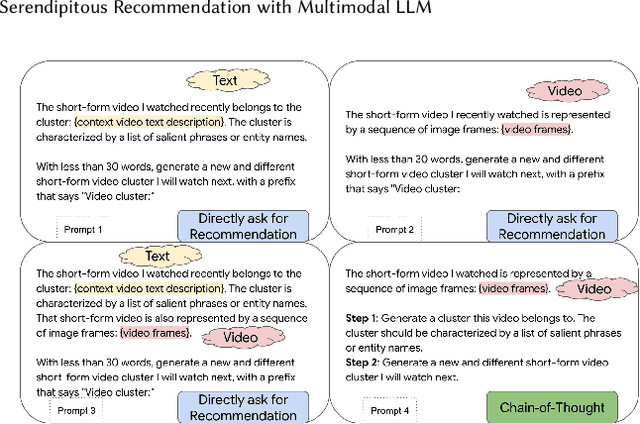
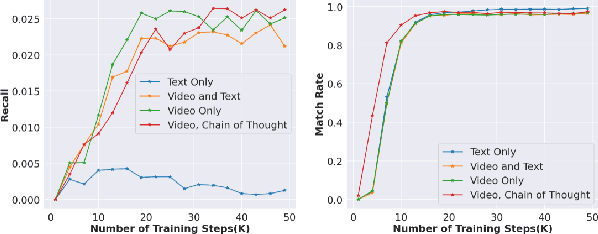
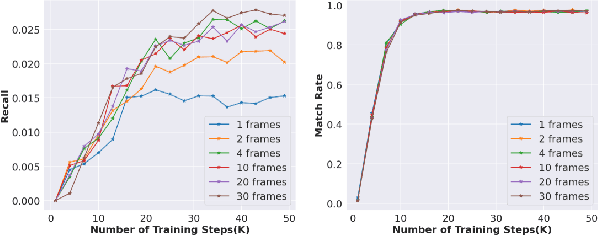
Conventional recommendation systems succeed in identifying relevant content but often fail to provide users with surprising or novel items. Multimodal Large Language Models (MLLMs) possess the world knowledge and multimodal understanding needed for serendipity, but their integration into billion-item-scale platforms presents significant challenges. In this paper, we propose a novel hierarchical framework where fine-tuned MLLMs provide high-level guidance to conventional recommendation models, steering them towards more serendipitous suggestions. This approach leverages MLLM strengths in understanding multimodal content and user interests while retaining the efficiency of traditional models for item-level recommendation. This mitigates the complexity of applying MLLMs directly to vast action spaces. We also demonstrate a chain-of-thought strategy enabling MLLMs to discover novel user interests by first understanding video content and then identifying relevant yet unexplored interest clusters. Through live experiments within a commercial short-form video platform serving billions of users, we show that our MLLM-powered approach significantly improves both recommendation serendipity and user satisfaction.
User Feedback Alignment for LLM-powered Exploration in Large-scale Recommendation Systems
Apr 07, 2025Exploration, the act of broadening user experiences beyond their established preferences, is challenging in large-scale recommendation systems due to feedback loops and limited signals on user exploration patterns. Large Language Models (LLMs) offer potential by leveraging their world knowledge to recommend novel content outside these loops. A key challenge is aligning LLMs with user preferences while preserving their knowledge and reasoning. While using LLMs to plan for the next novel user interest, this paper introduces a novel approach combining hierarchical planning with LLM inference-time scaling to improve recommendation relevancy without compromising novelty. We decouple novelty and user-alignment, training separate LLMs for each objective. We then scale up the novelty-focused LLM's inference and select the best-of-n predictions using the user-aligned LLM. Live experiments demonstrate efficacy, showing significant gains in both user satisfaction (measured by watch activity and active user counts) and exploration diversity.
Federated Conversational Recommender System
Mar 02, 2025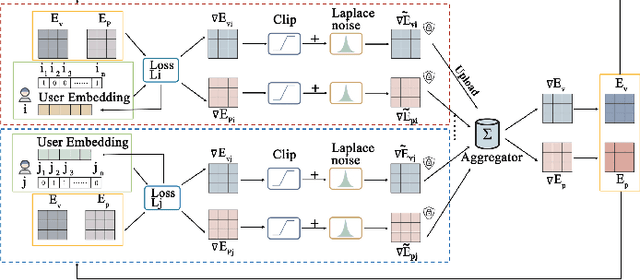
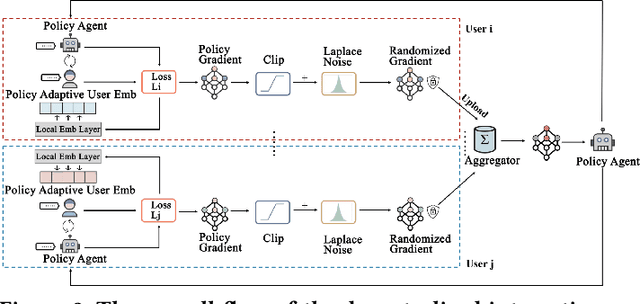

Conversational Recommender Systems (CRSs) have become increasingly popular as a powerful tool for providing personalized recommendation experiences. By directly engaging with users in a conversational manner to learn their current and fine-grained preferences, a CRS can quickly derive recommendations that are relevant and justifiable. However, existing conversational recommendation systems (CRSs) typically rely on a centralized training and deployment process, which involves collecting and storing explicitly-communicated user preferences in a centralized repository. These fine-grained user preferences are completely human-interpretable and can easily be used to infer sensitive information (e.g., financial status, political stands, and health information) about the user, if leaked or breached. To address the user privacy concerns in CRS, we first define a set of privacy protection guidelines for preserving user privacy under the conversational recommendation setting. Based on these guidelines, we propose a novel federated conversational recommendation framework that effectively reduces the risk of exposing user privacy by (i) de-centralizing both the historical interests estimation stage and the interactive preference elicitation stage and (ii) strictly bounding privacy leakage by enforcing user-level differential privacy with meticulously selected privacy budgets. Through extensive experiments, we show that the proposed framework not only satisfies these user privacy protection guidelines, but also enables the system to achieve competitive recommendation performance even when compared to the state-of-the-art non-private conversational recommendation approach.
Flow Matching for Collaborative Filtering
Feb 11, 2025Generative models have shown great promise in collaborative filtering by capturing the underlying distribution of user interests and preferences. However, existing approaches struggle with inaccurate posterior approximations and misalignment with the discrete nature of recommendation data, limiting their expressiveness and real-world performance. To address these limitations, we propose FlowCF, a novel flow-based recommendation system leveraging flow matching for collaborative filtering. We tailor flow matching to the unique challenges in recommendation through two key innovations: (1) a behavior-guided prior that aligns with user behavior patterns to handle the sparse and heterogeneous user-item interactions, and (2) a discrete flow framework to preserve the binary nature of implicit feedback while maintaining the benefits of flow matching, such as stable training and efficient inference. Extensive experiments demonstrate that FlowCF achieves state-of-the-art recommendation accuracy across various datasets with the fastest inference speed, making it a compelling approach for real-world recommender systems.
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Jan 03, 2025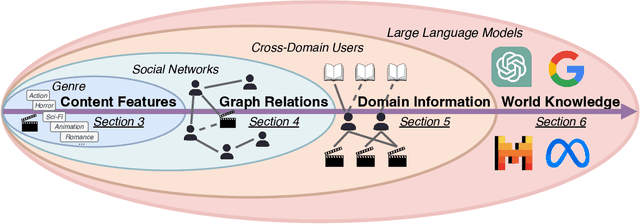
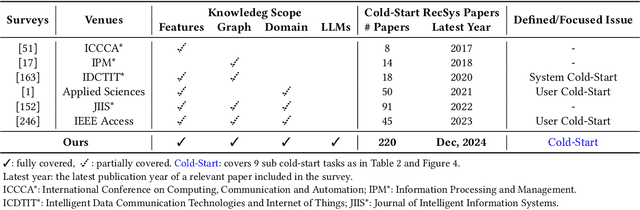
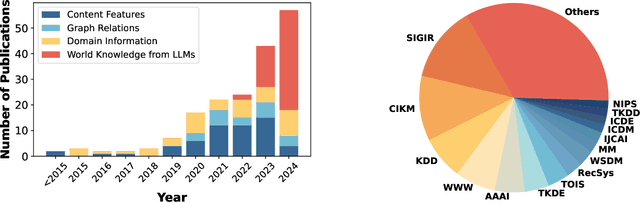
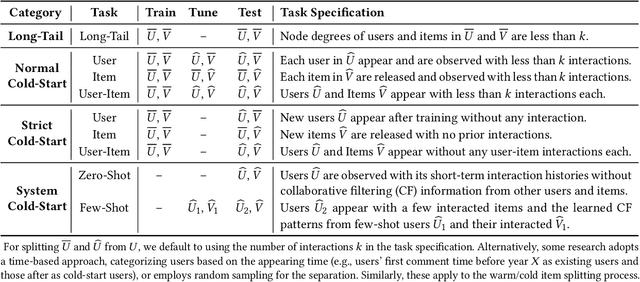
Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both the research and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.
SGSST: Scaling Gaussian Splatting StyleTransfer
Dec 04, 2024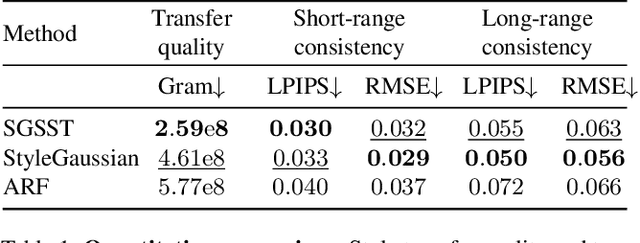
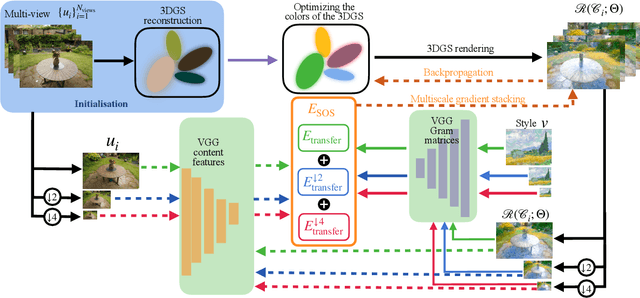


Applying style transfer to a full 3D environment is a challenging task that has seen many developments since the advent of neural rendering. 3D Gaussian splatting (3DGS) has recently pushed further many limits of neural rendering in terms of training speed and reconstruction quality. This work introduces SGSST: Scaling Gaussian Splatting Style Transfer, an optimization-based method to apply style transfer to pretrained 3DGS scenes. We demonstrate that a new multiscale loss based on global neural statistics, that we name SOS for Simultaneously Optimized Scales, enables style transfer to ultra-high resolution 3D scenes. Not only SGSST pioneers 3D scene style transfer at such high image resolutions, it also produces superior visual quality as assessed by thorough qualitative, quantitative and perceptual comparisons.
TwinCL: A Twin Graph Contrastive Learning Model for Collaborative Filtering
Sep 27, 2024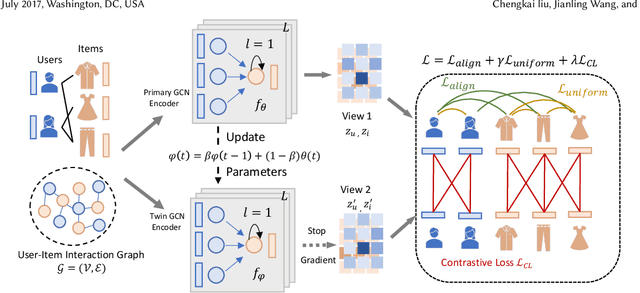
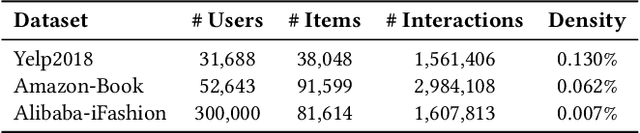
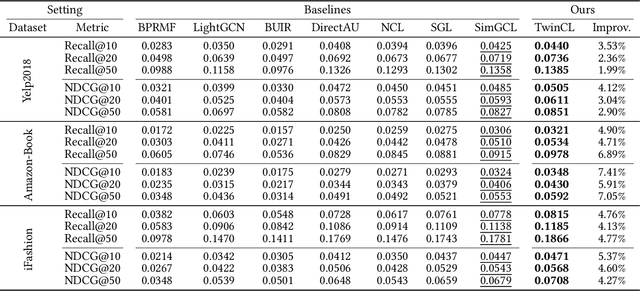
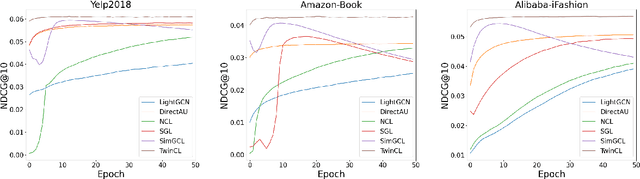
In the domain of recommendation and collaborative filtering, Graph Contrastive Learning (GCL) has become an influential approach. Nevertheless, the reasons for the effectiveness of contrastive learning are still not well understood. In this paper, we challenge the conventional use of random augmentations on graph structure or embedding space in GCL, which may disrupt the structural and semantic information inherent in Graph Neural Networks. Moreover, fixed-rate data augmentation proves to be less effective compared to augmentation with an adaptive rate. In the initial training phases, significant perturbations are more suitable, while as the training approaches convergence, milder perturbations yield better results. We introduce a twin encoder in place of random augmentations, demonstrating the redundancy of traditional augmentation techniques. The twin encoder updating mechanism ensures the generation of more diverse contrastive views in the early stages, transitioning to views with greater similarity as training progresses. In addition, we investigate the learned representations from the perspective of alignment and uniformity on a hypersphere to optimize more efficiently. Our proposed Twin Graph Contrastive Learning model -- TwinCL -- aligns positive pairs of user and item embeddings and the representations from the twin encoder while maintaining the uniformity of the embeddings on the hypersphere. Our theoretical analysis and experimental results show that the proposed model optimizing alignment and uniformity with the twin encoder contributes to better recommendation accuracy and training efficiency performance. In comprehensive experiments on three public datasets, our proposed TwinCL achieves an average improvement of 5.6% (NDCG@10) in recommendation accuracy with faster training speed, while effectively mitigating popularity bias.
Behavior-Dependent Linear Recurrent Units for Efficient Sequential Recommendation
Jun 18, 2024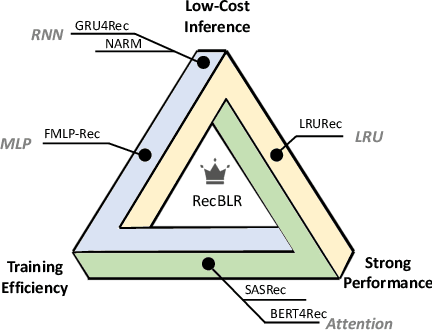
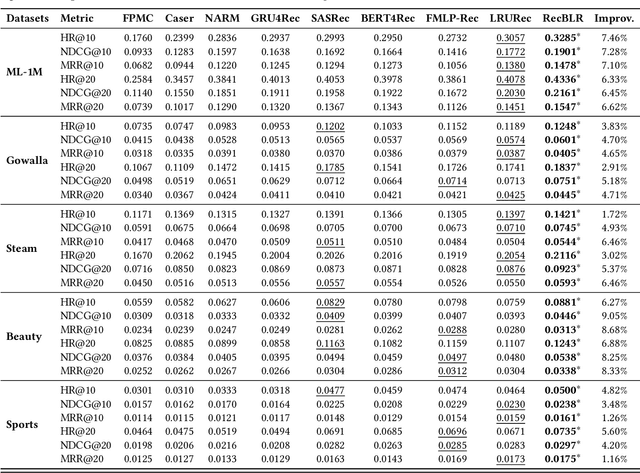
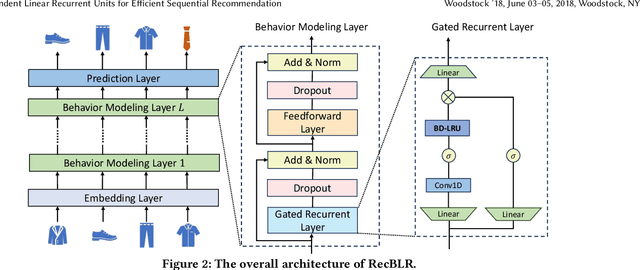
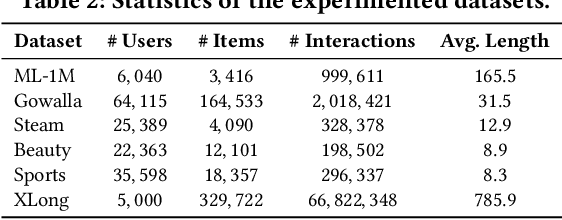
Sequential recommender systems aims to predict the users' next interaction through user behavior modeling with various operators like RNNs and attentions. However, existing models generally fail to achieve the three golden principles for sequential recommendation simultaneously, i.e., training efficiency, low-cost inference, and strong performance. To this end, we propose RecBLR, an Efficient Sequential Recommendation Model based on Behavior-Dependent Linear Recurrent Units to accomplish the impossible triangle of the three principles. By incorporating gating mechanisms and behavior-dependent designs into linear recurrent units, our model significantly enhances user behavior modeling and recommendation performance. Furthermore, we unlock the parallelizable training as well as inference efficiency for our model by designing a hardware-aware scanning acceleration algorithm with a customized CUDA kernel. Extensive experiments on real-world datasets with varying lengths of user behavior sequences demonstrate RecBLR's remarkable effectiveness in simultaneously achieving all three golden principles - strong recommendation performance, training efficiency, and low-cost inference, while exhibiting excellent scalability to datasets with long user interaction histories.
LLMs for User Interest Exploration: A Hybrid Approach
May 25, 2024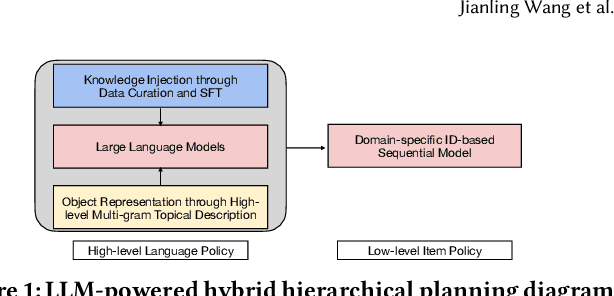

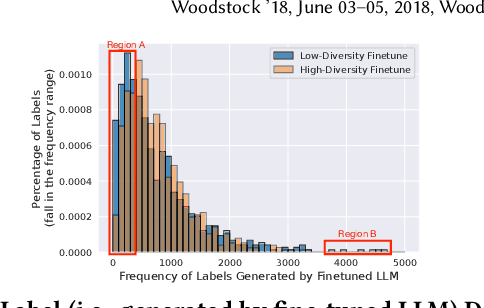
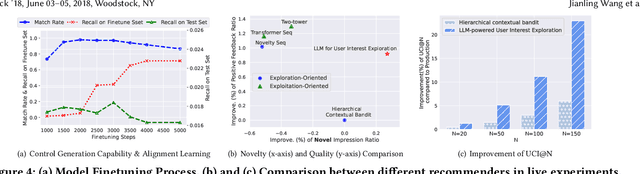
Traditional recommendation systems are subject to a strong feedback loop by learning from and reinforcing past user-item interactions, which in turn limits the discovery of novel user interests. To address this, we introduce a hybrid hierarchical framework combining Large Language Models (LLMs) and classic recommendation models for user interest exploration. The framework controls the interfacing between the LLMs and the classic recommendation models through "interest clusters", the granularity of which can be explicitly determined by algorithm designers. It recommends the next novel interests by first representing "interest clusters" using language, and employs a fine-tuned LLM to generate novel interest descriptions that are strictly within these predefined clusters. At the low level, it grounds these generated interests to an item-level policy by restricting classic recommendation models, in this case a transformer-based sequence recommender to return items that fall within the novel clusters generated at the high level. We showcase the efficacy of this approach on an industrial-scale commercial platform serving billions of users. Live experiments show a significant increase in both exploration of novel interests and overall user enjoyment of the platform.
Empowering Large Language Models for Textual Data Augmentation
Apr 26, 2024



With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.