 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIVM: Diffusion-Based Prior-Integrated Variation Modeling for Anatomically Precise Abdominal CT Synthesis
Mar 23, 2026Abdominal CT data are limited by high annotation costs and privacy constraints, which hinder the development of robust segmentation and diagnostic models. We present a Prior-Integrated Variation Modeling (PIVM) framework, a diffusion-based method for anatomically accurate CT image synthesis. Instead of generating full images from noise, PIVM predicts voxel-wise intensity variations relative to organ-specific intensity priors derived from segmentation labels. These priors and labels jointly guide the diffusion process, ensuring spatial alignment and realistic organ boundaries. Unlike latent-space diffusion models, our approach operates directly in image space while preserving the full Hounsfield Unit (HU) range, capturing fine anatomical textures without smoothing. Source code is available at https://github.com/BZNR3/PIVM.
Learnability-Driven Submodular Optimization for Active Roadside 3D Detection
Jan 04, 2026Roadside perception datasets are typically constructed via cooperative labeling between synchronized vehicle and roadside frame pairs. However, real deployment often requires annotation of roadside-only data due to hardware and privacy constraints. Even human experts struggle to produce accurate labels without vehicle-side data (image, LIDAR), which not only increases annotation difficulty and cost, but also reveals a fundamental learnability problem: many roadside-only scenes contain distant, blurred, or occluded objects whose 3D properties are ambiguous from a single view and can only be reliably annotated by cross-checking paired vehicle--roadside frames. We refer to such cases as inherently ambiguous samples. To reduce wasted annotation effort on inherently ambiguous samples while still obtaining high-performing models, we turn to active learning. This work focuses on active learning for roadside monocular 3D object detection and proposes a learnability-driven framework that selects scenes which are both informative and reliably labelable, suppressing inherently ambiguous samples while ensuring coverage. Experiments demonstrate that our method, LH3D, achieves 86.06%, 67.32%, and 78.67% of full-performance for vehicles, pedestrians, and cyclists respectively, using only 25% of the annotation budget on DAIR-V2X-I, significantly outperforming uncertainty-based baselines. This confirms that learnability, not uncertainty, matters for roadside 3D perception.
SafeFix: Targeted Model Repair via Controlled Image Generation
Aug 12, 2025



Deep learning models for visual recognition often exhibit systematic errors due to underrepresented semantic subpopulations. Although existing debugging frameworks can pinpoint these failures by identifying key failure attributes, repairing the model effectively remains difficult. Current solutions often rely on manually designed prompts to generate synthetic training images -- an approach prone to distribution shift and semantic errors. To overcome these challenges, we introduce a model repair module that builds on an interpretable failure attribution pipeline. Our approach uses a conditional text-to-image model to generate semantically faithful and targeted images for failure cases. To preserve the quality and relevance of the generated samples, we further employ a large vision-language model (LVLM) to filter the outputs, enforcing alignment with the original data distribution and maintaining semantic consistency. By retraining vision models with this rare-case-augmented synthetic dataset, we significantly reduce errors associated with rare cases. Our experiments demonstrate that this targeted repair strategy improves model robustness without introducing new bugs. Code is available at https://github.com/oxu2/SafeFix
Normalize Then Propagate: Efficient Homophilous Regularization for Few-shot Semi-Supervised Node Classification
Jan 15, 2025



Graph Neural Networks (GNNs) have demonstrated remarkable ability in semi-supervised node classification. However, most existing GNNs rely heavily on a large amount of labeled data for training, which is labor-intensive and requires extensive domain knowledge. In this paper, we first analyze the restrictions of GNNs generalization from the perspective of supervision signals in the context of few-shot semi-supervised node classification. To address these challenges, we propose a novel algorithm named NormProp, which utilizes the homophily assumption of unlabeled nodes to generate additional supervision signals, thereby enhancing the generalization against label scarcity. The key idea is to efficiently capture both the class information and the consistency of aggregation during message passing, via decoupling the direction and Euclidean norm of node representations. Moreover, we conduct a theoretical analysis to determine the upper bound of Euclidean norm, and then propose homophilous regularization to constraint the consistency of unlabeled nodes. Extensive experiments demonstrate that NormProp achieve state-of-the-art performance under low-label rate scenarios with low computational complexity.
Enhancing Robustness of CLIP to Common Corruptions through Bimodal Test-Time Adaptation
Dec 03, 2024



Although open-vocabulary classification models like Contrastive Language Image Pretraining (CLIP) have demonstrated strong zero-shot learning capabilities, their robustness to common image corruptions remains poorly understood. Through extensive experiments, we show that zero-shot CLIP lacks robustness to common image corruptions at increasing severity levels during test-time, necessitating the adaptation of CLIP to unlabeled corrupted images using test-time adaptation (TTA). However, we found that existing TTA methods have severe limitations in adapting CLIP due to their unimodal nature. To address these limitations, we propose \framework, a bimodal TTA method specially designed to improve CLIP's robustness to common image corruptions. The key insight of our approach is not only to adapt the visual encoders for better image feature extraction but also to strengthen the alignment between image and text features by promoting a stronger association between the image class prototype, computed using pseudo-labels, and the corresponding text feature. We evaluate our approach on benchmark image corruption datasets and achieve state-of-the-art results in TTA for CLIP, specifically for domains involving image corruption. Particularly, with a ViT-B/16 vision backbone, we obtain mean accuracy improvements of 9.7%, 5.94%, and 5.12% for CIFAR-10C, CIFAR-100C, and ImageNet-C, respectively.
GaGSL: Global-augmented Graph Structure Learning via Graph Information Bottleneck
Nov 07, 2024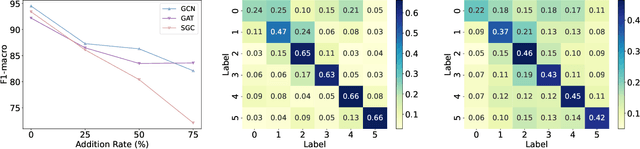
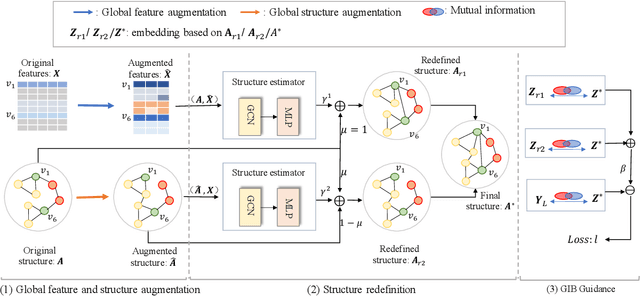
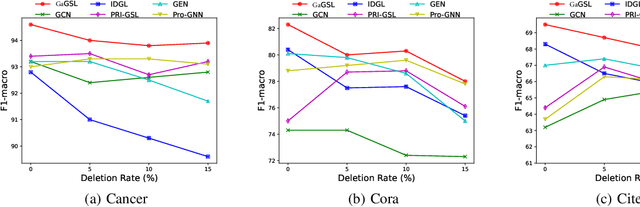
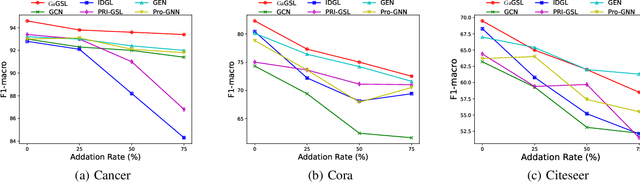
Graph neural networks (GNNs) are prominent for their effectiveness in processing graph data for semi-supervised node classification tasks. Most works of GNNs assume that the observed structure accurately represents the underlying node relationships. However, the graph structure is inevitably noisy or incomplete in reality, which can degrade the quality of graph representations. Therefore, it is imperative to learn a clean graph structure that balances performance and robustness. In this paper, we propose a novel method named \textit{Global-augmented Graph Structure Learning} (GaGSL), guided by the Graph Information Bottleneck (GIB) principle. The key idea behind GaGSL is to learn a compact and informative graph structure for node classification tasks. Specifically, to mitigate the bias caused by relying solely on the original structure, we first obtain augmented features and augmented structure through global feature augmentation and global structure augmentation. We then input the augmented features and augmented structure into a structure estimator with different parameters for optimization and re-definition of the graph structure, respectively. The redefined structures are combined to form the final graph structure. Finally, we employ GIB based on mutual information to guide the optimization of the graph structure to obtain the minimum sufficient graph structure. Comprehensive evaluations across a range of datasets reveal the outstanding performance and robustness of GaGSL compared with the state-of-the-art methods.
Graph Neural Networks with Coarse- and Fine-Grained Division for Mitigating Label Sparsity and Noise
Nov 06, 2024Graph Neural Networks (GNNs) have gained considerable prominence in semi-supervised learning tasks in processing graph-structured data, primarily owing to their message-passing mechanism, which largely relies on the availability of clean labels. However, in real-world scenarios, labels on nodes of graphs are inevitably noisy and sparsely labeled, significantly degrading the performance of GNNs. Exploring robust GNNs for semi-supervised node classification in the presence of noisy and sparse labels remains a critical challenge. Therefore, we propose a novel \textbf{G}raph \textbf{N}eural \textbf{N}etwork with \textbf{C}oarse- and \textbf{F}ine-\textbf{G}rained \textbf{D}ivision for mitigating label sparsity and noise, namely GNN-CFGD. The key idea of GNN-CFGD is reducing the negative impact of noisy labels via coarse- and fine-grained division, along with graph reconstruction. Specifically, we first investigate the effectiveness of linking unlabeled nodes to cleanly labeled nodes, demonstrating that this approach is more effective in combating labeling noise than linking to potentially noisy labeled nodes. Based on this observation, we introduce a Gaussian Mixture Model (GMM) based on the memory effect to perform a coarse-grained division of the given labels into clean and noisy labels. Next, we propose a clean labels oriented link that connects unlabeled nodes to cleanly labeled nodes, aimed at mitigating label sparsity and promoting supervision propagation. Furthermore, to provide refined supervision for noisy labeled nodes and additional supervision for unlabeled nodes, we fine-grain the noisy labeled and unlabeled nodes into two candidate sets based on confidence, respectively. Extensive experiments on various datasets demonstrate the superior effectiveness and robustness of GNN-CFGD.
Similarity-Navigated Conformal Prediction for Graph Neural Networks
May 23, 2024



Graph Neural Networks have achieved remarkable accuracy in semi-supervised node classification tasks. However, these results lack reliable uncertainty estimates. Conformal prediction methods provide a theoretical guarantee for node classification tasks, ensuring that the conformal prediction set contains the ground-truth label with a desired probability (e.g., 95%). In this paper, we empirically show that for each node, aggregating the non-conformity scores of nodes with the same label can improve the efficiency of conformal prediction sets. This observation motivates us to propose a novel algorithm named Similarity-Navigated Adaptive Prediction Sets (SNAPS), which aggregates the non-conformity scores based on feature similarity and structural neighborhood. The key idea behind SNAPS is that nodes with high feature similarity or direct connections tend to have the same label. By incorporating adaptive similar nodes information, SNAPS can generate compact prediction sets and increase the singleton hit ratio (correct prediction sets of size one). Moreover, we theoretically provide a finite-sample coverage guarantee of SNAPS. Extensive experiments demonstrate the superiority of SNAPS, improving the efficiency of prediction sets and singleton hit ratio while maintaining valid coverage.
PALM: Pushing Adaptive Learning Rate Mechanisms for Continual Test-Time Adaptation
Mar 15, 2024Real-world vision models in dynamic environments face rapid shifts in domain distributions, leading to decreased recognition performance. Continual test-time adaptation (CTTA) directly adjusts a pre-trained source discriminative model to these changing domains using test data. A highly effective CTTA method involves applying layer-wise adaptive learning rates, and selectively adapting pre-trained layers. However, it suffers from the poor estimation of domain shift and the inaccuracies arising from the pseudo-labels. In this work, we aim to overcome these limitations by identifying layers through the quantification of model prediction uncertainty without relying on pseudo-labels. We utilize the magnitude of gradients as a metric, calculated by backpropagating the KL divergence between the softmax output and a uniform distribution, to select layers for further adaptation. Subsequently, for the parameters exclusively belonging to these selected layers, with the remaining ones frozen, we evaluate their sensitivity in order to approximate the domain shift, followed by adjusting their learning rates accordingly. Overall, this approach leads to a more robust and stable optimization than prior approaches. We conduct extensive image classification experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C and demonstrate the efficacy of our method against standard benchmarks and prior methods.
LaplaceConfidence: a Graph-based Approach for Learning with Noisy Labels
Jul 31, 2023



In real-world applications, perfect labels are rarely available, making it challenging to develop robust machine learning algorithms that can handle noisy labels. Recent methods have focused on filtering noise based on the discrepancy between model predictions and given noisy labels, assuming that samples with small classification losses are clean. This work takes a different approach by leveraging the consistency between the learned model and the entire noisy dataset using the rich representational and topological information in the data. We introduce LaplaceConfidence, a method that to obtain label confidence (i.e., clean probabilities) utilizing the Laplacian energy. Specifically, it first constructs graphs based on the feature representations of all noisy samples and minimizes the Laplacian energy to produce a low-energy graph. Clean labels should fit well into the low-energy graph while noisy ones should not, allowing our method to determine data's clean probabilities. Furthermore, LaplaceConfidence is embedded into a holistic method for robust training, where co-training technique generates unbiased label confidence and label refurbishment technique better utilizes it. We also explore the dimensionality reduction technique to accommodate our method on large-scale noisy datasets. Our experiments demonstrate that LaplaceConfidence outperforms state-of-the-art methods on benchmark datasets under both synthetic and real-world noise.