 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Native Continuation for Action Chunking Flow Policies
Feb 13, 2026Action chunking enables Vision Language Action (VLA) models to run in real time, but naive chunked execution often exhibits discontinuities at chunk boundaries. Real-Time Chunking (RTC) alleviates this issue but is external to the policy, leading to spurious multimodal switching and trajectories that are not intrinsically smooth. We propose Legato, a training-time continuation method for action-chunked flow-based VLA policies. Specifically, Legato initializes denoising from a schedule-shaped mixture of known actions and noise, exposing the model to partial action information. Moreover, Legato reshapes the learned flow dynamics to ensure that the denoising process remains consistent between training and inference under per-step guidance. Legato further uses randomized schedule condition during training to support varying inference delays and achieve controllable smoothness. Empirically, Legato produces smoother trajectories and reduces spurious multimodal switching during execution, leading to less hesitation and shorter task completion time. Extensive real-world experiments show that Legato consistently outperforms RTC across five manipulation tasks, achieving approximately 10% improvements in both trajectory smoothness and task completion time.
Point What You Mean: Visually Grounded Instruction Policy
Dec 22, 2025
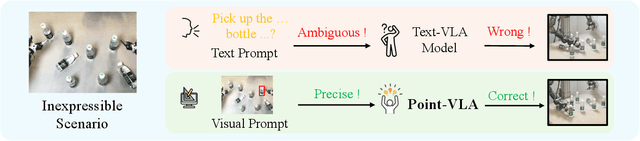
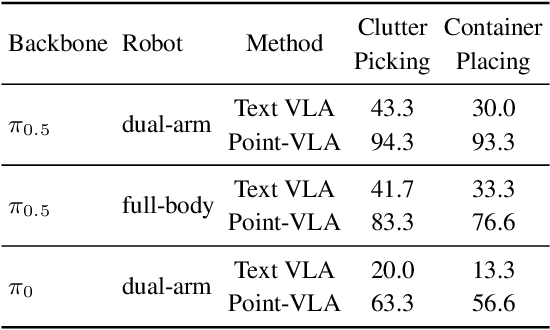
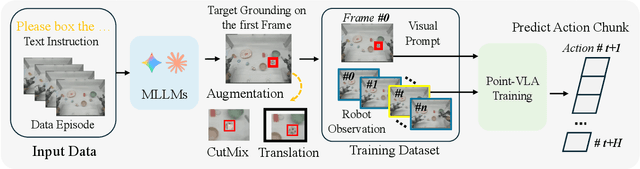
Vision-Language-Action (VLA) models align vision and language with embodied control, but their object referring ability remains limited when relying solely on text prompt, especially in cluttered or out-of-distribution (OOD) scenes. In this study, we introduce the Point-VLA, a plug-and-play policy that augments language instructions with explicit visual cues (e.g., bounding boxes) to resolve referential ambiguity and enable precise object-level grounding. To efficiently scale visually grounded datasets, we further develop an automatic data annotation pipeline requiring minimal human effort. We evaluate Point-VLA on diverse real-world referring tasks and observe consistently stronger performance than text-only instruction VLAs, particularly in cluttered or unseen-object scenarios, with robust generalization. These results demonstrate that Point-VLA effectively resolves object referring ambiguity through pixel-level visual grounding, achieving more generalizable embodied control.
GaGSL: Global-augmented Graph Structure Learning via Graph Information Bottleneck
Nov 07, 2024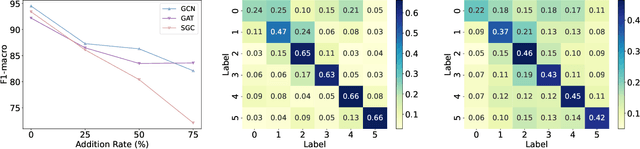
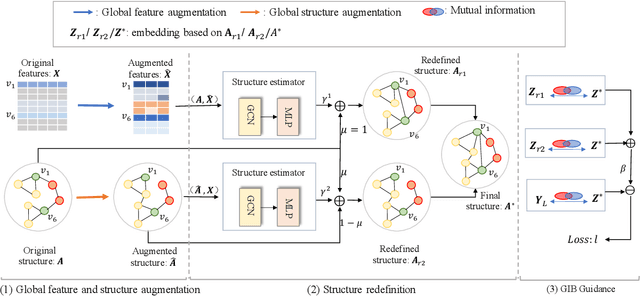
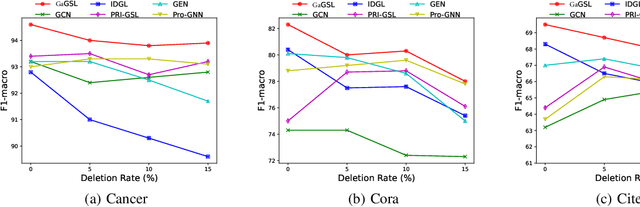
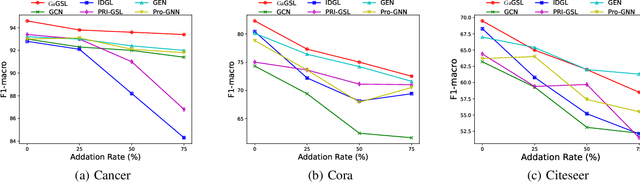
Graph neural networks (GNNs) are prominent for their effectiveness in processing graph data for semi-supervised node classification tasks. Most works of GNNs assume that the observed structure accurately represents the underlying node relationships. However, the graph structure is inevitably noisy or incomplete in reality, which can degrade the quality of graph representations. Therefore, it is imperative to learn a clean graph structure that balances performance and robustness. In this paper, we propose a novel method named \textit{Global-augmented Graph Structure Learning} (GaGSL), guided by the Graph Information Bottleneck (GIB) principle. The key idea behind GaGSL is to learn a compact and informative graph structure for node classification tasks. Specifically, to mitigate the bias caused by relying solely on the original structure, we first obtain augmented features and augmented structure through global feature augmentation and global structure augmentation. We then input the augmented features and augmented structure into a structure estimator with different parameters for optimization and re-definition of the graph structure, respectively. The redefined structures are combined to form the final graph structure. Finally, we employ GIB based on mutual information to guide the optimization of the graph structure to obtain the minimum sufficient graph structure. Comprehensive evaluations across a range of datasets reveal the outstanding performance and robustness of GaGSL compared with the state-of-the-art methods.
Graph Neural Networks with Coarse- and Fine-Grained Division for Mitigating Label Sparsity and Noise
Nov 06, 2024Graph Neural Networks (GNNs) have gained considerable prominence in semi-supervised learning tasks in processing graph-structured data, primarily owing to their message-passing mechanism, which largely relies on the availability of clean labels. However, in real-world scenarios, labels on nodes of graphs are inevitably noisy and sparsely labeled, significantly degrading the performance of GNNs. Exploring robust GNNs for semi-supervised node classification in the presence of noisy and sparse labels remains a critical challenge. Therefore, we propose a novel \textbf{G}raph \textbf{N}eural \textbf{N}etwork with \textbf{C}oarse- and \textbf{F}ine-\textbf{G}rained \textbf{D}ivision for mitigating label sparsity and noise, namely GNN-CFGD. The key idea of GNN-CFGD is reducing the negative impact of noisy labels via coarse- and fine-grained division, along with graph reconstruction. Specifically, we first investigate the effectiveness of linking unlabeled nodes to cleanly labeled nodes, demonstrating that this approach is more effective in combating labeling noise than linking to potentially noisy labeled nodes. Based on this observation, we introduce a Gaussian Mixture Model (GMM) based on the memory effect to perform a coarse-grained division of the given labels into clean and noisy labels. Next, we propose a clean labels oriented link that connects unlabeled nodes to cleanly labeled nodes, aimed at mitigating label sparsity and promoting supervision propagation. Furthermore, to provide refined supervision for noisy labeled nodes and additional supervision for unlabeled nodes, we fine-grain the noisy labeled and unlabeled nodes into two candidate sets based on confidence, respectively. Extensive experiments on various datasets demonstrate the superior effectiveness and robustness of GNN-CFGD.
DPAUC: Differentially Private AUC Computation in Federated Learning
Aug 25, 2022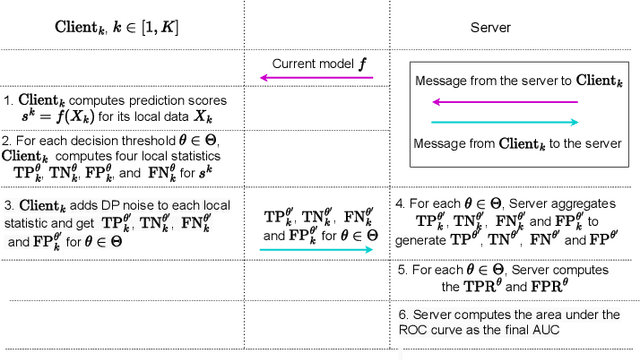

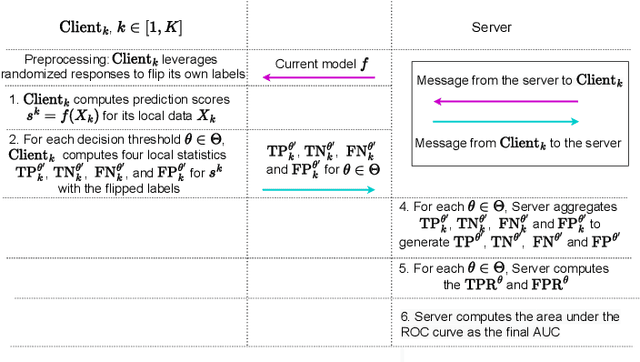
Federated learning (FL) has gained significant attention recently as a privacy-enhancing tool to jointly train a machine learning model by multiple participants. The prior work on FL has mostly studied how to protect label privacy during model training. However, model evaluation in FL might also lead to potential leakage of private label information. In this work, we propose an evaluation algorithm that can accurately compute the widely used AUC (area under the curve) metric when using the label differential privacy (DP) in FL. Through extensive experiments, we show our algorithms can compute accurate AUCs compared to the ground truth.
Differentially Private AUC Computation in Vertical Federated Learning
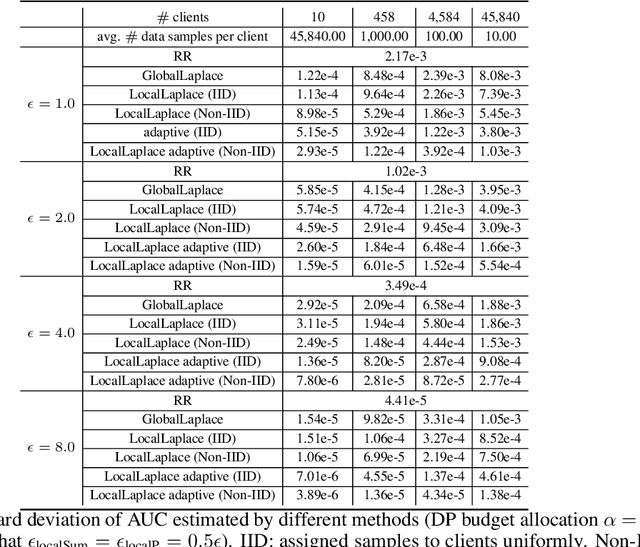
May 24, 2022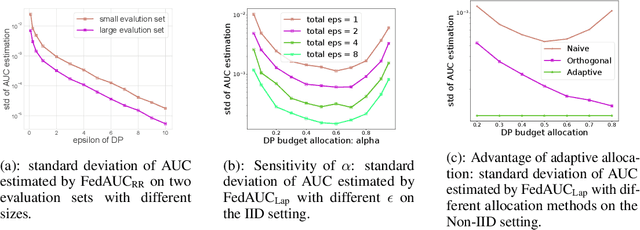
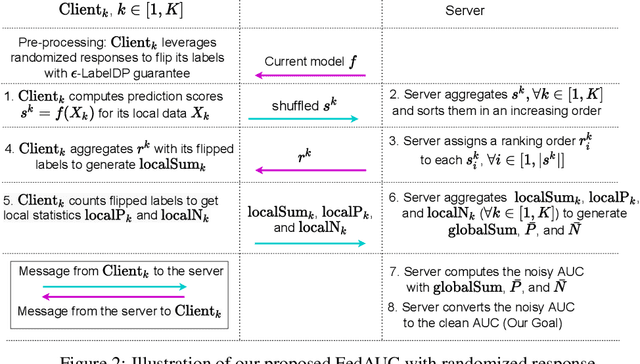
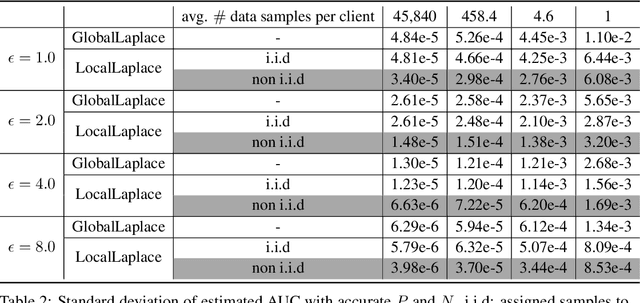
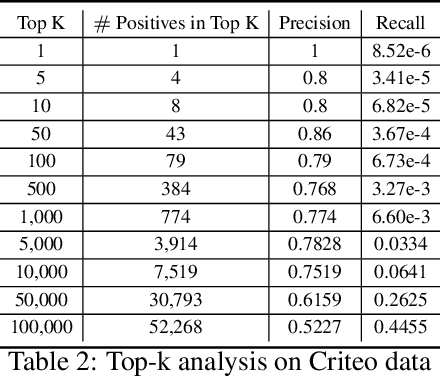
Federated learning has gained great attention recently as a privacy-enhancing tool to jointly train a machine learning model by multiple parties. As a sub-category, vertical federated learning (vFL) focuses on the scenario where features and labels are split into different parties. The prior work on vFL has mostly studied how to protect label privacy during model training. However, model evaluation in vFL might also lead to potential leakage of private label information. One mitigation strategy is to apply label differential privacy (DP) but it gives bad estimations of the true (non-private) metrics. In this work, we propose two evaluation algorithms that can more accurately compute the widely used AUC (area under curve) metric when using label DP in vFL. Through extensive experiments, we show our algorithms can achieve more accurate AUCs compared to the baselines.
Differentially Private Label Protection in Split Learning
Mar 04, 2022
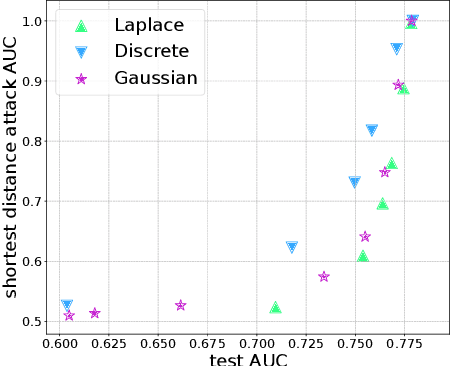
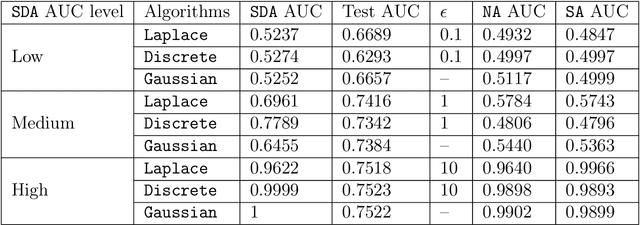

Split learning is a distributed training framework that allows multiple parties to jointly train a machine learning model over vertically partitioned data (partitioned by attributes). The idea is that only intermediate computation results, rather than private features and labels, are shared between parties so that raw training data remains private. Nevertheless, recent works showed that the plaintext implementation of split learning suffers from severe privacy risks that a semi-honest adversary can easily reconstruct labels. In this work, we propose \textsf{TPSL} (Transcript Private Split Learning), a generic gradient perturbation based split learning framework that provides provable differential privacy guarantee. Differential privacy is enforced on not only the model weights, but also the communicated messages in the distributed computation setting. Our experiments on large-scale real-world datasets demonstrate the robustness and effectiveness of \textsf{TPSL} against label leakage attacks. We also find that \textsf{TPSL} have a better utility-privacy trade-off than baselines.
Defending against Reconstruction Attack in Vertical Federated Learning
Jul 21, 2021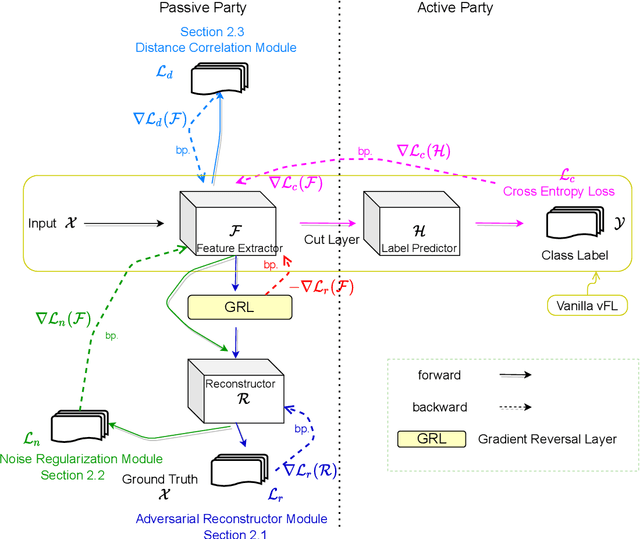
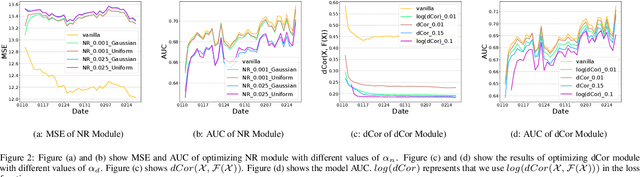
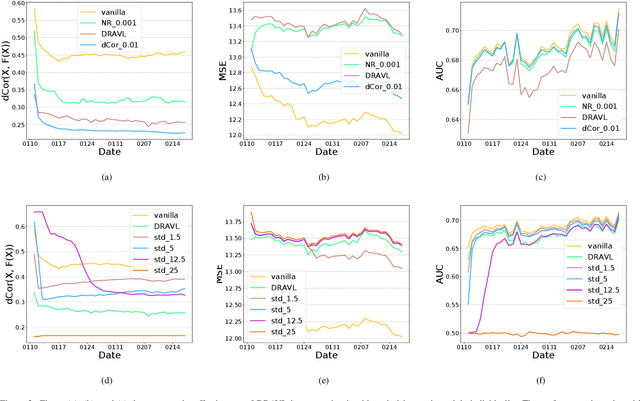
Recently researchers have studied input leakage problems in Federated Learning (FL) where a malicious party can reconstruct sensitive training inputs provided by users from shared gradient. It raises concerns about FL since input leakage contradicts the privacy-preserving intention of using FL. Despite a relatively rich literature on attacks and defenses of input reconstruction in Horizontal FL, input leakage and protection in vertical FL starts to draw researcher's attention recently. In this paper, we study how to defend against input leakage attacks in Vertical FL. We design an adversarial training-based framework that contains three modules: adversarial reconstruction, noise regularization, and distance correlation minimization. Those modules can not only be employed individually but also applied together since they are independent to each other. Through extensive experiments on a large-scale industrial online advertising dataset, we show our framework is effective in protecting input privacy while retaining the model utility.
Vertical Federated Learning without Revealing Intersection Membership
Jun 10, 2021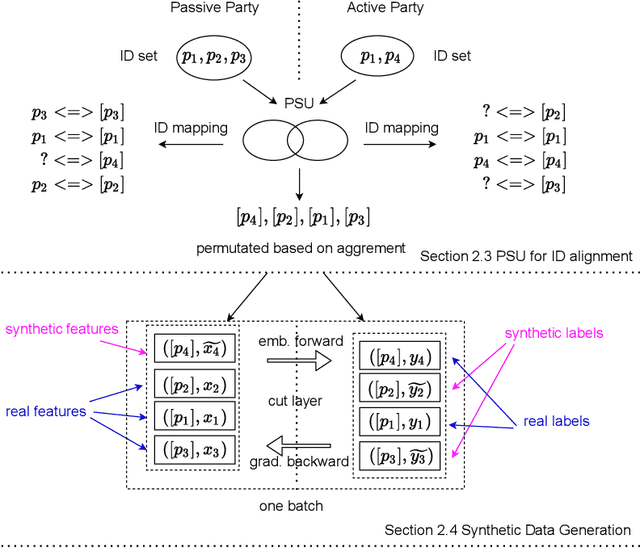

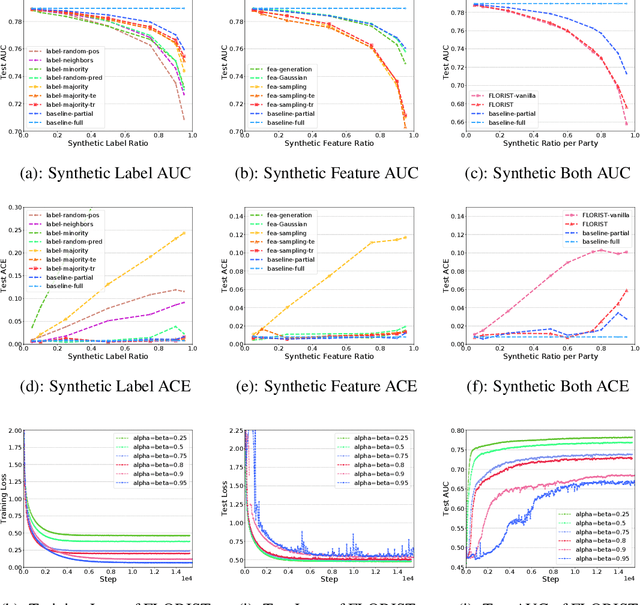

Vertical Federated Learning (vFL) allows multiple parties that own different attributes (e.g. features and labels) of the same data entity (e.g. a person) to jointly train a model. To prepare the training data, vFL needs to identify the common data entities shared by all parties. It is usually achieved by Private Set Intersection (PSI) which identifies the intersection of training samples from all parties by using personal identifiable information (e.g. email) as sample IDs to align data instances. As a result, PSI would make sample IDs of the intersection visible to all parties, and therefore each party can know that the data entities shown in the intersection also appear in the other parties, i.e. intersection membership. However, in many real-world privacy-sensitive organizations, e.g. banks and hospitals, revealing membership of their data entities is prohibited. In this paper, we propose a vFL framework based on Private Set Union (PSU) that allows each party to keep sensitive membership information to itself. Instead of identifying the intersection of all training samples, our PSU protocol generates the union of samples as training instances. In addition, we propose strategies to generate synthetic features and labels to handle samples that belong to the union but not the intersection. Through extensive experiments on two real-world datasets, we show our framework can protect the privacy of the intersection membership while maintaining the model utility.
Label Leakage and Protection in Two-party Split Learning
Feb 17, 2021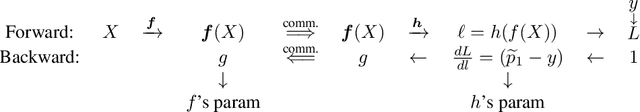
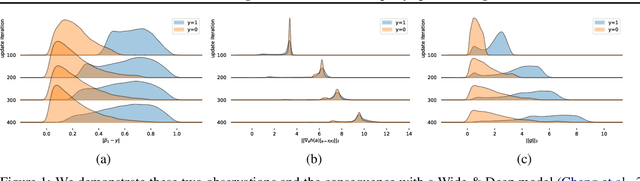
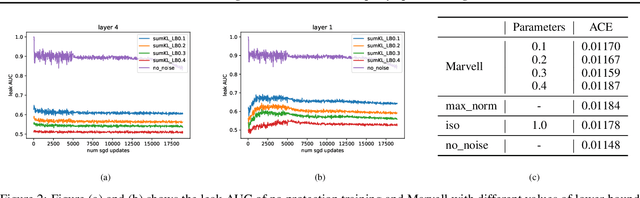
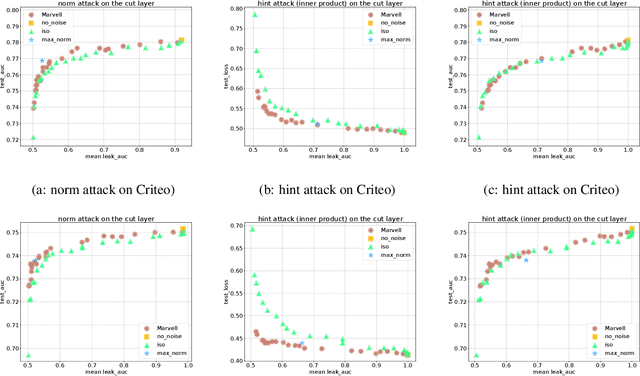
In vertical federated learning, two-party split learning has become an important topic and has found many applications in real business scenarios. However, how to prevent the participants' ground-truth labels from possible leakage is not well studied. In this paper, we consider answering this question in an imbalanced binary classification setting, a common case in online business applications. We first show that, norm attack, a simple method that uses the norm of the communicated gradients between the parties, can largely reveal the ground-truth labels from the participants. We then discuss several protection techniques to mitigate this issue. Among them, we have designed a principled approach that directly maximizes the worst-case error of label detection. This is proved to be more effective in countering norm attack and beyond. We experimentally demonstrate the competitiveness of our proposed method compared to several other baselines.