 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAD: Layer-wise Expert-aligned Decoding for Faithful Radiology Report Generation
Feb 04, 2026Radiology Report Generation (RRG) aims to produce accurate and coherent diagnostics from medical images. Although large vision language models (LVLM) improve report fluency and accuracy, they exhibit hallucinations, generating plausible yet image-ungrounded pathological details. Existing methods primarily rely on external knowledge guidance to facilitate the alignment between generated text and visual information. However, these approaches often ignore the inherent decoding priors and vision-language alignment biases in pretrained models and lack robustness due to reliance on constructed guidance. In this paper, we propose Layer-wise Expert-aligned Decoding (LEAD), a novel method to inherently modify the LVLM decoding trajectory. A multiple experts module is designed for extracting distinct pathological features which are integrated into each decoder layer via a gating mechanism. This layer-wise architecture enables the LLM to consult expert features at every inference step via a learned gating function, thereby dynamically rectifying decoding biases and steering the generation toward factual consistency. Experiments conducted on multiple public datasets demonstrate that the LEAD method yields effective improvements in clinical accuracy metrics and mitigates hallucinations while preserving high generation quality.
Native Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
CLIPin: A Non-contrastive Plug-in to CLIP for Multimodal Semantic Alignment
Aug 08, 2025Large-scale natural image-text datasets, especially those automatically collected from the web, often suffer from loose semantic alignment due to weak supervision, while medical datasets tend to have high cross-modal correlation but low content diversity. These properties pose a common challenge for contrastive language-image pretraining (CLIP): they hinder the model's ability to learn robust and generalizable representations. In this work, we propose CLIPin, a unified non-contrastive plug-in that can be seamlessly integrated into CLIP-style architectures to improve multimodal semantic alignment, providing stronger supervision and enhancing alignment robustness. Furthermore, two shared pre-projectors are designed for image and text modalities respectively to facilitate the integration of contrastive and non-contrastive learning in a parameter-compromise manner. Extensive experiments on diverse downstream tasks demonstrate the effectiveness and generality of CLIPin as a plug-and-play component compatible with various contrastive frameworks. Code is available at https://github.com/T6Yang/CLIPin.
LazyMAR: Accelerating Masked Autoregressive Models via Feature Caching
Mar 16, 2025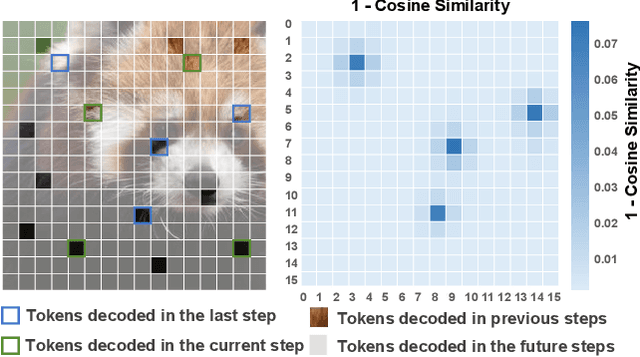
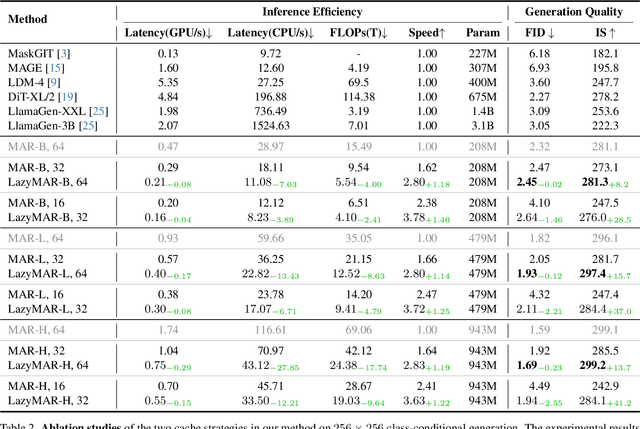
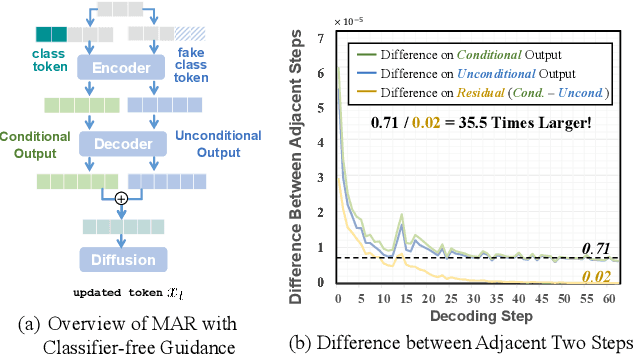

Masked Autoregressive (MAR) models have emerged as a promising approach in image generation, expected to surpass traditional autoregressive models in computational efficiency by leveraging the capability of parallel decoding. However, their dependence on bidirectional self-attention inherently conflicts with conventional KV caching mechanisms, creating unexpected computational bottlenecks that undermine their expected efficiency. To address this problem, this paper studies the caching mechanism for MAR by leveraging two types of redundancy: Token Redundancy indicates that a large portion of tokens have very similar representations in the adjacent decoding steps, which allows us to first cache them in previous steps and then reuse them in the later steps. Condition Redundancy indicates that the difference between conditional and unconditional output in classifier-free guidance exhibits very similar values in adjacent steps. Based on these two redundancies, we propose LazyMAR, which introduces two caching mechanisms to handle them one by one. LazyMAR is training-free and plug-and-play for all MAR models. Experimental results demonstrate that our method achieves 2.83 times acceleration with almost no drop in generation quality. Our codes will be released in https://github.com/feihongyan1/LazyMAR.
RetSTA: An LLM-Based Approach for Standardizing Clinical Fundus Image Reports
Mar 12, 2025Standardization of clinical reports is crucial for improving the quality of healthcare and facilitating data integration. The lack of unified standards, including format, terminology, and style, is a great challenge in clinical fundus diagnostic reports, which increases the difficulty for large language models (LLMs) to understand the data. To address this, we construct a bilingual standard terminology, containing fundus clinical terms and commonly used descriptions in clinical diagnosis. Then, we establish two models, RetSTA-7B-Zero and RetSTA-7B. RetSTA-7B-Zero, fine-tuned on an augmented dataset simulating clinical scenarios, demonstrates powerful standardization behaviors. However, it encounters a challenge of limitation to cover a wider range of diseases. To further enhance standardization performance, we build RetSTA-7B, which integrates a substantial amount of standardized data generated by RetSTA-7B-Zero along with corresponding English data, covering diverse complex clinical scenarios and achieving report-level standardization for the first time. Experimental results demonstrate that RetSTA-7B outperforms other compared LLMs in bilingual standardization task, which validates its superior performance and generalizability. The checkpoints are available at https://github.com/AB-Story/RetSTA-7B.
ViLReF: A Chinese Vision-Language Retinal Foundation Model
Aug 20, 2024



Subtle semantic differences in retinal image and text data present great challenges for pre-training visual-language models. Moreover, false negative samples, i.e., image-text pairs having the same semantics but incorrectly regarded as negatives, disrupt the visual-language pre-training process and affect the model's learning ability. This work aims to develop a retinal foundation model, called ViLReF, by pre-training on a paired dataset comprising 451,956 retinal images and corresponding diagnostic text reports. In our vision-language pre-training strategy, we leverage expert knowledge to facilitate the extraction of labels and propose a novel constraint, the Weighted Similarity Coupling Loss, to adjust the speed of pushing sample pairs further apart dynamically within the feature space. Furthermore, we employ a batch expansion module with dynamic memory queues, maintained by momentum encoders, to supply extra samples and compensate for the vacancies caused by eliminating false negatives. Extensive experiments are conducted on multiple datasets for downstream classification and segmentation tasks. The experimental results demonstrate the powerful zero-shot and transfer learning capabilities of ViLReF, verifying the effectiveness of our pre-training strategy. Our ViLReF model is available at: https://github.com/T6Yang/ViLReF.
Dinomaly: The Less Is More Philosophy in Multi-Class Unsupervised Anomaly Detection
May 23, 2024Recent studies highlighted a practical setting of unsupervised anomaly detection (UAD) that builds a unified model for multi-class images, serving as an alternative to the conventional one-class-one-model setup. Despite various advancements addressing this challenging task, the detection performance under the multi-class setting still lags far behind state-of-the-art class-separated models. Our research aims to bridge this substantial performance gap. In this paper, we introduce a minimalistic reconstruction-based anomaly detection framework, namely Dinomaly, which leverages pure Transformer architectures without relying on complex designs, additional modules, or specialized tricks. Given this powerful framework consisted of only Attentions and MLPs, we found four simple components that are essential to multi-class anomaly detection: (1) Foundation Transformers that extracts universal and discriminative features, (2) Noisy Bottleneck where pre-existing Dropouts do all the noise injection tricks, (3) Linear Attention that naturally cannot focus, and (4) Loose Reconstruction that does not force layer-to-layer and point-by-point reconstruction. Extensive experiments are conducted across three popular anomaly detection benchmarks including MVTec-AD, VisA, and the recently released Real-IAD. Our proposed Dinomaly achieves impressive image AUROC of 99.6%, 98.7%, and 89.3% on the three datasets respectively, which is not only superior to state-of-the-art multi-class UAD methods, but also surpasses the most advanced class-separated UAD records.
RET-CLIP: A Retinal Image Foundation Model Pre-trained with Clinical Diagnostic Reports
May 23, 2024The Vision-Language Foundation model is increasingly investigated in the fields of computer vision and natural language processing, yet its exploration in ophthalmology and broader medical applications remains limited. The challenge is the lack of labeled data for the training of foundation model. To handle this issue, a CLIP-style retinal image foundation model is developed in this paper. Our foundation model, RET-CLIP, is specifically trained on a dataset of 193,865 patients to extract general features of color fundus photographs (CFPs), employing a tripartite optimization strategy to focus on left eye, right eye, and patient level to reflect real-world clinical scenarios. Extensive experiments demonstrate that RET-CLIP outperforms existing benchmarks across eight diverse datasets spanning four critical diagnostic categories: diabetic retinopathy, glaucoma, multiple disease diagnosis, and multi-label classification of multiple diseases, which demonstrate the performance and generality of our foundation model. The sourse code and pre-trained model are available at https://github.com/sStonemason/RET-CLIP.
Absolute-Unified Multi-Class Anomaly Detection via Class-Agnostic Distribution Alignment
Mar 31, 2024Conventional unsupervised anomaly detection (UAD) methods build separate models for each object category. Recent studies have proposed to train a unified model for multiple classes, namely model-unified UAD. However, such methods still implement the unified model separately on each class during inference with respective anomaly decision thresholds, which hinders their application when the image categories are entirely unavailable. In this work, we present a simple yet powerful method to address multi-class anomaly detection without any class information, namely \textit{absolute-unified} UAD. We target the crux of prior works in this challenging setting: different objects have mismatched anomaly score distributions. We propose Class-Agnostic Distribution Alignment (CADA) to align the mismatched score distribution of each implicit class without knowing class information, which enables unified anomaly detection for all classes and samples. The essence of CADA is to predict each class's score distribution of normal samples given any image, normal or anomalous, of this class. As a general component, CADA can activate the potential of nearly all UAD methods under absolute-unified setting. Our approach is extensively evaluated under the proposed setting on two popular UAD benchmark datasets, MVTec AD and VisA, where we exceed previous state-of-the-art by a large margin.
ReContrast: Domain-Specific Anomaly Detection via Contrastive Reconstruction
Jun 05, 2023



Most advanced unsupervised anomaly detection (UAD) methods rely on modeling feature representations of frozen encoder networks pre-trained on large-scale datasets, e.g. ImageNet. However, the features extracted from the encoders that are borrowed from natural image domains coincide little with the features required in the target UAD domain, such as industrial inspection and medical imaging. In this paper, we propose a novel epistemic UAD method, namely ReContrast, which optimizes the entire network to reduce biases towards the pre-trained image domain and orients the network in the target domain. We start with a feature reconstruction approach that detects anomalies from errors. Essentially, the elements of contrastive learning are elegantly embedded in feature reconstruction to prevent the network from training instability, pattern collapse, and identical shortcut, while simultaneously optimizing both the encoder and decoder on the target domain. To demonstrate our transfer ability on various image domains, we conduct extensive experiments across two popular industrial defect detection benchmarks and three medical image UAD tasks, which shows our superiority over current state-of-the-art methods.