 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
CLIPin: A Non-contrastive Plug-in to CLIP for Multimodal Semantic Alignment
Aug 08, 2025Large-scale natural image-text datasets, especially those automatically collected from the web, often suffer from loose semantic alignment due to weak supervision, while medical datasets tend to have high cross-modal correlation but low content diversity. These properties pose a common challenge for contrastive language-image pretraining (CLIP): they hinder the model's ability to learn robust and generalizable representations. In this work, we propose CLIPin, a unified non-contrastive plug-in that can be seamlessly integrated into CLIP-style architectures to improve multimodal semantic alignment, providing stronger supervision and enhancing alignment robustness. Furthermore, two shared pre-projectors are designed for image and text modalities respectively to facilitate the integration of contrastive and non-contrastive learning in a parameter-compromise manner. Extensive experiments on diverse downstream tasks demonstrate the effectiveness and generality of CLIPin as a plug-and-play component compatible with various contrastive frameworks. Code is available at https://github.com/T6Yang/CLIPin.
RetSTA: An LLM-Based Approach for Standardizing Clinical Fundus Image Reports
Mar 12, 2025Standardization of clinical reports is crucial for improving the quality of healthcare and facilitating data integration. The lack of unified standards, including format, terminology, and style, is a great challenge in clinical fundus diagnostic reports, which increases the difficulty for large language models (LLMs) to understand the data. To address this, we construct a bilingual standard terminology, containing fundus clinical terms and commonly used descriptions in clinical diagnosis. Then, we establish two models, RetSTA-7B-Zero and RetSTA-7B. RetSTA-7B-Zero, fine-tuned on an augmented dataset simulating clinical scenarios, demonstrates powerful standardization behaviors. However, it encounters a challenge of limitation to cover a wider range of diseases. To further enhance standardization performance, we build RetSTA-7B, which integrates a substantial amount of standardized data generated by RetSTA-7B-Zero along with corresponding English data, covering diverse complex clinical scenarios and achieving report-level standardization for the first time. Experimental results demonstrate that RetSTA-7B outperforms other compared LLMs in bilingual standardization task, which validates its superior performance and generalizability. The checkpoints are available at https://github.com/AB-Story/RetSTA-7B.
Wearable intelligent throat enables natural speech in stroke patients with dysarthria
Nov 28, 2024



Wearable silent speech systems hold significant potential for restoring communication in patients with speech impairments. However, seamless, coherent speech remains elusive, and clinical efficacy is still unproven. Here, we present an AI-driven intelligent throat (IT) system that integrates throat muscle vibrations and carotid pulse signal sensors with large language model (LLM) processing to enable fluent, emotionally expressive communication. The system utilizes ultrasensitive textile strain sensors to capture high-quality signals from the neck area and supports token-level processing for real-time, continuous speech decoding, enabling seamless, delay-free communication. In tests with five stroke patients with dysarthria, IT's LLM agents intelligently corrected token errors and enriched sentence-level emotional and logical coherence, achieving low error rates (4.2% word error rate, 2.9% sentence error rate) and a 55% increase in user satisfaction. This work establishes a portable, intuitive communication platform for patients with dysarthria with the potential to be applied broadly across different neurological conditions and in multi-language support systems.
ViLReF: A Chinese Vision-Language Retinal Foundation Model
Aug 20, 2024



Subtle semantic differences in retinal image and text data present great challenges for pre-training visual-language models. Moreover, false negative samples, i.e., image-text pairs having the same semantics but incorrectly regarded as negatives, disrupt the visual-language pre-training process and affect the model's learning ability. This work aims to develop a retinal foundation model, called ViLReF, by pre-training on a paired dataset comprising 451,956 retinal images and corresponding diagnostic text reports. In our vision-language pre-training strategy, we leverage expert knowledge to facilitate the extraction of labels and propose a novel constraint, the Weighted Similarity Coupling Loss, to adjust the speed of pushing sample pairs further apart dynamically within the feature space. Furthermore, we employ a batch expansion module with dynamic memory queues, maintained by momentum encoders, to supply extra samples and compensate for the vacancies caused by eliminating false negatives. Extensive experiments are conducted on multiple datasets for downstream classification and segmentation tasks. The experimental results demonstrate the powerful zero-shot and transfer learning capabilities of ViLReF, verifying the effectiveness of our pre-training strategy. Our ViLReF model is available at: https://github.com/T6Yang/ViLReF.
Deep Learning-Based Longitudinal Prediction of Childhood Myopia Progression Using Fundus Image Sequences and Baseline Refraction Data
Jul 31, 2024

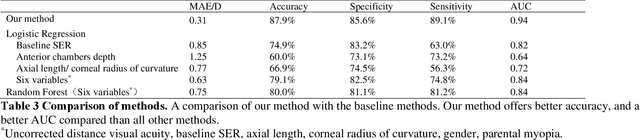
Childhood myopia constitutes a significant global health concern. It exhibits an escalating prevalence and has the potential to evolve into severe, irreversible conditions that detrimentally impact familial well-being and create substantial economic costs. Contemporary research underscores the importance of precisely predicting myopia progression to enable timely and effective interventions, thereby averting severe visual impairment in children. Such predictions predominantly rely on subjective clinical assessments, which are inherently biased and resource-intensive, thus hindering their widespread application. In this study, we introduce a novel, high-accuracy method for quantitatively predicting the myopic trajectory and myopia risk in children using only fundus images and baseline refraction data. This approach was validated through a six-year longitudinal study of 3,408 children in Henan, utilizing 16,211 fundus images and corresponding refractive data. Our method based on deep learning demonstrated predictive accuracy with an error margin of 0.311D per year and AUC scores of 0.944 and 0.995 for forecasting the risks of developing myopia and high myopia, respectively. These findings confirm the utility of our model in supporting early intervention strategies and in significantly reducing healthcare costs, particularly by obviating the need for additional metadata and repeated consultations. Furthermore, our method was designed to rely only on fundus images and refractive error data, without the need for meta data or multiple inquiries from doctors, strongly reducing the associated medical costs and facilitating large-scale screening. Our model can even provide good predictions based on only a single time measurement. Consequently, the proposed method is an important means to reduce medical inequities caused by economic disparities.
RET-CLIP: A Retinal Image Foundation Model Pre-trained with Clinical Diagnostic Reports
May 23, 2024The Vision-Language Foundation model is increasingly investigated in the fields of computer vision and natural language processing, yet its exploration in ophthalmology and broader medical applications remains limited. The challenge is the lack of labeled data for the training of foundation model. To handle this issue, a CLIP-style retinal image foundation model is developed in this paper. Our foundation model, RET-CLIP, is specifically trained on a dataset of 193,865 patients to extract general features of color fundus photographs (CFPs), employing a tripartite optimization strategy to focus on left eye, right eye, and patient level to reflect real-world clinical scenarios. Extensive experiments demonstrate that RET-CLIP outperforms existing benchmarks across eight diverse datasets spanning four critical diagnostic categories: diabetic retinopathy, glaucoma, multiple disease diagnosis, and multi-label classification of multiple diseases, which demonstrate the performance and generality of our foundation model. The sourse code and pre-trained model are available at https://github.com/sStonemason/RET-CLIP.
Diagnosis of Multiple Fundus Disorders Amidst a Scarcity of Medical Experts Via Self-supervised Machine Learning
Apr 23, 2024



Fundus diseases are major causes of visual impairment and blindness worldwide, especially in underdeveloped regions, where the shortage of ophthalmologists hinders timely diagnosis. AI-assisted fundus image analysis has several advantages, such as high accuracy, reduced workload, and improved accessibility, but it requires a large amount of expert-annotated data to build reliable models. To address this dilemma, we propose a general self-supervised machine learning framework that can handle diverse fundus diseases from unlabeled fundus images. Our method's AUC surpasses existing supervised approaches by 15.7%, and even exceeds performance of a single human expert. Furthermore, our model adapts well to various datasets from different regions, races, and heterogeneous image sources or qualities from multiple cameras or devices. Our method offers a label-free general framework to diagnose fundus diseases, which could potentially benefit telehealth programs for early screening of people at risk of vision loss.
SSVT: Self-Supervised Vision Transformer For Eye Disease Diagnosis Based On Fundus Images
Apr 20, 2024

Machine learning-based fundus image diagnosis technologies trigger worldwide interest owing to their benefits such as reducing medical resource power and providing objective evaluation results. However, current methods are commonly based on supervised methods, bringing in a heavy workload to biomedical staff and hence suffering in expanding effective databases. To address this issue, in this article, we established a label-free method, name 'SSVT',which can automatically analyze un-labeled fundus images and generate high evaluation accuracy of 97.0% of four main eye diseases based on six public datasets and two datasets collected by Beijing Tongren Hospital. The promising results showcased the effectiveness of the proposed unsupervised learning method, and the strong application potential in biomedical resource shortage regions to improve global eye health.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023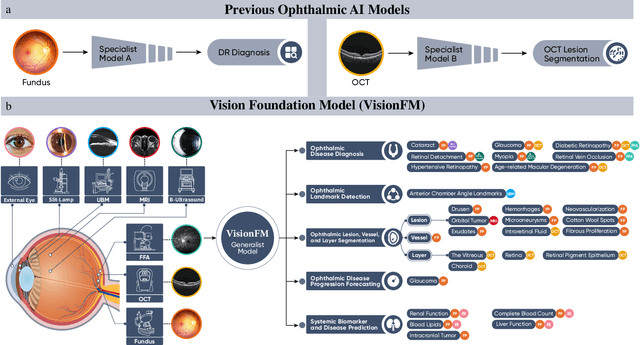
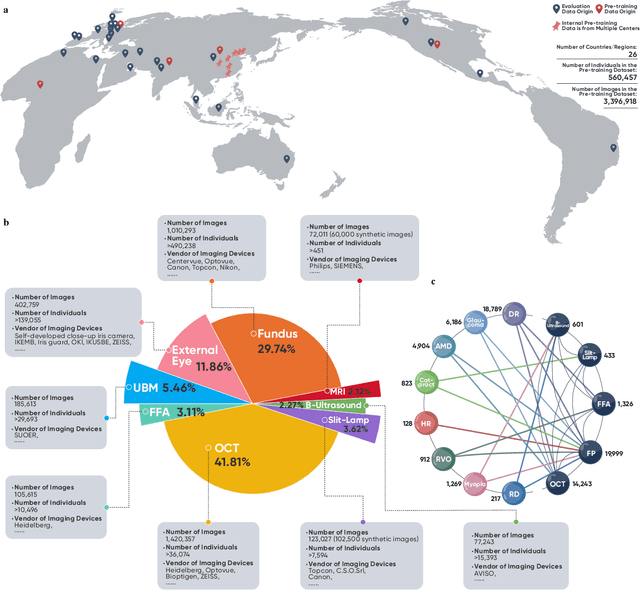

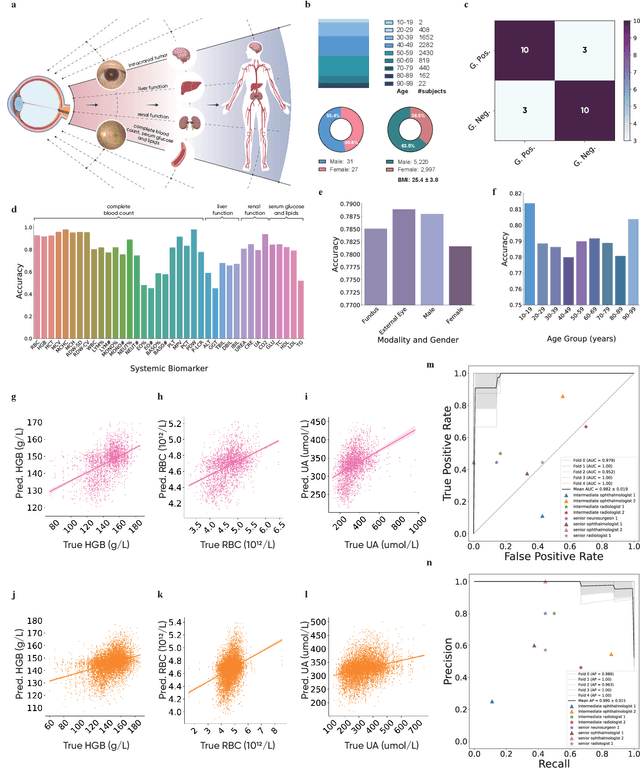
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.