 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrass: Compute Efficient Low-Memory LLM Training with Structured Sparse Gradients
Jun 25, 2024



Large language model (LLM) training and finetuning are often bottlenecked by limited GPU memory. While existing projection-based optimization methods address this by projecting gradients into a lower-dimensional subspace to reduce optimizer state memory, they typically rely on dense projection matrices, which can introduce computational and memory overheads. In this work, we propose Grass (GRAdient Stuctured Sparsification), a novel approach that leverages sparse projections to transform gradients into structured sparse updates. This design not only significantly reduces memory usage for optimizer states but also minimizes gradient memory footprint, computation, and communication costs, leading to substantial throughput improvements. Extensive experiments on pretraining and finetuning tasks demonstrate that Grass achieves competitive performance to full-rank training and existing projection-based methods. Notably, Grass enables half-precision pretraining of a 13B parameter LLaMA model on a single 40GB A100 GPU--a feat infeasible for previous methods--and yields up to a $2\times$ throughput improvement on an 8-GPU system. Code can be found at https://github.com/aashiqmuhamed/GRASS .
OmniPred: Language Models as Universal Regressors
Mar 04, 2024Over the broad landscape of experimental design, regression has been a powerful tool to accurately predict the outcome metrics of a system or model given a set of parameters, but has been traditionally restricted to methods which are only applicable to a specific task. In this paper, we propose OmniPred, a framework for training language models as universal end-to-end regressors over $(x,y)$ evaluation data from diverse real world experiments. Using data sourced from Google Vizier, one of the largest blackbox optimization databases in the world, our extensive experiments demonstrate that through only textual representations of mathematical parameters and values, language models are capable of very precise numerical regression, and if given the opportunity to train over multiple tasks, can significantly outperform traditional regression models.
Noise-Reuse in Online Evolution Strategies
Apr 21, 2023



Online evolution strategies have become an attractive alternative to automatic differentiation (AD) due to their ability to handle chaotic and black-box loss functions, while also allowing more frequent gradient updates than vanilla Evolution Strategies (ES). In this work, we propose a general class of unbiased online evolution strategies. We analytically and empirically characterize the variance of this class of gradient estimators and identify the one with the least variance, which we term Noise-Reuse Evolution Strategies (NRES). Experimentally, we show that NRES results in faster convergence than existing AD and ES methods in terms of wall-clock speed and total number of unroll steps across a variety of applications, including learning dynamical systems, meta-training learned optimizers, and reinforcement learning.
Lessons from Chasing Few-Shot Learning Benchmarks: Rethinking the Evaluation of Meta-Learning Methods
Feb 23, 2021
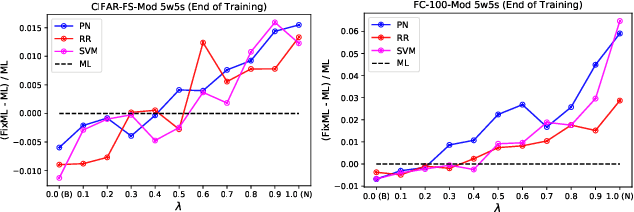
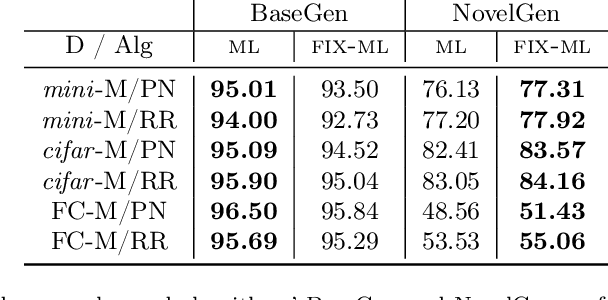

In this work we introduce a simple baseline for meta-learning. Our unconventional method, FIX-ML, reduces task diversity by keeping support sets fixed across tasks, and consistently improves the performance of meta-learning methods on popular few-shot learning benchmarks. However, in exploring the reason for this counter-intuitive phenomenon, we unearth a series of questions and concerns about meta-learning evaluation practices. We explore two possible goals of meta-learning: to develop methods that generalize (i) to the same task distribution that generates the training set (in-distribution), or (ii) to new, unseen task distributions (out-of-distribution). Through careful analyses, we show that for each of these two goals, current few-shot learning benchmarks have potential pitfalls in 1) performing model selection and hyperparameter tuning for a given meta-learning method and 2) comparing the performance of different meta-learning methods. Our results highlight that in order to reason about progress in this space, it is necessary to provide a clearer description of the goals of meta-learning, and to develop more appropriate corresponding evaluation strategies.
Label Leakage and Protection in Two-party Split Learning
Feb 17, 2021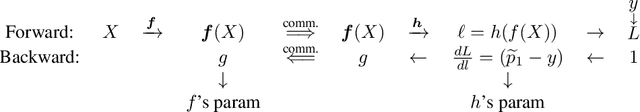
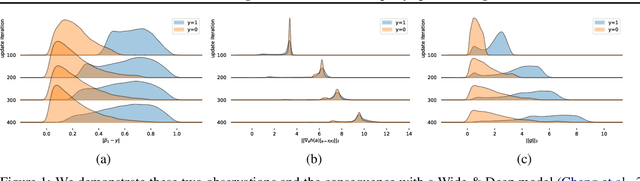
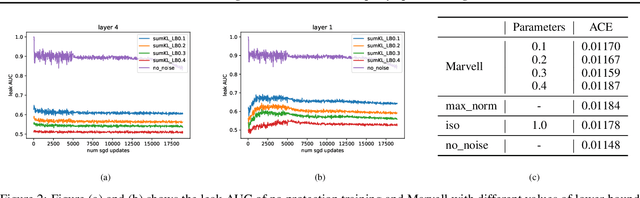
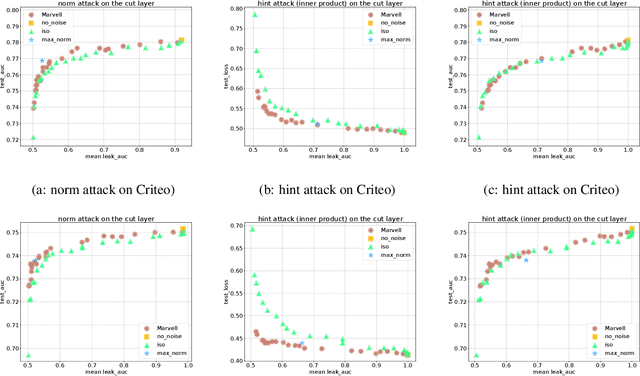
In vertical federated learning, two-party split learning has become an important topic and has found many applications in real business scenarios. However, how to prevent the participants' ground-truth labels from possible leakage is not well studied. In this paper, we consider answering this question in an imbalanced binary classification setting, a common case in online business applications. We first show that, norm attack, a simple method that uses the norm of the communicated gradients between the parties, can largely reveal the ground-truth labels from the participants. We then discuss several protection techniques to mitigate this issue. Among them, we have designed a principled approach that directly maximizes the worst-case error of label detection. This is proved to be more effective in countering norm attack and beyond. We experimentally demonstrate the competitiveness of our proposed method compared to several other baselines.
Is Support Set Diversity Necessary for Meta-Learning?
Nov 28, 2020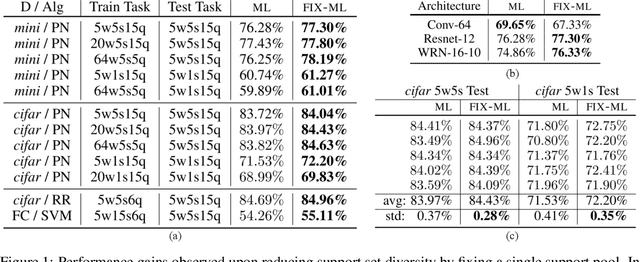
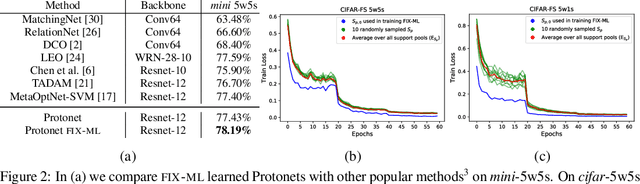
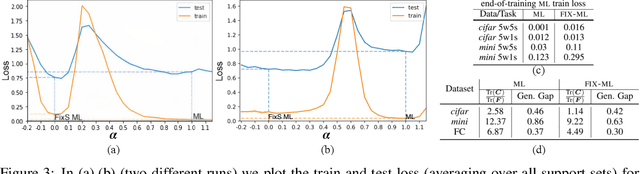
Meta-learning is a popular framework for learning with limited data in which an algorithm is produced by training over multiple few-shot learning tasks. For classification problems, these tasks are typically constructed by sampling a small number of support and query examples from a subset of the classes. While conventional wisdom is that task diversity should improve the performance of meta-learning, in this work we find evidence to the contrary: we propose a modification to traditional meta-learning approaches in which we keep the support sets fixed across tasks, thus reducing task diversity. Surprisingly, we find that not only does this modification not result in adverse effects, it almost always improves the performance for a variety of datasets and meta-learning methods. We also provide several initial analyses to understand this phenomenon. Our work serves to: (i) more closely investigate the effect of support set construction for the problem of meta-learning, and (ii) suggest a simple, general, and competitive baseline for few-shot learning.
Interpretable Image Recognition with Hierarchical Prototypes
Jun 25, 2019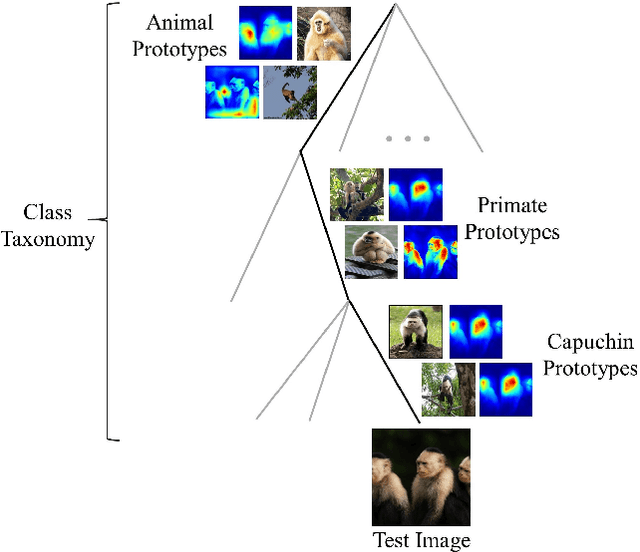
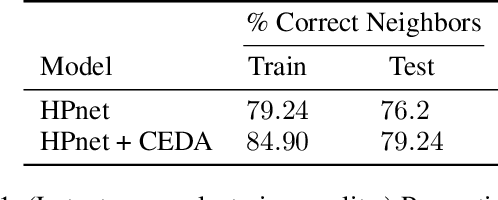

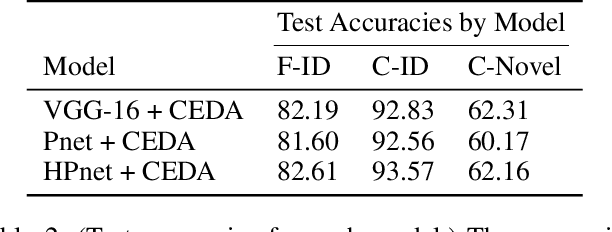
Vision models are interpretable when they classify objects on the basis of features that a person can directly understand. Recently, methods relying on visual feature prototypes have been developed for this purpose. However, in contrast to how humans categorize objects, these approaches have not yet made use of any taxonomical organization of class labels. With such an approach, for instance, we may see why a chimpanzee is classified as a chimpanzee, but not why it was considered to be a primate or even an animal. In this work we introduce a model that uses hierarchically organized prototypes to classify objects at every level in a predefined taxonomy. Hence, we may find distinct explanations for the prediction an image receives at each level of the taxonomy. The hierarchical prototypes enable the model to perform another important task: interpretably classifying images from previously unseen classes at the level of the taxonomy to which they correctly relate, e.g. classifying a hand gun as a weapon, when the only weapons in the training data are rifles. With a subset of ImageNet, we test our model against its counterpart black-box model on two tasks: 1) classification of data from familiar classes, and 2) classification of data from previously unseen classes at the appropriate level in the taxonomy. We find that our model performs approximately as well as its counterpart black-box model while allowing for each classification to be interpreted.
This looks like that: deep learning for interpretable image recognition
Jun 27, 2018
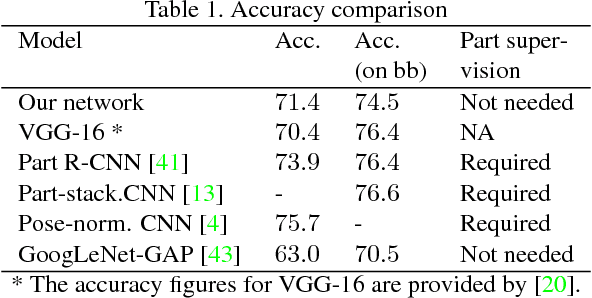
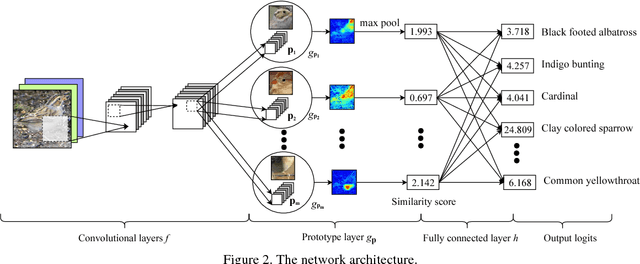
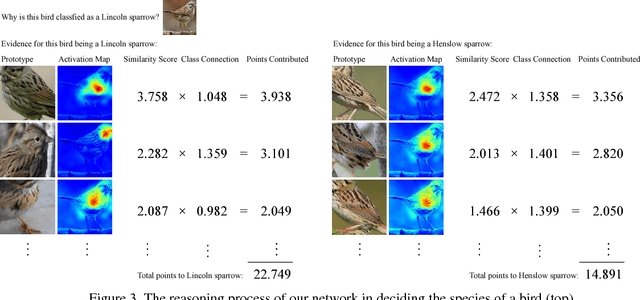
When we are faced with challenging image classification tasks, we often explain our reasoning by dissecting the image, and pointing out prototypical aspects of one class or another. The mounting evidence for each of the classes helps us make our final decision. In this work, we introduce a deep network architecture that reasons in a similar way: the network dissects the image by finding prototypical parts, and combines evidence from the prototypes to make a final classification. The algorithm thus reasons in a way that is qualitatively similar to the way ornithologists, physicians, geologists, architects, and others would explain to people on how to solve challenging image classification tasks. The network uses only image-level labels for training, meaning that there are no labels for parts of images. We demonstrate the method on the CIFAR-10 dataset and 10 classes from the CUB-200-2011 dataset.
Deep Learning for Case-Based Reasoning through Prototypes: A Neural Network that Explains Its Predictions
Nov 21, 2017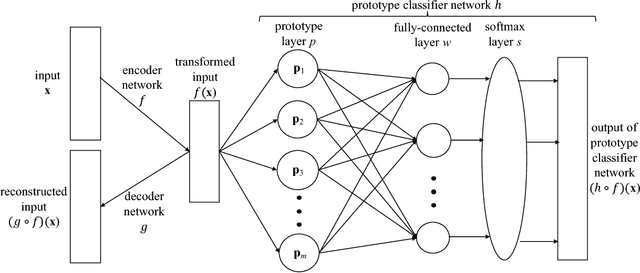
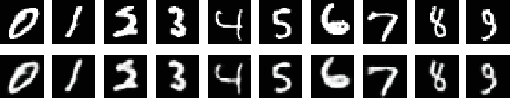

Deep neural networks are widely used for classification. These deep models often suffer from a lack of interpretability -- they are particularly difficult to understand because of their non-linear nature. As a result, neural networks are often treated as "black box" models, and in the past, have been trained purely to optimize the accuracy of predictions. In this work, we create a novel network architecture for deep learning that naturally explains its own reasoning for each prediction. This architecture contains an autoencoder and a special prototype layer, where each unit of that layer stores a weight vector that resembles an encoded training input. The encoder of the autoencoder allows us to do comparisons within the latent space, while the decoder allows us to visualize the learned prototypes. The training objective has four terms: an accuracy term, a term that encourages every prototype to be similar to at least one encoded input, a term that encourages every encoded input to be close to at least one prototype, and a term that encourages faithful reconstruction by the autoencoder. The distances computed in the prototype layer are used as part of the classification process. Since the prototypes are learned during training, the learned network naturally comes with explanations for each prediction, and the explanations are loyal to what the network actually computes.