 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Feedback Alignment for LLM-powered Exploration in Large-scale Recommendation Systems
Apr 07, 2025Exploration, the act of broadening user experiences beyond their established preferences, is challenging in large-scale recommendation systems due to feedback loops and limited signals on user exploration patterns. Large Language Models (LLMs) offer potential by leveraging their world knowledge to recommend novel content outside these loops. A key challenge is aligning LLMs with user preferences while preserving their knowledge and reasoning. While using LLMs to plan for the next novel user interest, this paper introduces a novel approach combining hierarchical planning with LLM inference-time scaling to improve recommendation relevancy without compromising novelty. We decouple novelty and user-alignment, training separate LLMs for each objective. We then scale up the novelty-focused LLM's inference and select the best-of-n predictions using the user-aligned LLM. Live experiments demonstrate efficacy, showing significant gains in both user satisfaction (measured by watch activity and active user counts) and exploration diversity.
BaLeNAS: Differentiable Architecture Search via the Bayesian Learning Rule
Nov 25, 2021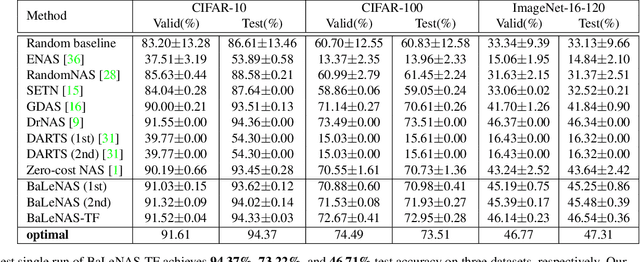
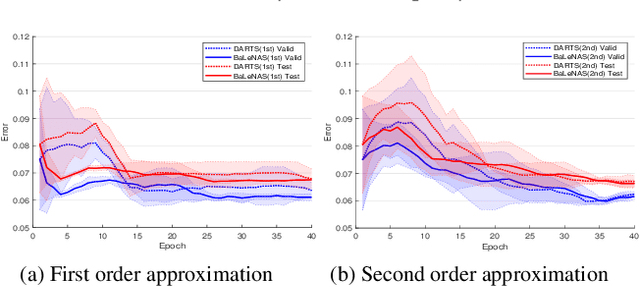
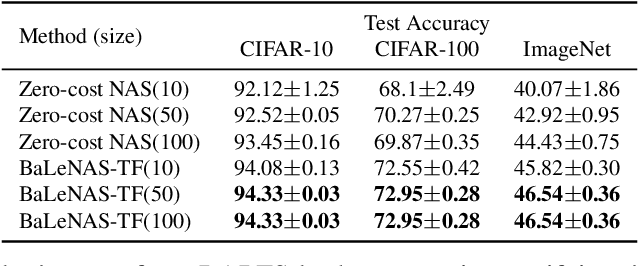
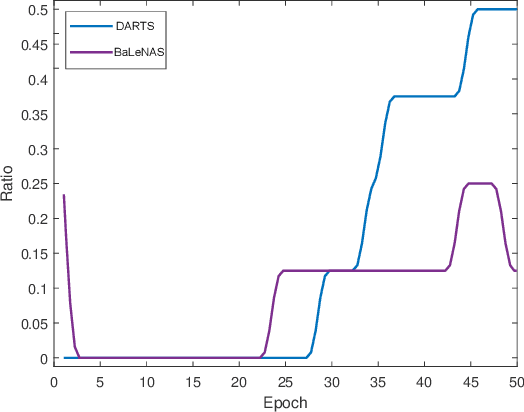
Differentiable Architecture Search (DARTS) has received massive attention in recent years, mainly because it significantly reduces the computational cost through weight sharing and continuous relaxation. However, more recent works find that existing differentiable NAS techniques struggle to outperform naive baselines, yielding deteriorative architectures as the search proceeds. Rather than directly optimizing the architecture parameters, this paper formulates the neural architecture search as a distribution learning problem through relaxing the architecture weights into Gaussian distributions. By leveraging the natural-gradient variational inference (NGVI), the architecture distribution can be easily optimized based on existing codebases without incurring more memory and computational consumption. We demonstrate how the differentiable NAS benefits from Bayesian principles, enhancing exploration and improving stability. The experimental results on NAS-Bench-201 and NAS-Bench-1shot1 benchmark datasets confirm the significant improvements the proposed framework can make. In addition, instead of simply applying the argmax on the learned parameters, we further leverage the recently-proposed training-free proxies in NAS to select the optimal architecture from a group architectures drawn from the optimized distribution, where we achieve state-of-the-art results on the NAS-Bench-201 and NAS-Bench-1shot1 benchmarks. Our best architecture in the DARTS search space also obtains competitive test errors with 2.37\%, 15.72\%, and 24.2\% on CIFAR-10, CIFAR-100, and ImageNet datasets, respectively.
Differentiable Architecture Search Without Training Nor Labels: A Pruning Perspective
Jun 22, 2021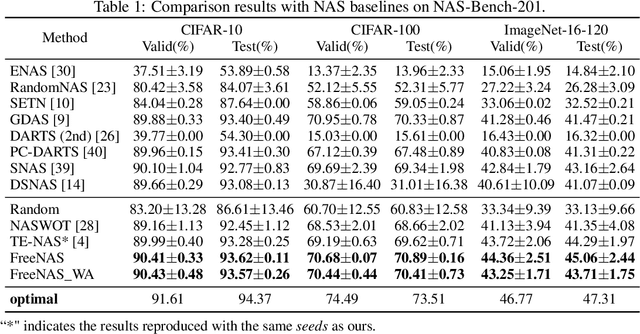
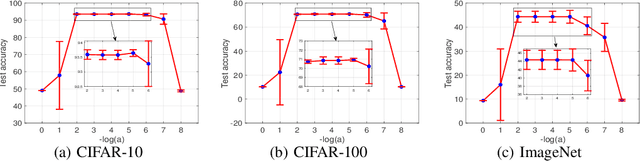
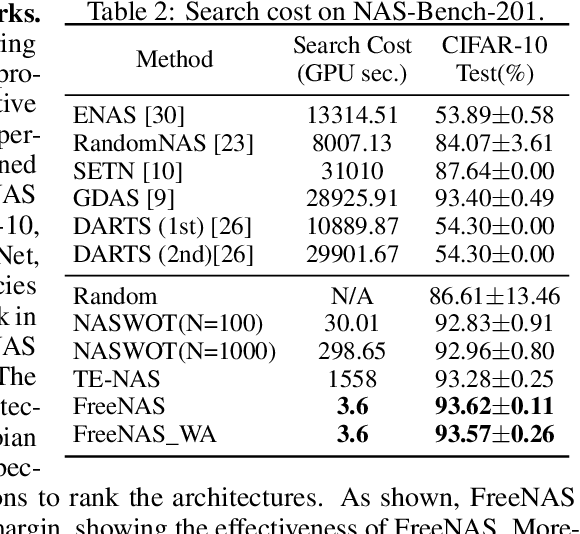
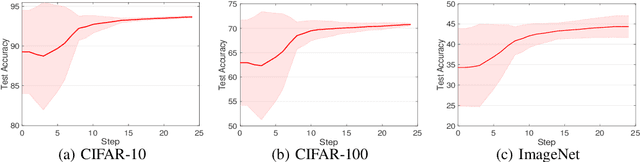
With leveraging the weight-sharing and continuous relaxation to enable gradient-descent to alternately optimize the supernet weights and the architecture parameters through a bi-level optimization paradigm, \textit{Differentiable ARchiTecture Search} (DARTS) has become the mainstream method in Neural Architecture Search (NAS) due to its simplicity and efficiency. However, more recent works found that the performance of the searched architecture barely increases with the optimization proceeding in DARTS. In addition, several concurrent works show that the NAS could find more competitive architectures without labels. The above observations reveal that the supervision signal in DARTS may be a poor indicator for architecture optimization, inspiring a foundational question: instead of using the supervision signal to perform bi-level optimization, \textit{can we find high-quality architectures \textbf{without any training nor labels}}? We provide an affirmative answer by customizing the NAS as a network pruning at initialization problem. By leveraging recent techniques on the network pruning at initialization, we designed a FreeFlow proxy to score the importance of candidate operations in NAS without any training nor labels, and proposed a novel framework called \textit{training and label free neural architecture search} (\textbf{FreeNAS}) accordingly. We show that, without any training nor labels, FreeNAS with the proposed FreeFlow proxy can outperform most NAS baselines. More importantly, our framework is extremely efficient, which completes the architecture search within only \textbf{3.6s} and \textbf{79s} on a single GPU for the NAS-Bench-201 and DARTS search space, respectively. We hope our work inspires more attempts in solving NAS from the perspective of pruning at initialization.
iDARTS: Differentiable Architecture Search with Stochastic Implicit Gradients
Jun 21, 2021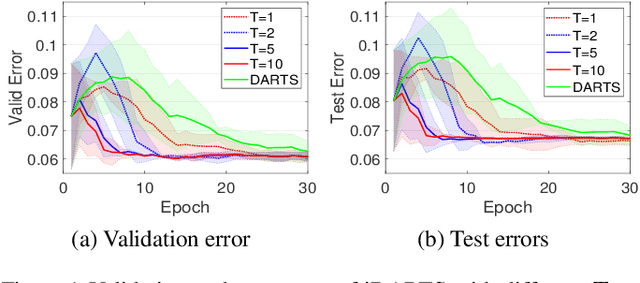
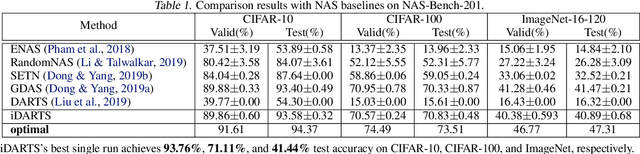
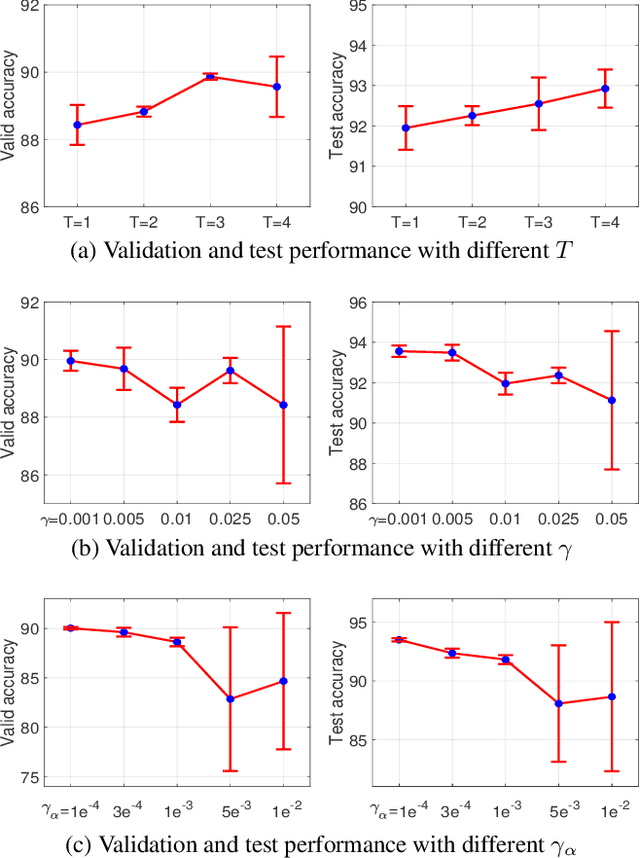
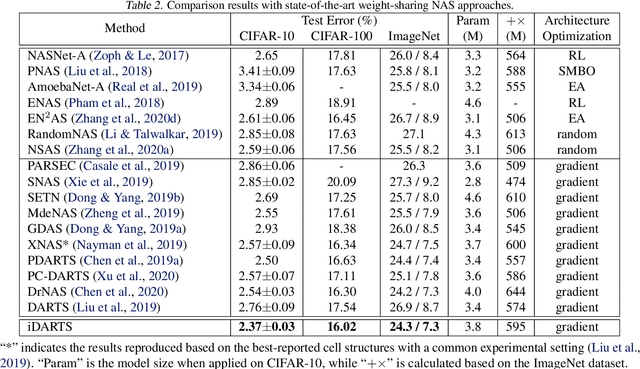
\textit{Differentiable ARchiTecture Search} (DARTS) has recently become the mainstream of neural architecture search (NAS) due to its efficiency and simplicity. With a gradient-based bi-level optimization, DARTS alternately optimizes the inner model weights and the outer architecture parameter in a weight-sharing supernet. A key challenge to the scalability and quality of the learned architectures is the need for differentiating through the inner-loop optimisation. While much has been discussed about several potentially fatal factors in DARTS, the architecture gradient, a.k.a. hypergradient, has received less attention. In this paper, we tackle the hypergradient computation in DARTS based on the implicit function theorem, making it only depends on the obtained solution to the inner-loop optimization and agnostic to the optimization path. To further reduce the computational requirements, we formulate a stochastic hypergradient approximation for differentiable NAS, and theoretically show that the architecture optimization with the proposed method, named iDARTS, is expected to converge to a stationary point. Comprehensive experiments on two NAS benchmark search spaces and the common NAS search space verify the effectiveness of our proposed method. It leads to architectures outperforming, with large margins, those learned by the baseline methods.
An Efficient Calibration Method for Triaxial Gyroscope
Mar 20, 2021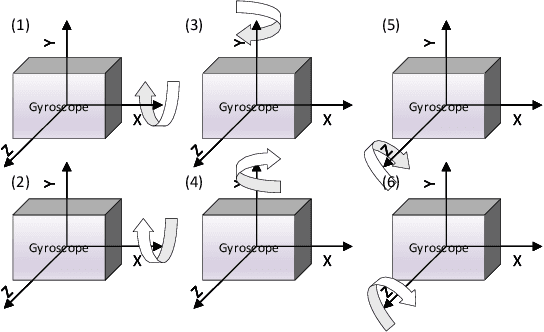
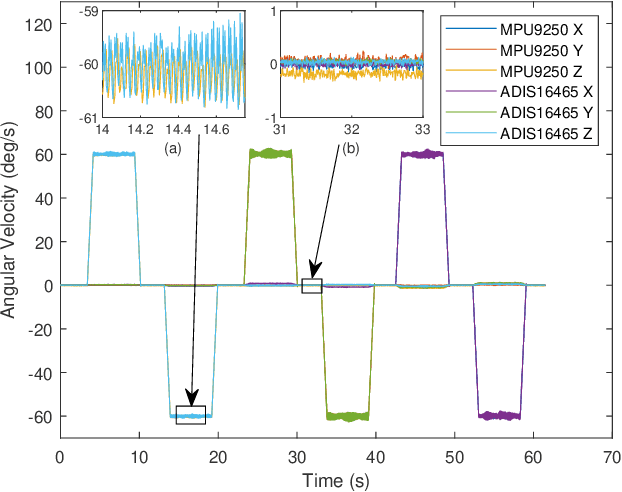
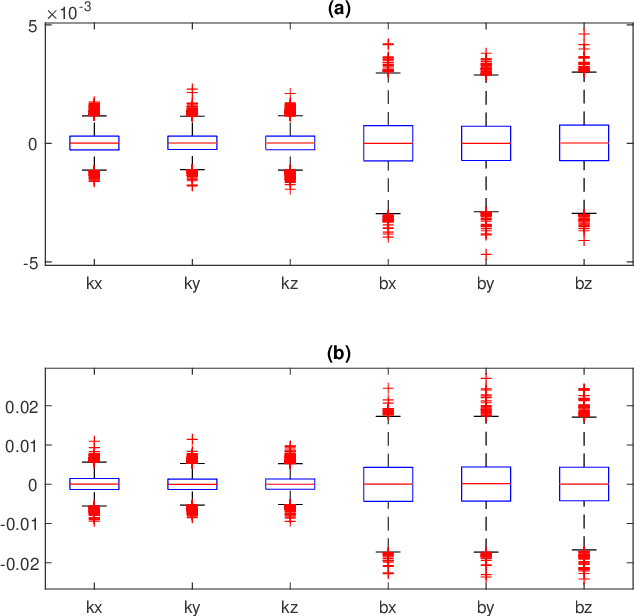
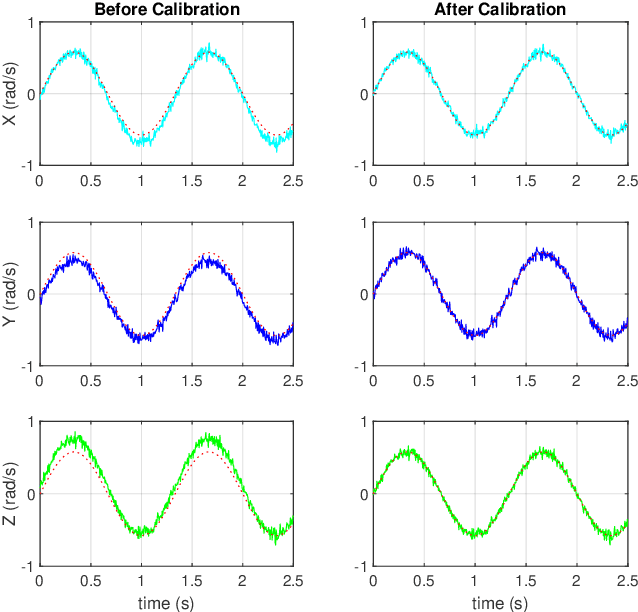
This paper presents an efficient servomotor-aided calibration method for the triaxial gyroscope. The entire calibration process only takes about one minute, and high-precision equipment is not used. The main idea of this method is that the measurement of the gyroscope should equal to the rotation speed of the servomotor. A six-observation experimental design is proposed to minimize the maximum variance of the estimated scale factors and biases. Besides, a fast converged recursive linear least square estimation method is presented to reduce computational complexity. The simulation results specify the robustness under normal and extreme condition. We experimentally demonstrate the achievability of the proposed method on a robot arm and implements the method on a microcontroller. The calibration results of the proposed method are verified by comparing with a traditional turntable method, and the experiment indicates that the error between these two methods is less than $10^{-3}$. By comparing the calibrated low-cost gyroscope reading with the reading from a high-precision gyroscope, we can infer that our method significantly increases the accuracy of the low-cost gyroscopes.
Efficient Novelty-Driven Neural Architecture Search
Jul 22, 2019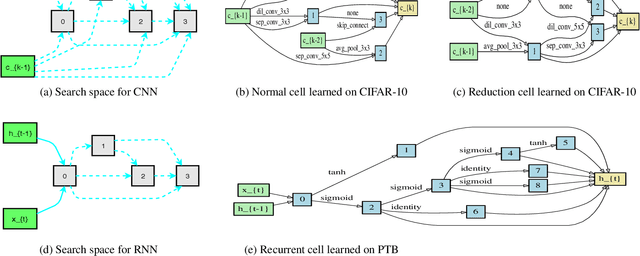
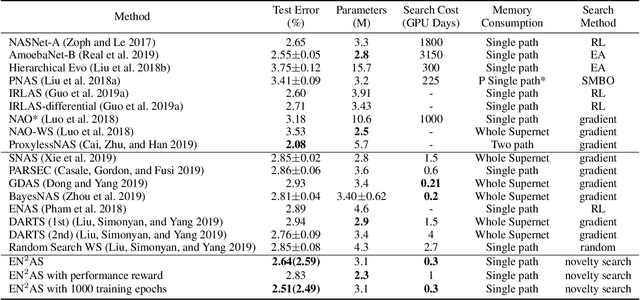


One-Shot Neural architecture search (NAS) attracts broad attention recently due to its capacity to reduce the computational hours through weight sharing. However, extensive experiments on several recent works show that there is no positive correlation between the validation accuracy with inherited weights from the supernet and the test accuracy after re-training for One-Shot NAS. Different from devising a controller to find the best performing architecture with inherited weights, this paper focuses on how to sample architectures to train the supernet to make it more predictive. A single-path supernet is adopted, where only a small part of weights are optimized in each step, to reduce the memory demand greatly. Furthermore, we abandon devising complicated reward based architecture sampling controller, and sample architectures to train supernet based on novelty search. An efficient novelty search method for NAS is devised in this paper, and extensive experiments demonstrate the effectiveness and efficiency of our novelty search based architecture sampling method. The best architecture obtained by our algorithm with the same search space achieves the state-of-the-art test error rate of 2.51\% on CIFAR-10 with only 7.5 hours search time in a single GPU, and a validation perplexity of 60.02 and a test perplexity of 57.36 on PTB. We also transfer these search cell structures to larger datasets ImageNet and WikiText-2, respectively.
High Dimensional Bayesian Optimization via Supervised Dimension Reduction
Jul 21, 2019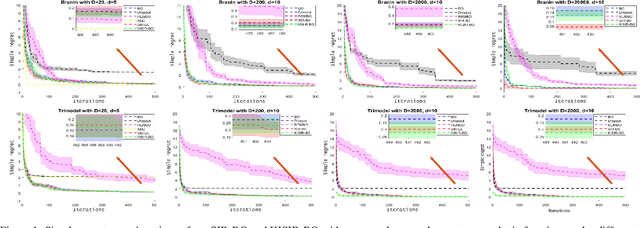
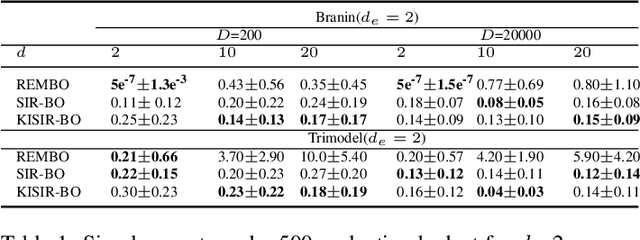
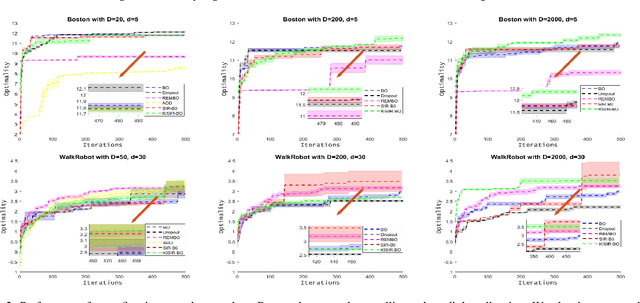
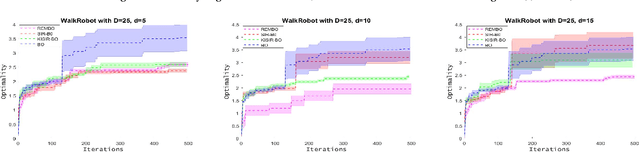
Bayesian optimization (BO) has been broadly applied to computational expensive problems, but it is still challenging to extend BO to high dimensions. Existing works are usually under strict assumption of an additive or a linear embedding structure for objective functions. This paper directly introduces a supervised dimension reduction method, Sliced Inverse Regression (SIR), to high dimensional Bayesian optimization, which could effectively learn the intrinsic sub-structure of objective function during the optimization. Furthermore, a kernel trick is developed to reduce computational complexity and learn nonlinear subset of the unknowing function when applying SIR to extremely high dimensional BO. We present several computational benefits and derive theoretical regret bounds of our algorithm. Extensive experiments on synthetic examples and two real applications demonstrate the superiority of our algorithms for high dimensional Bayesian optimization.
Multi-level CNN for lung nodule classification with Gaussian Process assisted hyperparameter optimization
Jan 02, 2019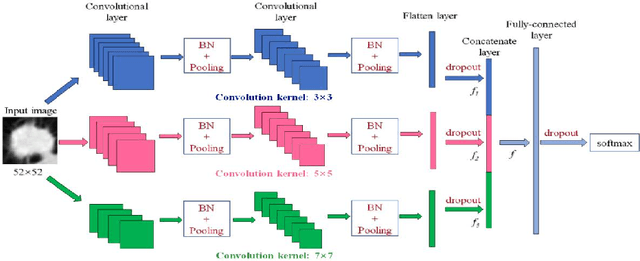


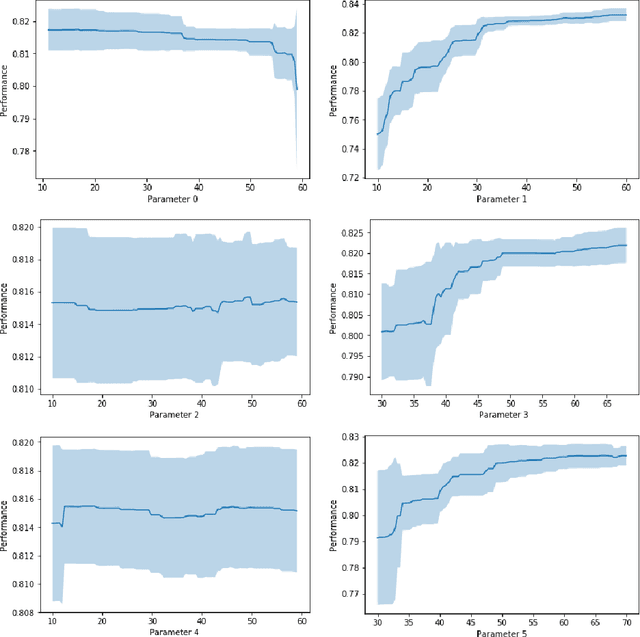
This paper investigates lung nodule classification by using deep neural networks (DNNs). Hyperparameter optimization in DNNs is a computationally expensive problem, where evaluating a hyperparameter configuration may take several hours or even days. Bayesian optimization has been recently introduced for the automatically searching of optimal hyperparameter configurations of DNNs. It applies probabilistic surrogate models to approximate the validation error function of hyperparameter configurations, such as Gaussian processes, and reduce the computational complexity to a large extent. However, most existing surrogate models adopt stationary covariance functions to measure the difference between hyperparameter points based on spatial distance without considering its spatial locations. This distance-based assumption together with the condition of constant smoothness throughout the whole hyperparameter search space clearly violates the property that the points far away from optimal points usually get similarly poor performance even though each two of them have huge spatial distance between them. In this paper, a non-stationary kernel is proposed which allows the surrogate model to adapt to functions whose smoothness varies with the spatial location of inputs, and a multi-level convolutional neural network (ML-CNN) is built for lung nodule classification whose hyperparameter configuration is optimized by using the proposed non-stationary kernel based Gaussian surrogate model. Our algorithm searches the surrogate for optimal setting via hyperparameter importance based evolutionary strategy, and the experiments demonstrate our algorithm outperforms manual tuning and well-established hyperparameter optimization methods such as Random search, Gaussian processes with stationary kernels, and recently proposed Hyperparameter Optimization via RBF and Dynamic coordinate search.