 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPS-Bench: Benchmarking Safety Awareness of Computer-Use Agents in Long-Horizon Planning under Benign and Adversarial Scenarios
Feb 03, 2026Computer-use agents (CUAs) that interact with real computer systems can perform automated tasks but face critical safety risks. Ambiguous instructions may trigger harmful actions, and adversarial users can manipulate tool execution to achieve malicious goals. Existing benchmarks mostly focus on short-horizon or GUI-based tasks, evaluating on execution-time errors but overlooking the ability to anticipate planning-time risks. To fill this gap, we present LPS-Bench, a benchmark that evaluates the planning-time safety awareness of MCP-based CUAs under long-horizon tasks, covering both benign and adversarial interactions across 65 scenarios of 7 task domains and 9 risk types. We introduce a multi-agent automated pipeline for scalable data generation and adopt an LLM-as-a-judge evaluation protocol to assess safety awareness through the planning trajectory. Experiments reveal substantial deficiencies in existing CUAs' ability to maintain safe behavior. We further analyze the risks and propose mitigation strategies to improve long-horizon planning safety in MCP-based CUA systems. We open-source our code at https://github.com/tychenn/LPS-Bench.
Interpreting Emergent Extreme Events in Multi-Agent Systems
Jan 28, 2026Large language model-powered multi-agent systems have emerged as powerful tools for simulating complex human-like systems. The interactions within these systems often lead to extreme events whose origins remain obscured by the black box of emergence. Interpreting these events is critical for system safety. This paper proposes the first framework for explaining emergent extreme events in multi-agent systems, aiming to answer three fundamental questions: When does the event originate? Who drives it? And what behaviors contribute to it? Specifically, we adapt the Shapley value to faithfully attribute the occurrence of extreme events to each action taken by agents at different time steps, i.e., assigning an attribution score to the action to measure its influence on the event. We then aggregate the attribution scores along the dimensions of time, agent, and behavior to quantify the risk contribution of each dimension. Finally, we design a set of metrics based on these contribution scores to characterize the features of extreme events. Experiments across diverse multi-agent system scenarios (economic, financial, and social) demonstrate the effectiveness of our framework and provide general insights into the emergence of extreme phenomena.
RvB: Automating AI System Hardening via Iterative Red-Blue Games
Jan 27, 2026The dual offensive and defensive utility of Large Language Models (LLMs) highlights a critical gap in AI security: the lack of unified frameworks for dynamic, iterative adversarial adaptation hardening. To bridge this gap, we propose the Red Team vs. Blue Team (RvB) framework, formulated as a training-free, sequential, imperfect-information game. In this process, the Red Team exposes vulnerabilities, driving the Blue Team to learning effective solutions without parameter updates. We validate our framework across two challenging domains: dynamic code hardening against CVEs and guardrail optimization against jailbreaks. Our empirical results show that this interaction compels the Blue Team to learn fundamental defensive principles, leading to robust remediations that are not merely overfitted to specific exploits. RvB achieves Defense Success Rates of 90\% and 45\% across the respective tasks while maintaining near 0\% False Positive Rates, significantly surpassing baselines. This work establishes the iterative adversarial interaction framework as a practical paradigm that automates the continuous hardening of AI systems.
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
The Why Behind the Action: Unveiling Internal Drivers via Agentic Attribution
Jan 21, 2026Large Language Model (LLM)-based agents are widely used in real-world applications such as customer service, web navigation, and software engineering. As these systems become more autonomous and are deployed at scale, understanding why an agent takes a particular action becomes increasingly important for accountability and governance. However, existing research predominantly focuses on \textit{failure attribution} to localize explicit errors in unsuccessful trajectories, which is insufficient for explaining the reasoning behind agent behaviors. To bridge this gap, we propose a novel framework for \textbf{general agentic attribution}, designed to identify the internal factors driving agent actions regardless of the task outcome. Our framework operates hierarchically to manage the complexity of agent interactions. Specifically, at the \textit{component level}, we employ temporal likelihood dynamics to identify critical interaction steps; then at the \textit{sentence level}, we refine this localization using perturbation-based analysis to isolate the specific textual evidence. We validate our framework across a diverse suite of agentic scenarios, including standard tool use and subtle reliability risks like memory-induced bias. Experimental results demonstrate that the proposed framework reliably pinpoints pivotal historical events and sentences behind the agent behavior, offering a critical step toward safer and more accountable agentic systems.
INFA-Guard: Mitigating Malicious Propagation via Infection-Aware Safeguarding in LLM-Based Multi-Agent Systems
Jan 21, 2026The rapid advancement of Large Language Model (LLM)-based Multi-Agent Systems (MAS) has introduced significant security vulnerabilities, where malicious influence can propagate virally through inter-agent communication. Conventional safeguards often rely on a binary paradigm that strictly distinguishes between benign and attack agents, failing to account for infected agents i.e., benign entities converted by attack agents. In this paper, we propose Infection-Aware Guard, INFA-Guard, a novel defense framework that explicitly identifies and addresses infected agents as a distinct threat category. By leveraging infection-aware detection and topological constraints, INFA-Guard accurately localizes attack sources and infected ranges. During remediation, INFA-Guard replaces attackers and rehabilitates infected ones, avoiding malicious propagation while preserving topological integrity. Extensive experiments demonstrate that INFA-Guard achieves state-of-the-art performance, reducing the Attack Success Rate (ASR) by an average of 33%, while exhibiting cross-model robustness, superior topological generalization, and high cost-effectiveness.
Loop as a Bridge: Can Looped Transformers Truly Link Representation Space and Natural Language Outputs?
Jan 15, 2026Large Language Models (LLMs) often exhibit a gap between their internal knowledge and their explicit linguistic outputs. In this report, we empirically investigate whether Looped Transformers (LTs)--architectures that increase computational depth by iterating shared layers--can bridge this gap by utilizing their iterative nature as a form of introspection. Our experiments reveal that while increasing loop iterations narrows the gap, it is partly driven by a degradation of their internal knowledge carried by representations. Moreover, another empirical analysis suggests that current LTs' ability to perceive representations does not improve across loops; it is only present in the final loop. These results suggest that while LTs offer a promising direction for scaling computational depth, they have yet to achieve the introspection required to truly link representation space and natural language.
ExGRPO: Learning to Reason from Experience
Oct 02, 2025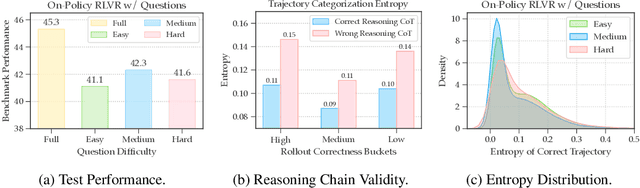
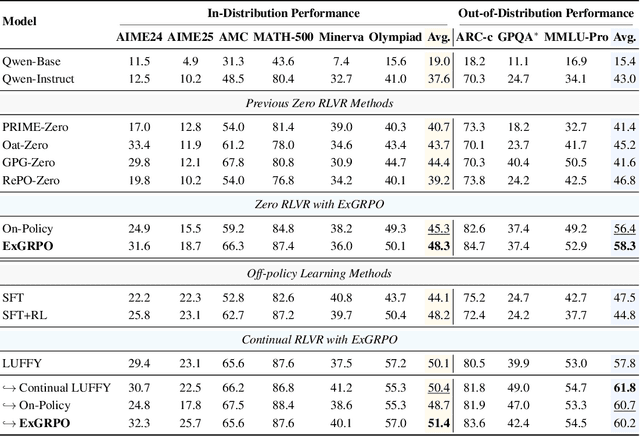
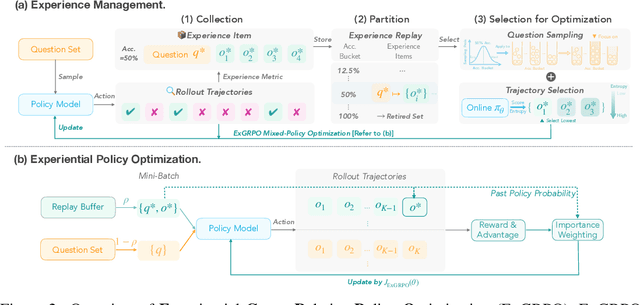
Reinforcement learning from verifiable rewards (RLVR) is an emerging paradigm for improving the reasoning ability of large language models. However, standard on-policy training discards rollout experiences after a single update, leading to computational inefficiency and instability. While prior work on RL has highlighted the benefits of reusing past experience, the role of experience characteristics in shaping learning dynamics of large reasoning models remains underexplored. In this paper, we are the first to investigate what makes a reasoning experience valuable and identify rollout correctness and entropy as effective indicators of experience value. Based on these insights, we propose ExGRPO (Experiential Group Relative Policy Optimization), a framework that organizes and prioritizes valuable experiences, and employs a mixed-policy objective to balance exploration with experience exploitation. Experiments on five backbone models (1.5B-8B parameters) show that ExGRPO consistently improves reasoning performance on mathematical/general benchmarks, with an average gain of +3.5/7.6 points over on-policy RLVR. Moreover, ExGRPO stabilizes training on both stronger and weaker models where on-policy methods fail. These results highlight principled experience management as a key ingredient for efficient and scalable RLVR.
Reasoning over Boundaries: Enhancing Specification Alignment via Test-time Delibration
Sep 18, 2025Large language models (LLMs) are increasingly applied in diverse real-world scenarios, each governed by bespoke behavioral and safety specifications (spec) custom-tailored by users or organizations. These spec, categorized into safety-spec and behavioral-spec, vary across scenarios and evolve with changing preferences and requirements. We formalize this challenge as specification alignment, focusing on LLMs' ability to follow dynamic, scenario-specific spec from both behavioral and safety perspectives. To address this challenge, we propose Align3, a lightweight method that employs Test-Time Deliberation (TTD) with hierarchical reflection and revision to reason over the specification boundaries. We further present SpecBench, a unified benchmark for measuring specification alignment, covering 5 scenarios, 103 spec, and 1,500 prompts. Experiments on 15 reasoning and 18 instruct models with several TTD methods, including Self-Refine, TPO, and MoreThink, yield three key findings: (i) test-time deliberation enhances specification alignment; (ii) Align3 advances the safety-helpfulness trade-off frontier with minimal overhead; (iii) SpecBench effectively reveals alignment gaps. These results highlight the potential of test-time deliberation as an effective strategy for reasoning over the real-world specification boundaries.
The LLM Already Knows: Estimating LLM-Perceived Question Difficulty via Hidden Representations
Sep 16, 2025Estimating the difficulty of input questions as perceived by large language models (LLMs) is essential for accurate performance evaluation and adaptive inference. Existing methods typically rely on repeated response sampling, auxiliary models, or fine-tuning the target model itself, which may incur substantial computational costs or compromise generality. In this paper, we propose a novel approach for difficulty estimation that leverages only the hidden representations produced by the target LLM. We model the token-level generation process as a Markov chain and define a value function to estimate the expected output quality given any hidden state. This allows for efficient and accurate difficulty estimation based solely on the initial hidden state, without generating any output tokens. Extensive experiments across both textual and multimodal tasks demonstrate that our method consistently outperforms existing baselines in difficulty estimation. Moreover, we apply our difficulty estimates to guide adaptive reasoning strategies, including Self-Consistency, Best-of-N, and Self-Refine, achieving higher inference efficiency with fewer generated tokens.