 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Robust Multi-bit Text Watermark with LLM-based Paraphrasers
Dec 04, 2024We propose an imperceptible multi-bit text watermark embedded by paraphrasing with LLMs. We fine-tune a pair of LLM paraphrasers that are designed to behave differently so that their paraphrasing difference reflected in the text semantics can be identified by a trained decoder. To embed our multi-bit watermark, we use two paraphrasers alternatively to encode the pre-defined binary code at the sentence level. Then we use a text classifier as the decoder to decode each bit of the watermark. Through extensive experiments, we show that our watermarks can achieve over 99.99\% detection AUC with small (1.1B) text paraphrasers while keeping the semantic information of the original sentence. More importantly, our pipeline is robust under word substitution and sentence paraphrasing perturbations and generalizes well to out-of-distributional data. We also show the stealthiness of our watermark with LLM-based evaluation. We open-source the code: https://github.com/xiaojunxu/multi-bit-text-watermark.
ACC-Debate: An Actor-Critic Approach to Multi-Agent Debate
Nov 04, 2024Large language models (LLMs) have demonstrated a remarkable ability to serve as general-purpose tools for various language-based tasks. Recent works have demonstrated that the efficacy of such models can be improved through iterative dialog between multiple models, frequently referred to as multi-agent debate (MAD). While debate shows promise as a means of improving model efficacy, most works in this area treat debate as an emergent behavior, rather than a learned behavior. In doing so, current debate frameworks rely on collaborative behaviors to have been sufficiently trained into off-the-shelf models. To address this limitation, we propose ACC-Debate, an Actor-Critic based learning framework to produce a two-agent team specialized in debate. We demonstrate that ACC-Debate outperforms SotA debate techniques on a wide array of benchmarks.
Toward Optimal LLM Alignments Using Two-Player Games
Jun 16, 2024



The standard Reinforcement Learning from Human Feedback (RLHF) framework primarily focuses on optimizing the performance of large language models using pre-collected prompts. However, collecting prompts that provide comprehensive coverage is both tedious and challenging, and often fails to include scenarios that LLMs need to improve on the most. In this paper, we investigate alignment through the lens of two-agent games, involving iterative interactions between an adversarial and a defensive agent. The adversarial agent's task at each step is to generate prompts that expose the weakness of the defensive agent. In return, the defensive agent seeks to improve its responses to these newly identified prompts it struggled with, based on feedback from the reward model. We theoretically demonstrate that this iterative reinforcement learning optimization converges to a Nash Equilibrium for the game induced by the agents. Experimental results in safety scenarios demonstrate that learning in such a competitive environment not only fully trains agents but also leads to policies with enhanced generalization capabilities for both adversarial and defensive agents.
Label Smoothing Improves Machine Unlearning
Jun 11, 2024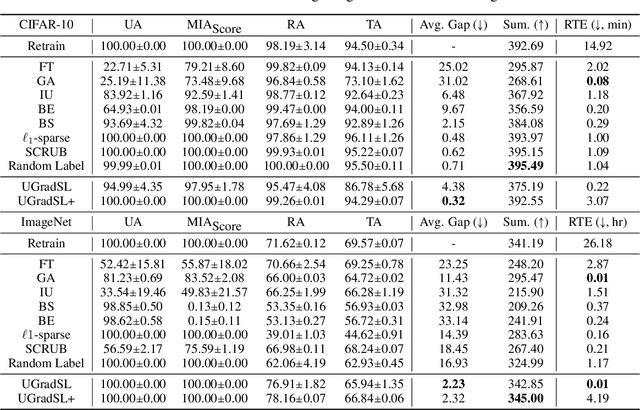
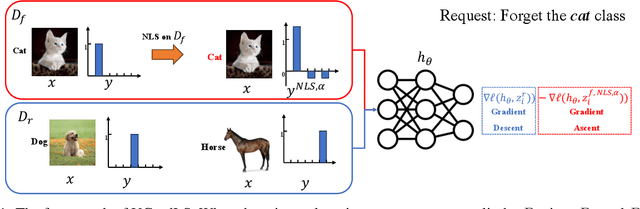
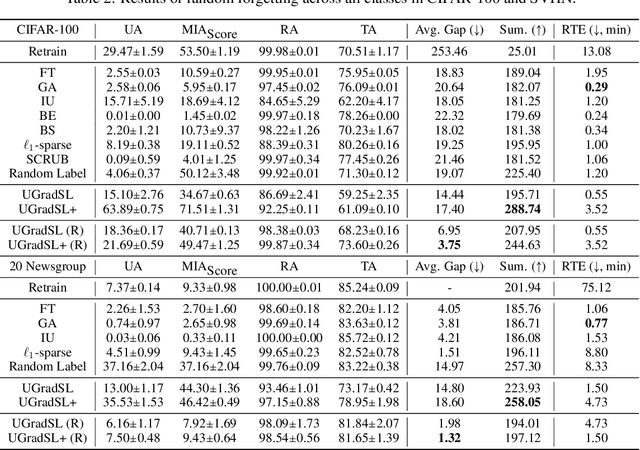
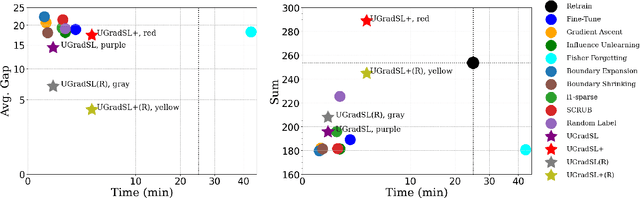
The objective of machine unlearning (MU) is to eliminate previously learned data from a model. However, it is challenging to strike a balance between computation cost and performance when using existing MU techniques. Taking inspiration from the influence of label smoothing on model confidence and differential privacy, we propose a simple gradient-based MU approach that uses an inverse process of label smoothing. This work introduces UGradSL, a simple, plug-and-play MU approach that uses smoothed labels. We provide theoretical analyses demonstrating why properly introducing label smoothing improves MU performance. We conducted extensive experiments on six datasets of various sizes and different modalities, demonstrating the effectiveness and robustness of our proposed method. The consistent improvement in MU performance is only at a marginal cost of additional computations. For instance, UGradSL improves over the gradient ascent MU baseline by 66% unlearning accuracy without sacrificing unlearning efficiency.
Improving Reinforcement Learning from Human Feedback Using Contrastive Rewards
Mar 14, 2024



Reinforcement learning from human feedback (RLHF) is the mainstream paradigm used to align large language models (LLMs) with human preferences. Yet existing RLHF heavily relies on accurate and informative reward models, which are vulnerable and sensitive to noise from various sources, e.g. human labeling errors, making the pipeline fragile. In this work, we improve the effectiveness of the reward model by introducing a penalty term on the reward, named as \textit{contrastive rewards}. %Contrastive rewards Our approach involves two steps: (1) an offline sampling step to obtain responses to prompts that serve as baseline calculation and (2) a contrastive reward calculated using the baseline responses and used in the Proximal Policy Optimization (PPO) step. We show that contrastive rewards enable the LLM to penalize reward uncertainty, improve robustness, encourage improvement over baselines, calibrate according to task difficulty, and reduce variance in PPO. We show empirically contrastive rewards can improve RLHF substantially, evaluated by both GPTs and humans, and our method consistently outperforms strong baselines.
Learning to Watermark LLM-generated Text via Reinforcement Learning
Mar 13, 2024



We study how to watermark LLM outputs, i.e. embedding algorithmically detectable signals into LLM-generated text to track misuse. Unlike the current mainstream methods that work with a fixed LLM, we expand the watermark design space by including the LLM tuning stage in the watermark pipeline. While prior works focus on token-level watermark that embeds signals into the output, we design a model-level watermark that embeds signals into the LLM weights, and such signals can be detected by a paired detector. We propose a co-training framework based on reinforcement learning that iteratively (1) trains a detector to detect the generated watermarked text and (2) tunes the LLM to generate text easily detectable by the detector while keeping its normal utility. We empirically show that our watermarks are more accurate, robust, and adaptable (to new attacks). It also allows watermarked model open-sourcing. In addition, if used together with alignment, the extra overhead introduced is low - only training an extra reward model (i.e. our detector). We hope our work can bring more effort into studying a broader watermark design that is not limited to working with a fixed LLM. We open-source the code: https://github.com/xiaojunxu/learning-to-watermark-llm .
Fair Classifiers Without Fair Training: An Influence-Guided Data Sampling Approach
Feb 20, 2024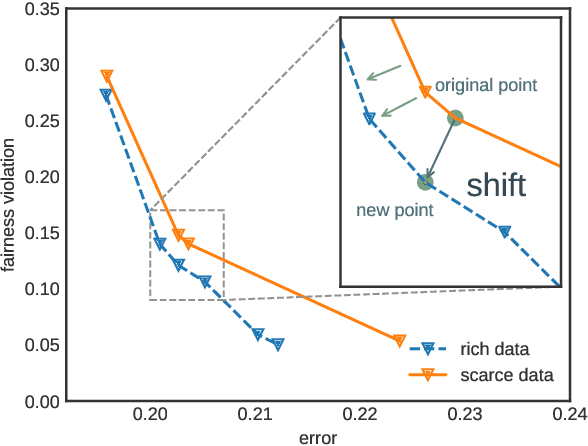
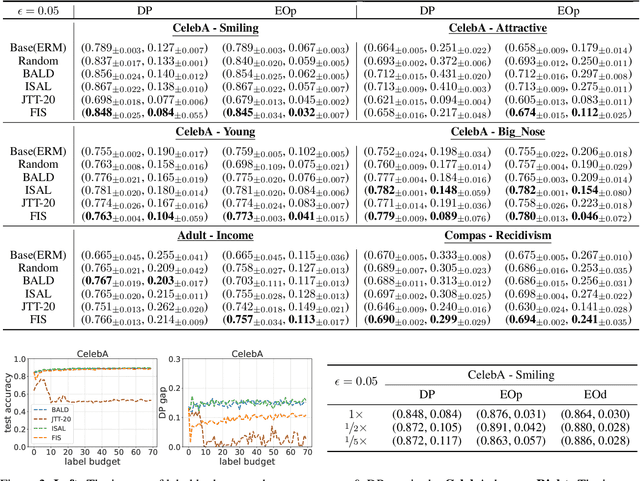
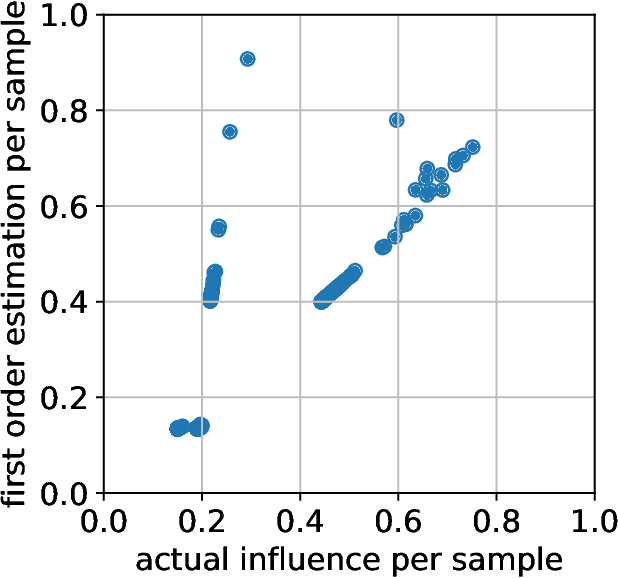
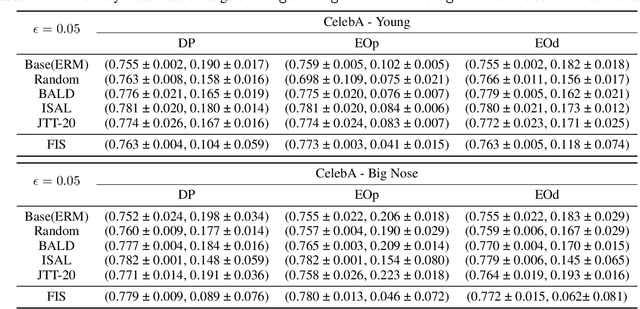
A fair classifier should ensure the benefit of people from different groups, while the group information is often sensitive and unsuitable for model training. Therefore, learning a fair classifier but excluding sensitive attributes in the training dataset is important. In this paper, we study learning fair classifiers without implementing fair training algorithms to avoid possible leakage of sensitive information. Our theoretical analyses validate the possibility of this approach, that traditional training on a dataset with an appropriate distribution shift can reduce both the upper bound for fairness disparity and model generalization error, indicating that fairness and accuracy can be improved simultaneously with simply traditional training. We then propose a tractable solution to progressively shift the original training data during training by sampling influential data, where the sensitive attribute of new data is not accessed in sampling or used in training. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
Measuring and Reducing LLM Hallucination without Gold-Standard Answers via Expertise-Weighting
Feb 16, 2024LLM hallucination, i.e. generating factually incorrect yet seemingly convincing answers, is currently a major threat to the trustworthiness and reliability of LLMs. The first step towards solving this complicated problem is to measure it. However, existing hallucination metrics require to have a benchmark dataset with gold-standard answers, i.e. "best" or "correct" answers written by humans. Such requirement makes hallucination measurement costly and prone to human errors. In this work, we propose Factualness Evaluations via Weighting LLMs (FEWL), the first hallucination metric that is specifically designed for the scenario when gold-standard answers are absent. FEWL leverages the answers from off-the-shelf LLMs that serve as a proxy of gold-standard answers. The key challenge is how to quantify the expertise of reference LLMs resourcefully. We show FEWL has certain theoretical guarantees and demonstrate empirically it gives more accurate hallucination measures than naively using reference LLMs. We also show how to leverage FEWL to reduce hallucination through both in-context learning and supervised finetuning. Last, we build a large-scale benchmark dataset to facilitate LLM hallucination research.
Rethinking Machine Unlearning for Large Language Models
Feb 15, 2024We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.