 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Classifiers Without Fair Training: An Influence-Guided Data Sampling Approach
Paper and Code
Feb 20, 2024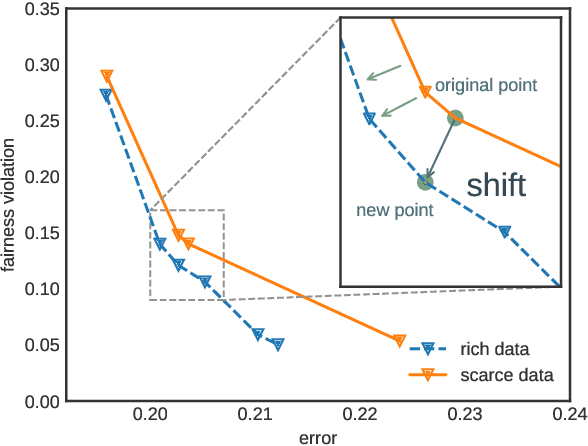
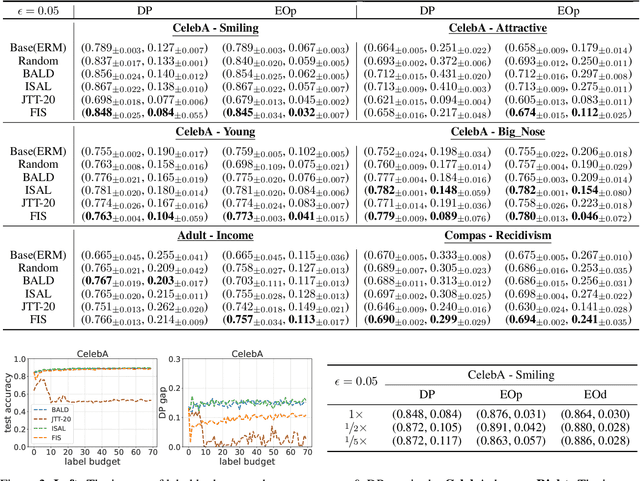
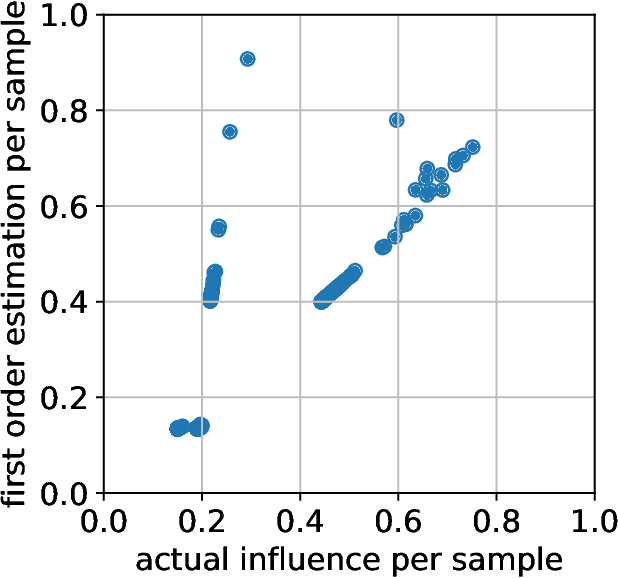
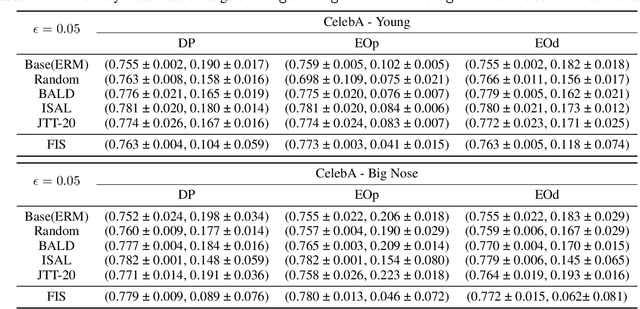
A fair classifier should ensure the benefit of people from different groups, while the group information is often sensitive and unsuitable for model training. Therefore, learning a fair classifier but excluding sensitive attributes in the training dataset is important. In this paper, we study learning fair classifiers without implementing fair training algorithms to avoid possible leakage of sensitive information. Our theoretical analyses validate the possibility of this approach, that traditional training on a dataset with an appropriate distribution shift can reduce both the upper bound for fairness disparity and model generalization error, indicating that fairness and accuracy can be improved simultaneously with simply traditional training. We then propose a tractable solution to progressively shift the original training data during training by sampling influential data, where the sensitive attribute of new data is not accessed in sampling or used in training. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.