 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Diffusion Large Language Models with SlowFast: The Three Golden Principles
Jun 12, 2025Diffusion-based language models (dLLMs) have emerged as a promising alternative to traditional autoregressive LLMs by enabling parallel token generation and significantly reducing inference latency. However, existing sampling strategies for dLLMs, such as confidence-based or semi-autoregressive decoding, often suffer from static behavior, leading to suboptimal efficiency and limited flexibility. In this paper, we propose SlowFast Sampling, a novel dynamic sampling strategy that adaptively alternates between exploratory and accelerated decoding stages. Our method is guided by three golden principles: certainty principle, convergence principle, and positional principle, which govern when and where tokens can be confidently and efficiently decoded. We further integrate our strategy with dLLM-Cache to reduce redundant computation. Extensive experiments across benchmarks and models show that SlowFast Sampling achieves up to 15.63$\times$ speedup on LLaDA with minimal accuracy drop, and up to 34.22$\times$ when combined with caching. Notably, our approach outperforms strong autoregressive baselines like LLaMA3 8B in throughput, demonstrating that well-designed sampling can unlock the full potential of dLLMs for fast and high-quality generation.
SkipVAR: Accelerating Visual Autoregressive Modeling via Adaptive Frequency-Aware Skipping
Jun 11, 2025Recent studies on Visual Autoregressive (VAR) models have highlighted that high-frequency components, or later steps, in the generation process contribute disproportionately to inference latency. However, the underlying computational redundancy involved in these steps has yet to be thoroughly investigated. In this paper, we conduct an in-depth analysis of the VAR inference process and identify two primary sources of inefficiency: step redundancy and unconditional branch redundancy. To address step redundancy, we propose an automatic step-skipping strategy that selectively omits unnecessary generation steps to improve efficiency. For unconditional branch redundancy, we observe that the information gap between the conditional and unconditional branches is minimal. Leveraging this insight, we introduce unconditional branch replacement, a technique that bypasses the unconditional branch to reduce computational cost. Notably, we observe that the effectiveness of acceleration strategies varies significantly across different samples. Motivated by this, we propose SkipVAR, a sample-adaptive framework that leverages frequency information to dynamically select the most suitable acceleration strategy for each instance. To evaluate the role of high-frequency information, we introduce high-variation benchmark datasets that test model sensitivity to fine details. Extensive experiments show SkipVAR achieves over 0.88 average SSIM with up to 1.81x overall acceleration and 2.62x speedup on the GenEval benchmark, maintaining model quality. These results confirm the effectiveness of frequency-aware, training-free adaptive acceleration for scalable autoregressive image generation. Our code is available at https://github.com/fakerone-li/SkipVAR and has been publicly released.
LazyMAR: Accelerating Masked Autoregressive Models via Feature Caching
Mar 16, 2025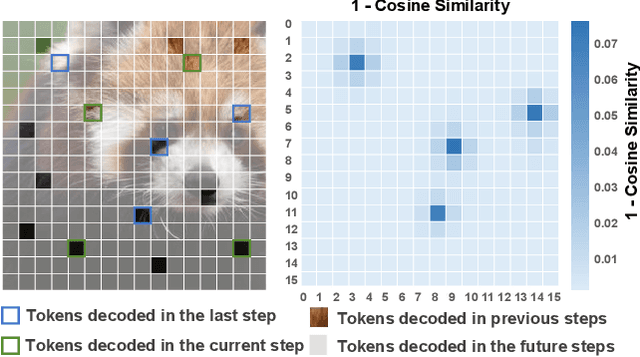
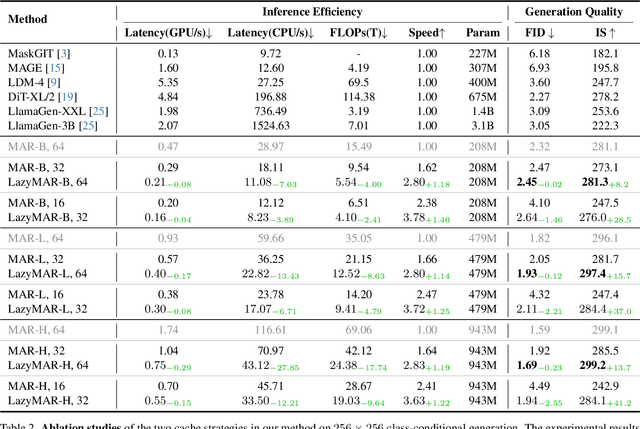
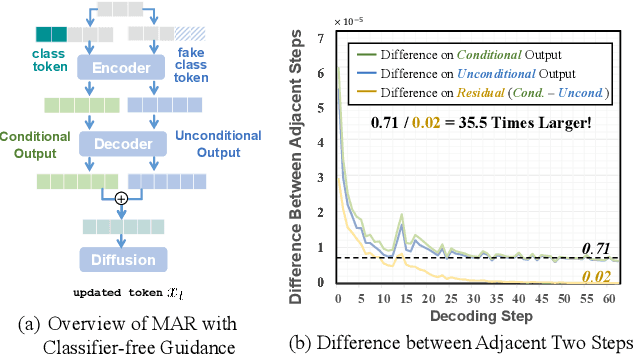

Masked Autoregressive (MAR) models have emerged as a promising approach in image generation, expected to surpass traditional autoregressive models in computational efficiency by leveraging the capability of parallel decoding. However, their dependence on bidirectional self-attention inherently conflicts with conventional KV caching mechanisms, creating unexpected computational bottlenecks that undermine their expected efficiency. To address this problem, this paper studies the caching mechanism for MAR by leveraging two types of redundancy: Token Redundancy indicates that a large portion of tokens have very similar representations in the adjacent decoding steps, which allows us to first cache them in previous steps and then reuse them in the later steps. Condition Redundancy indicates that the difference between conditional and unconditional output in classifier-free guidance exhibits very similar values in adjacent steps. Based on these two redundancies, we propose LazyMAR, which introduces two caching mechanisms to handle them one by one. LazyMAR is training-free and plug-and-play for all MAR models. Experimental results demonstrate that our method achieves 2.83 times acceleration with almost no drop in generation quality. Our codes will be released in https://github.com/feihongyan1/LazyMAR.