 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Wrongs Don't Make a Right: Combating Confirmation Bias in Learning with Label Noise
Paper and Code
Dec 06, 2021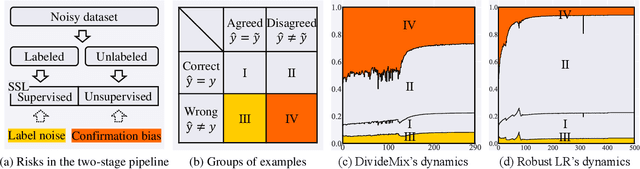
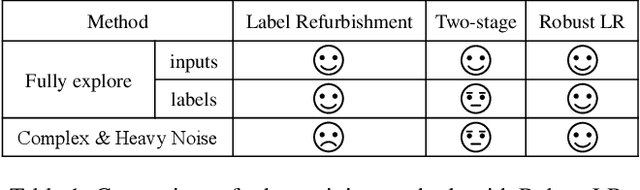
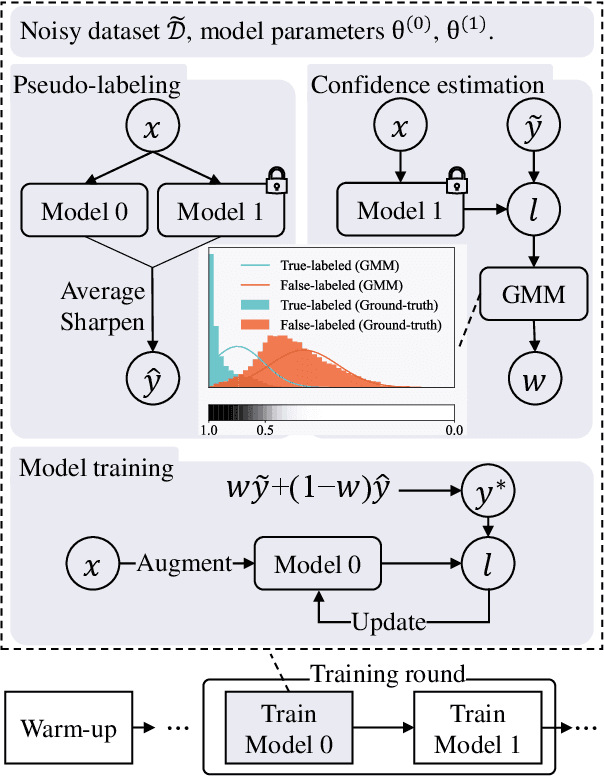
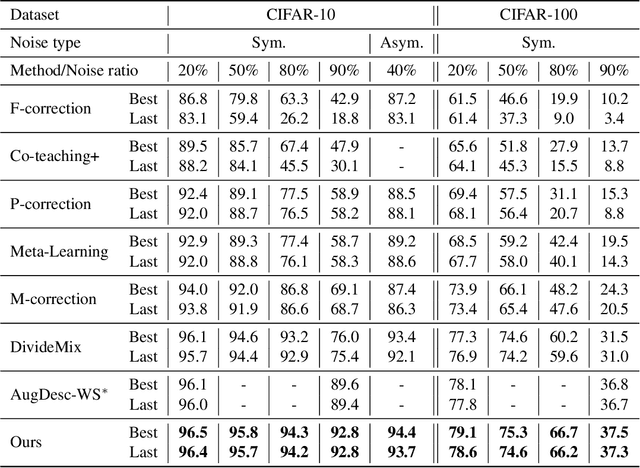
Noisy labels damage the performance of deep networks. For robust learning, a prominent two-stage pipeline alternates between eliminating possible incorrect labels and semi-supervised training. However, discarding part of observed labels could result in a loss of information, especially when the corruption is not completely random, e.g., class-dependent or instance-dependent. Moreover, from the training dynamics of a representative two-stage method DivideMix, we identify the domination of confirmation bias: Pseudo-labels fail to correct a considerable amount of noisy labels and consequently, the errors accumulate. To sufficiently exploit information from observed labels and mitigate wrong corrections, we propose Robust Label Refurbishment (Robust LR)-a new hybrid method that integrates pseudo-labeling and confidence estimation techniques to refurbish noisy labels. We show that our method successfully alleviates the damage of both label noise and confirmation bias. As a result, it achieves state-of-the-art results across datasets and noise types. For example, Robust LR achieves up to 4.5% absolute top-1 accuracy improvement over the previous best on the real-world noisy dataset WebVision.