 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3MAD-Bench: Are Multi-Agent Debates Really Effective Across Domains and Modalities?
Jan 06, 2026As an agent-level reasoning and coordination paradigm, Multi-Agent Debate (MAD) orchestrates multiple agents through structured debate to improve answer quality and support complex reasoning. However, existing research on MAD suffers from two fundamental limitations: evaluations are conducted under fragmented and inconsistent settings, hindering fair comparison, and are largely restricted to single-modality scenarios that rely on textual inputs only. To address these gaps, we introduce M3MAD-Bench, a unified and extensible benchmark for evaluating MAD methods across Multi-domain tasks, Multi-modal inputs, and Multi-dimensional metrics. M3MAD-Bench establishes standardized protocols over five core task domains: Knowledge, Mathematics, Medicine, Natural Sciences, and Complex Reasoning, and systematically covers both pure text and vision-language datasets, enabling controlled cross-modality comparison. We evaluate MAD methods on nine base models spanning different architectures, scales, and modality capabilities. Beyond accuracy, M3MAD-Bench incorporates efficiency-oriented metrics such as token consumption and inference time, providing a holistic view of performance--cost trade-offs. Extensive experiments yield systematic insights into the effectiveness, robustness, and efficiency of MAD across text-only and multimodal scenarios. We believe M3MAD-Bench offers a reliable foundation for future research on standardized MAD evaluation. The code is available at http://github.com/liaolea/M3MAD-Bench.
Benchmarking Multimodal Knowledge Conflict for Large Multimodal Models
May 26, 2025Large Multimodal Models(LMMs) face notable challenges when encountering multimodal knowledge conflicts, particularly under retrieval-augmented generation(RAG) frameworks where the contextual information from external sources may contradict the model's internal parametric knowledge, leading to unreliable outputs. However, existing benchmarks fail to reflect such realistic conflict scenarios. Most focus solely on intra-memory conflicts, while context-memory and inter-context conflicts remain largely investigated. Furthermore, commonly used factual knowledge-based evaluations are often overlooked, and existing datasets lack a thorough investigation into conflict detection capabilities. To bridge this gap, we propose MMKC-Bench, a benchmark designed to evaluate factual knowledge conflicts in both context-memory and inter-context scenarios. MMKC-Bench encompasses three types of multimodal knowledge conflicts and includes 1,573 knowledge instances and 3,381 images across 23 broad types, collected through automated pipelines with human verification. We evaluate three representative series of LMMs on both model behavior analysis and conflict detection tasks. Our findings show that while current LMMs are capable of recognizing knowledge conflicts, they tend to favor internal parametric knowledge over external evidence. We hope MMKC-Bench will foster further research in multimodal knowledge conflict and enhance the development of multimodal RAG systems. The source code is available at https://github.com/MLLMKCBENCH/MLLMKC.
LaplaceConfidence: a Graph-based Approach for Learning with Noisy Labels
Jul 31, 2023



In real-world applications, perfect labels are rarely available, making it challenging to develop robust machine learning algorithms that can handle noisy labels. Recent methods have focused on filtering noise based on the discrepancy between model predictions and given noisy labels, assuming that samples with small classification losses are clean. This work takes a different approach by leveraging the consistency between the learned model and the entire noisy dataset using the rich representational and topological information in the data. We introduce LaplaceConfidence, a method that to obtain label confidence (i.e., clean probabilities) utilizing the Laplacian energy. Specifically, it first constructs graphs based on the feature representations of all noisy samples and minimizes the Laplacian energy to produce a low-energy graph. Clean labels should fit well into the low-energy graph while noisy ones should not, allowing our method to determine data's clean probabilities. Furthermore, LaplaceConfidence is embedded into a holistic method for robust training, where co-training technique generates unbiased label confidence and label refurbishment technique better utilizes it. We also explore the dimensionality reduction technique to accommodate our method on large-scale noisy datasets. Our experiments demonstrate that LaplaceConfidence outperforms state-of-the-art methods on benchmark datasets under both synthetic and real-world noise.
A Noisy-Label-Learning Formulation for Immune Repertoire Classification and Disease-Associated Immune Receptor Sequence Identification
Jul 29, 2023



Immune repertoire classification, a typical multiple instance learning (MIL) problem, is a frontier research topic in computational biology that makes transformative contributions to new vaccines and immune therapies. However, the traditional instance-space MIL, directly assigning bag-level labels to instances, suffers from the massive amount of noisy labels and extremely low witness rate. In this work, we propose a noisy-label-learning formulation to solve the immune repertoire classification task. To remedy the inaccurate supervision of repertoire-level labels for a sequence-level classifier, we design a robust training strategy: The initial labels are smoothed to be asymmetric and are progressively corrected using the model's predictions throughout the training process. Furthermore, two models with the same architecture but different parameter initialization are co-trained simultaneously to remedy the known "confirmation bias" problem in the self-training-like schema. As a result, we obtain accurate sequence-level classification and, subsequently, repertoire-level classification. Experiments on the Cytomegalovirus (CMV) and Cancer datasets demonstrate our method's effectiveness and superior performance on sequence-level and repertoire-level tasks.
DOS: Diverse Outlier Sampling for Out-of-Distribution Detection
Jun 03, 2023Modern neural networks are known to give overconfident prediction for out-of-distribution inputs when deployed in the open world. It is common practice to leverage a surrogate outlier dataset to regularize the model during training, and recent studies emphasize the role of uncertainty in designing the sampling strategy for outlier dataset. However, the OOD samples selected solely based on predictive uncertainty can be biased towards certain types, which may fail to capture the full outlier distribution. In this work, we empirically show that diversity is critical in sampling outliers for OOD detection performance. Motivated by the observation, we propose a straightforward and novel sampling strategy named DOS (Diverse Outlier Sampling) to select diverse and informative outliers. Specifically, we cluster the normalized features at each iteration, and the most informative outlier from each cluster is selected for model training with absent category loss. With DOS, the sampled outliers efficiently shape a globally compact decision boundary between ID and OOD data. Extensive experiments demonstrate the superiority of DOS, reducing the average FPR95 by up to 25.79% on CIFAR-100 with TI-300K.
Spatial-Temporal Graph Convolutional Gated Recurrent Network for Traffic Forecasting
Oct 06, 2022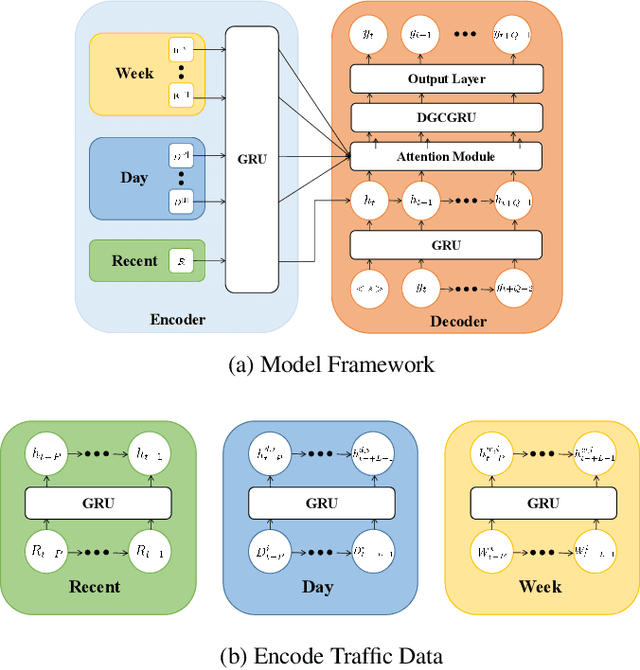
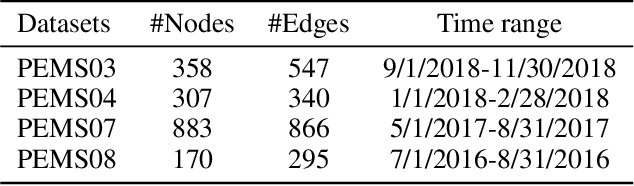
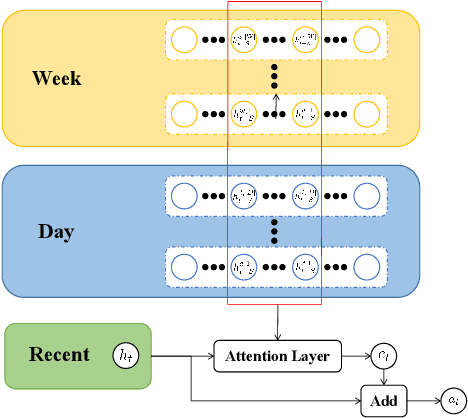
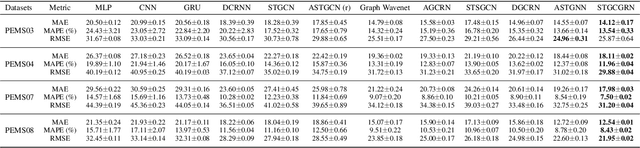
As an important part of intelligent transportation systems, traffic forecasting has attracted tremendous attention from academia and industry. Despite a lot of methods being proposed for traffic forecasting, it is still difficult to model complex spatial-temporal dependency. Temporal dependency includes short-term dependency and long-term dependency, and the latter is often overlooked. Spatial dependency can be divided into two parts: distance-based spatial dependency and hidden spatial dependency. To model complex spatial-temporal dependency, we propose a novel framework for traffic forecasting, named Spatial-Temporal Graph Convolutional Gated Recurrent Network (STGCGRN). We design an attention module to capture long-term dependency by mining periodic information in traffic data. We propose a Double Graph Convolution Gated Recurrent Unit (DGCGRU) to capture spatial dependency, which integrates graph convolutional network and GRU. The graph convolution part models distance-based spatial dependency with the distance-based predefined adjacency matrix and hidden spatial dependency with the self-adaptive adjacency matrix, respectively. Specially, we employ the multi-head mechanism to capture multiple hidden dependencies. In addition, the periodic pattern of each prediction node may be different, which is often ignored, resulting in mutual interference of periodic information among nodes when modeling spatial dependency. For this, we explore the architecture of model and improve the performance. Experiments on four datasets demonstrate the superior performance of our model.
READ: Aggregating Reconstruction Error into Out-of-distribution Detection
Jun 15, 2022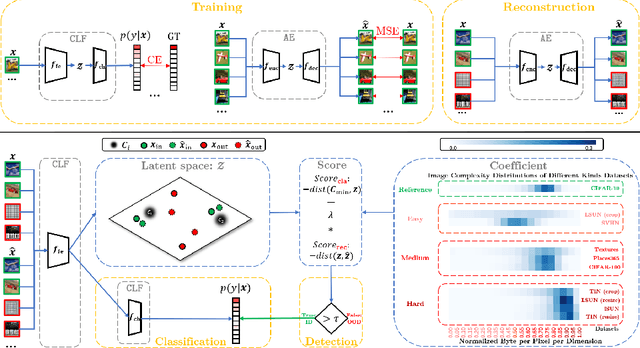
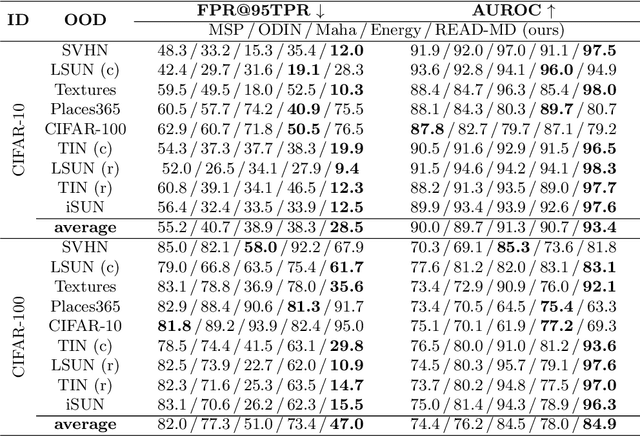
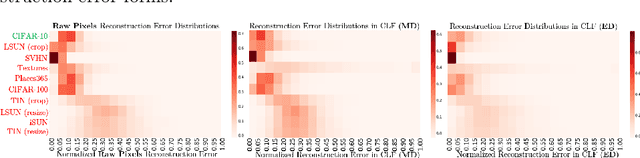
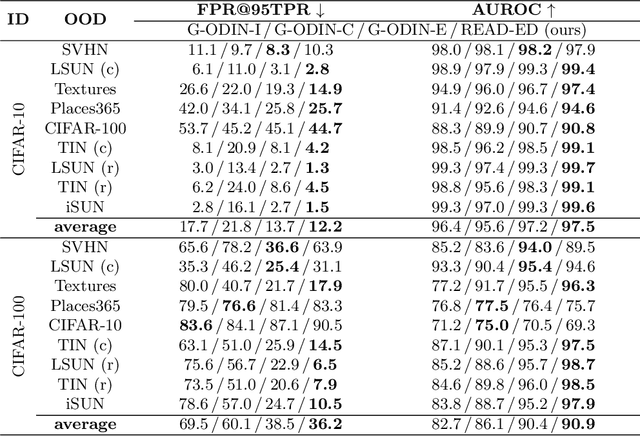
Detecting out-of-distribution (OOD) samples is crucial to the safe deployment of a classifier in the real world. However, deep neural networks are known to be overconfident for abnormal data. Existing works directly design score function by mining the inconsistency from classifier for in-distribution (ID) and OOD. In this paper, we further complement this inconsistency with reconstruction error, based on the assumption that an autoencoder trained on ID data can not reconstruct OOD as well as ID. We propose a novel method, READ (Reconstruction Error Aggregated Detector), to unify inconsistencies from classifier and autoencoder. Specifically, the reconstruction error of raw pixels is transformed to latent space of classifier. We show that the transformed reconstruction error bridges the semantic gap and inherits detection performance from the original. Moreover, we propose an adjustment strategy to alleviate the overconfidence problem of autoencoder according to a fine-grained characterization of OOD data. Under two scenarios of pre-training and retraining, we respectively present two variants of our method, namely READ-MD (Mahalanobis Distance) only based on pre-trained classifier and READ-ED (Euclidean Distance) which retrains the classifier. Our methods do not require access to test time OOD data for fine-tuning hyperparameters. Finally, we demonstrate the effectiveness of the proposed methods through extensive comparisons with state-of-the-art OOD detection algorithms. On a CIFAR-10 pre-trained WideResNet, our method reduces the average FPR@95TPR by up to 9.8% compared with previous state-of-the-art.
Two Wrongs Don't Make a Right: Combating Confirmation Bias in Learning with Label Noise
Dec 06, 2021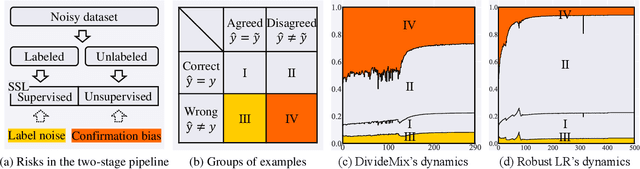
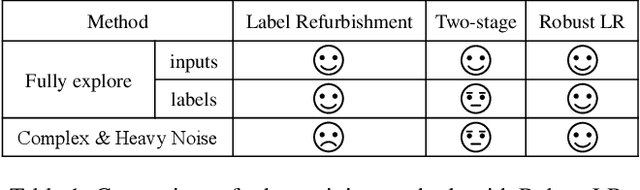
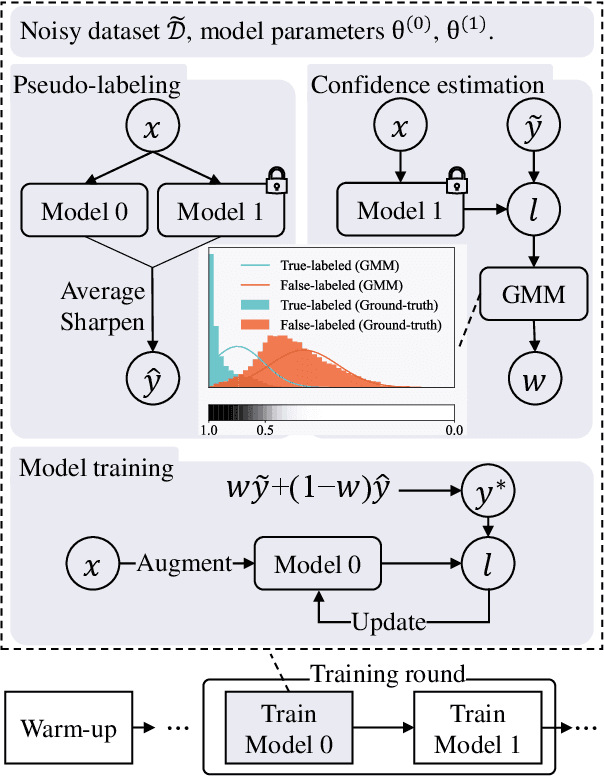
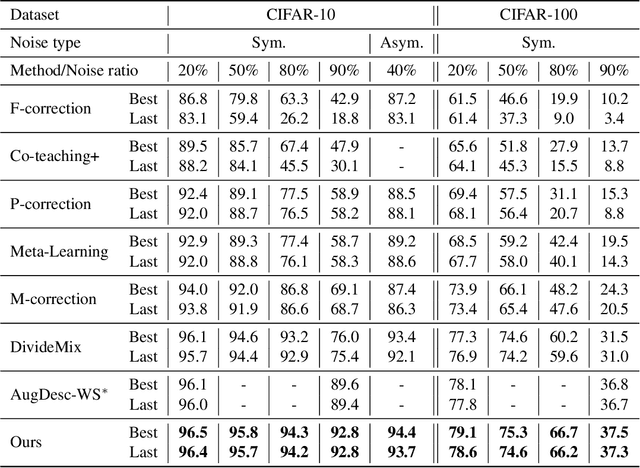
Noisy labels damage the performance of deep networks. For robust learning, a prominent two-stage pipeline alternates between eliminating possible incorrect labels and semi-supervised training. However, discarding part of observed labels could result in a loss of information, especially when the corruption is not completely random, e.g., class-dependent or instance-dependent. Moreover, from the training dynamics of a representative two-stage method DivideMix, we identify the domination of confirmation bias: Pseudo-labels fail to correct a considerable amount of noisy labels and consequently, the errors accumulate. To sufficiently exploit information from observed labels and mitigate wrong corrections, we propose Robust Label Refurbishment (Robust LR)-a new hybrid method that integrates pseudo-labeling and confidence estimation techniques to refurbish noisy labels. We show that our method successfully alleviates the damage of both label noise and confirmation bias. As a result, it achieves state-of-the-art results across datasets and noise types. For example, Robust LR achieves up to 4.5% absolute top-1 accuracy improvement over the previous best on the real-world noisy dataset WebVision.
Generation, augmentation, and alignment: A pseudo-source domain based method for source-free domain adaptation
Sep 09, 2021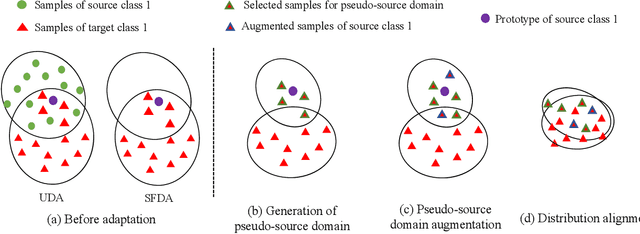
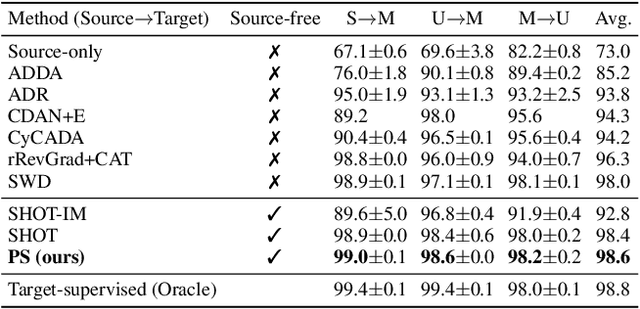
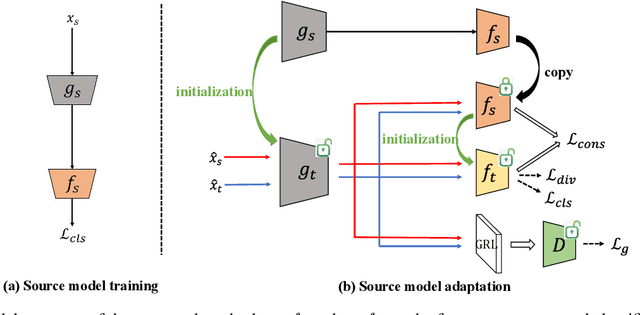
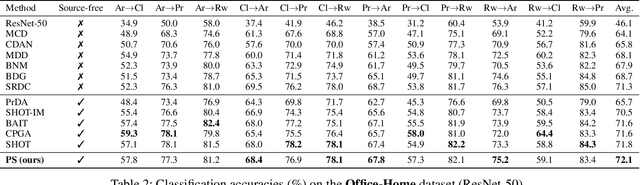
Conventional unsupervised domain adaptation (UDA) methods need to access both labeled source samples and unlabeled target samples simultaneously to train the model. While in some scenarios, the source samples are not available for the target domain due to data privacy and safety. To overcome this challenge, recently, source-free domain adaptation (SFDA) has attracted the attention of researchers, where both a trained source model and unlabeled target samples are given. Existing SFDA methods either adopt a pseudo-label based strategy or generate more samples. However, these methods do not explicitly reduce the distribution shift across domains, which is the key to a good adaptation. Although there are no source samples available, fortunately, we find that some target samples are very similar to the source domain and can be used to approximate the source domain. This approximated domain is denoted as the pseudo-source domain. In this paper, inspired by this observation, we propose a novel method based on the pseudo-source domain. The proposed method firstly generates and augments the pseudo-source domain, and then employs distribution alignment with four novel losses based on pseudo-label based strategy. Among them, a domain adversarial loss is introduced between the pseudo-source domain the remaining target domain to reduce the distribution shift. The results on three real-world datasets verify the effectiveness of the proposed method.
Semi-Supervised Learning with Multi-Head Co-Training
Jul 10, 2021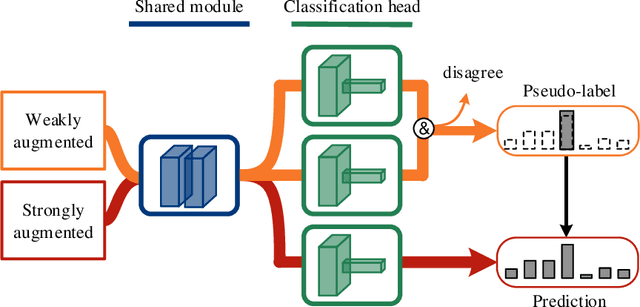


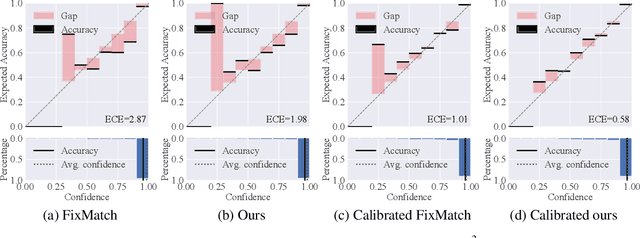
Co-training, extended from self-training, is one of the frameworks for semi-supervised learning. It works at the cost of training extra classifiers, where the algorithm should be delicately designed to prevent individual classifiers from collapsing into each other. In this paper, we present a simple and efficient co-training algorithm, named Multi-Head Co-Training, for semi-supervised image classification. By integrating base learners into a multi-head structure, the model is in a minimal amount of extra parameters. Every classification head in the unified model interacts with its peers through a "Weak and Strong Augmentation" strategy, achieving single-view co-training without promoting diversity explicitly. The effectiveness of Multi-Head Co-Training is demonstrated in an empirical study on standard semi-supervised learning benchmarks.