 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Dimensional Bayesian Optimization via Supervised Dimension Reduction
Paper and Code
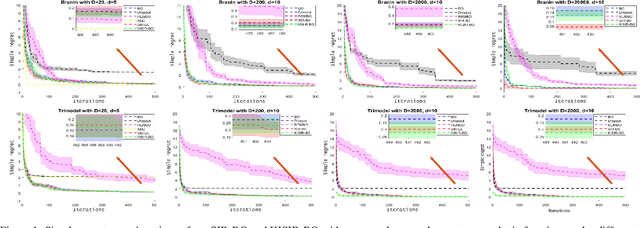
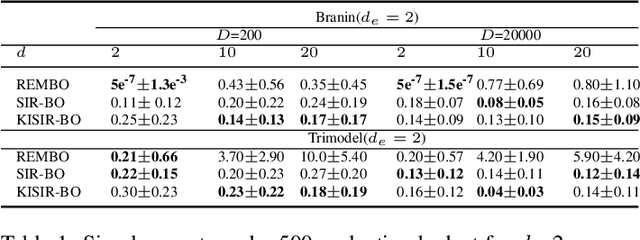
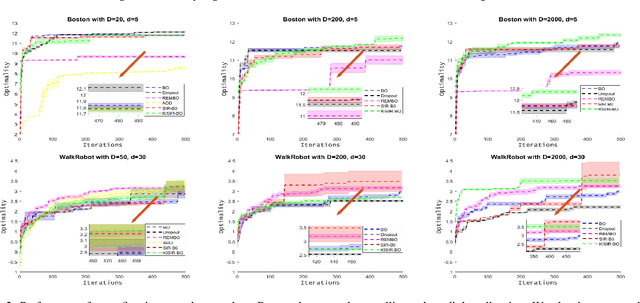
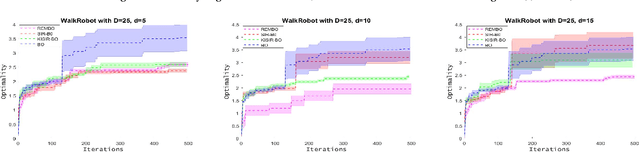
Bayesian optimization (BO) has been broadly applied to computational expensive problems, but it is still challenging to extend BO to high dimensions. Existing works are usually under strict assumption of an additive or a linear embedding structure for objective functions. This paper directly introduces a supervised dimension reduction method, Sliced Inverse Regression (SIR), to high dimensional Bayesian optimization, which could effectively learn the intrinsic sub-structure of objective function during the optimization. Furthermore, a kernel trick is developed to reduce computational complexity and learn nonlinear subset of the unknowing function when applying SIR to extremely high dimensional BO. We present several computational benefits and derive theoretical regret bounds of our algorithm. Extensive experiments on synthetic examples and two real applications demonstrate the superiority of our algorithms for high dimensional Bayesian optimization.