 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LLM Embeddings for Regression
Nov 22, 2024



With the rise of large language models (LLMs) for flexibly processing information as strings, a natural application is regression, specifically by preprocessing string representations into LLM embeddings as downstream features for metric prediction. In this paper, we provide one of the first comprehensive investigations into embedding-based regression and demonstrate that LLM embeddings as features can be better for high-dimensional regression tasks than using traditional feature engineering. This regression performance can be explained in part due to LLM embeddings over numeric data inherently preserving Lipschitz continuity over the feature space. Furthermore, we quantify the contribution of different model effects, most notably model size and language understanding, which we find surprisingly do not always improve regression performance.
Predicting from Strings: Language Model Embeddings for Bayesian Optimization
Oct 15, 2024


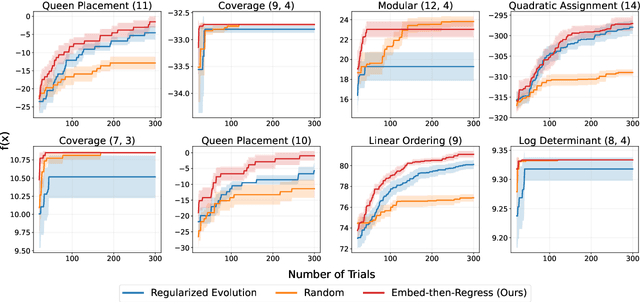
Bayesian Optimization is ubiquitous in the field of experimental design and blackbox optimization for improving search efficiency, but has been traditionally restricted to regression models which are only applicable to fixed search spaces and tabular input features. We propose Embed-then-Regress, a paradigm for applying in-context regression over string inputs, through the use of string embedding capabilities of pretrained language models. By expressing all inputs as strings, we are able to perform general-purpose regression for Bayesian Optimization over various domains including synthetic, combinatorial, and hyperparameter optimization, obtaining comparable results to state-of-the-art Gaussian Process-based algorithms. Code can be found at https://github.com/google-research/optformer/tree/main/optformer/embed_then_regress.
OmniPred: Language Models as Universal Regressors
Mar 04, 2024Over the broad landscape of experimental design, regression has been a powerful tool to accurately predict the outcome metrics of a system or model given a set of parameters, but has been traditionally restricted to methods which are only applicable to a specific task. In this paper, we propose OmniPred, a framework for training language models as universal end-to-end regressors over $(x,y)$ evaluation data from diverse real world experiments. Using data sourced from Google Vizier, one of the largest blackbox optimization databases in the world, our extensive experiments demonstrate that through only textual representations of mathematical parameters and values, language models are capable of very precise numerical regression, and if given the opportunity to train over multiple tasks, can significantly outperform traditional regression models.