 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending against Reconstruction Attack in Vertical Federated Learning
Paper and Code
Jul 21, 2021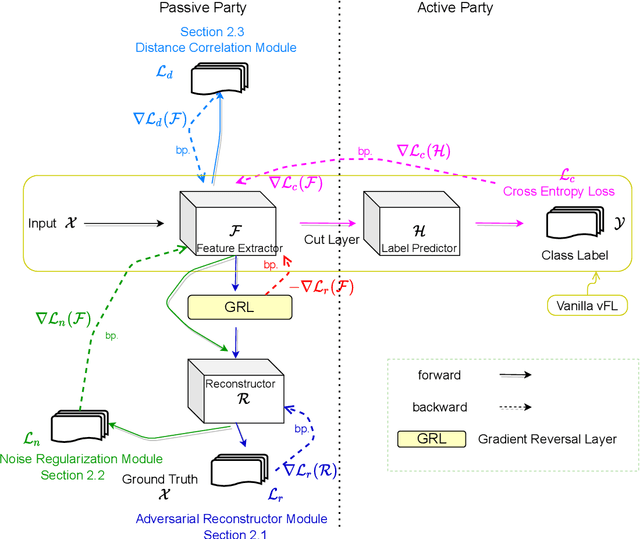
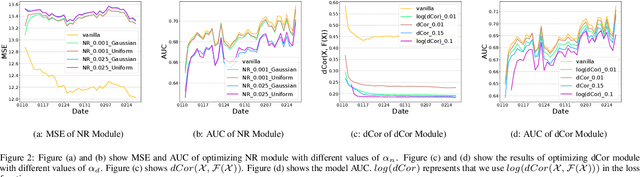
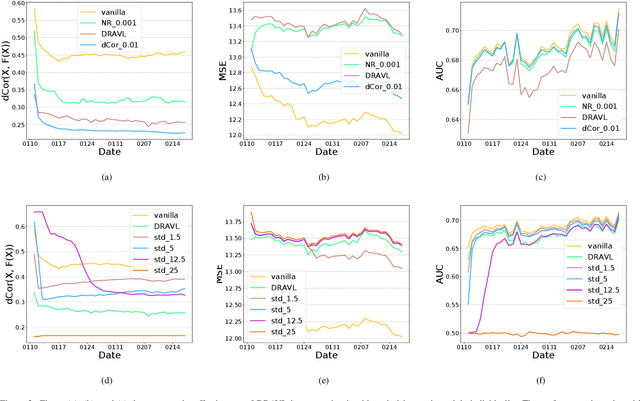
Recently researchers have studied input leakage problems in Federated Learning (FL) where a malicious party can reconstruct sensitive training inputs provided by users from shared gradient. It raises concerns about FL since input leakage contradicts the privacy-preserving intention of using FL. Despite a relatively rich literature on attacks and defenses of input reconstruction in Horizontal FL, input leakage and protection in vertical FL starts to draw researcher's attention recently. In this paper, we study how to defend against input leakage attacks in Vertical FL. We design an adversarial training-based framework that contains three modules: adversarial reconstruction, noise regularization, and distance correlation minimization. Those modules can not only be employed individually but also applied together since they are independent to each other. Through extensive experiments on a large-scale industrial online advertising dataset, we show our framework is effective in protecting input privacy while retaining the model utility.