 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting from Strings: Language Model Embeddings for Bayesian Optimization
Oct 15, 2024


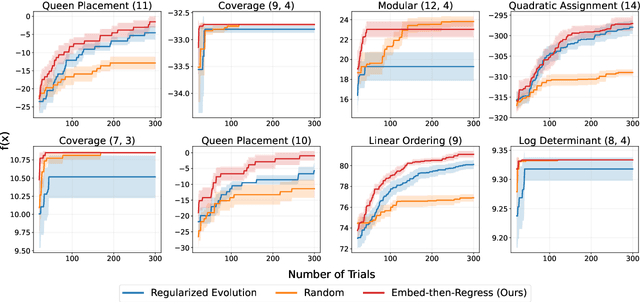
Bayesian Optimization is ubiquitous in the field of experimental design and blackbox optimization for improving search efficiency, but has been traditionally restricted to regression models which are only applicable to fixed search spaces and tabular input features. We propose Embed-then-Regress, a paradigm for applying in-context regression over string inputs, through the use of string embedding capabilities of pretrained language models. By expressing all inputs as strings, we are able to perform general-purpose regression for Bayesian Optimization over various domains including synthetic, combinatorial, and hyperparameter optimization, obtaining comparable results to state-of-the-art Gaussian Process-based algorithms. Code can be found at https://github.com/google-research/optformer/tree/main/optformer/embed_then_regress.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Guided Evolution with Binary Discriminators for ML Program Search
Feb 08, 2024How to automatically design better machine learning programs is an open problem within AutoML. While evolution has been a popular tool to search for better ML programs, using learning itself to guide the search has been less successful and less understood on harder problems but has the promise to dramatically increase the speed and final performance of the optimization process. We propose guiding evolution with a binary discriminator, trained online to distinguish which program is better given a pair of programs. The discriminator selects better programs without having to perform a costly evaluation and thus speed up the convergence of evolution. Our method can encode a wide variety of ML components including symbolic optimizers, neural architectures, RL loss functions, and symbolic regression equations with the same directed acyclic graph representation. By combining this representation with modern GNNs and an adaptive mutation strategy, we demonstrate our method can speed up evolution across a set of diverse problems including a 3.7x speedup on the symbolic search for ML optimizers and a 4x speedup for RL loss functions.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Unified Functional Hashing in Automatic Machine Learning
Feb 10, 2023



The field of Automatic Machine Learning (AutoML) has recently attained impressive results, including the discovery of state-of-the-art machine learning solutions, such as neural image classifiers. This is often done by applying an evolutionary search method, which samples multiple candidate solutions from a large space and evaluates the quality of each candidate through a long training process. As a result, the search tends to be slow. In this paper, we show that large efficiency gains can be obtained by employing a fast unified functional hash, especially through the functional equivalence caching technique, which we also present. The central idea is to detect by hashing when the search method produces equivalent candidates, which occurs very frequently, and this way avoid their costly re-evaluation. Our hash is "functional" in that it identifies equivalent candidates even if they were represented or coded differently, and it is "unified" in that the same algorithm can hash arbitrary representations; e.g. compute graphs, imperative code, or lambda functions. As evidence, we show dramatic improvements on multiple AutoML domains, including neural architecture search and algorithm discovery. Finally, we consider the effect of hash collisions, evaluation noise, and search distribution through empirical analysis. Altogether, we hope this paper may serve as a guide to hashing techniques in AutoML.
Understanding HTML with Large Language Models
Oct 08, 2022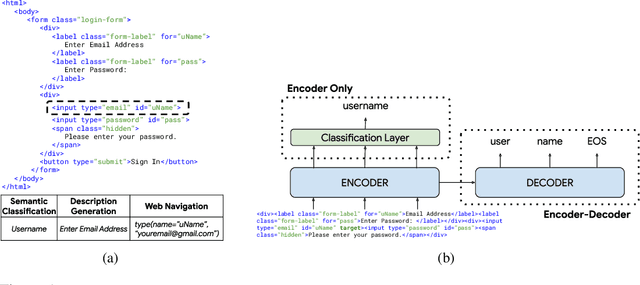

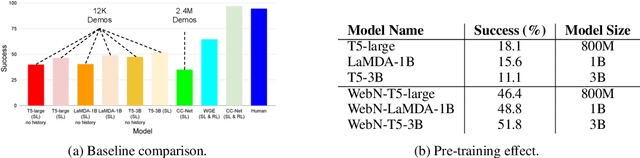
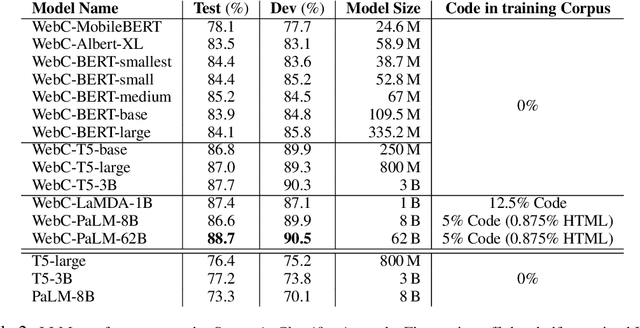
Large language models (LLMs) have shown exceptional performance on a variety of natural language tasks. Yet, their capabilities for HTML understanding -- i.e., parsing the raw HTML of a webpage, with applications to automation of web-based tasks, crawling, and browser-assisted retrieval -- have not been fully explored. We contribute HTML understanding models (fine-tuned LLMs) and an in-depth analysis of their capabilities under three tasks: (i) Semantic Classification of HTML elements, (ii) Description Generation for HTML inputs, and (iii) Autonomous Web Navigation of HTML pages. While previous work has developed dedicated architectures and training procedures for HTML understanding, we show that LLMs pretrained on standard natural language corpora transfer remarkably well to HTML understanding tasks. For instance, fine-tuned LLMs are 12% more accurate at semantic classification compared to models trained exclusively on the task dataset. Moreover, when fine-tuned on data from the MiniWoB benchmark, LLMs successfully complete 50% more tasks using 192x less data compared to the previous best supervised model. Out of the LLMs we evaluate, we show evidence that T5-based models are ideal due to their bidirectional encoder-decoder architecture. To promote further research on LLMs for HTML understanding, we create and open-source a large-scale HTML dataset distilled and auto-labeled from CommonCrawl.
Multi-objective evolution for Generalizable Policy Gradient Algorithms
Apr 08, 2022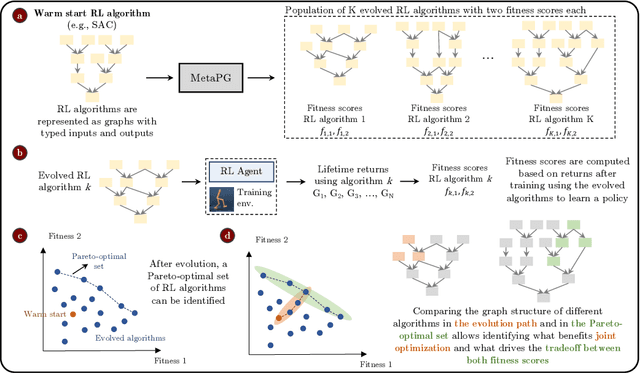
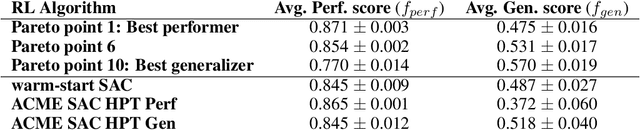
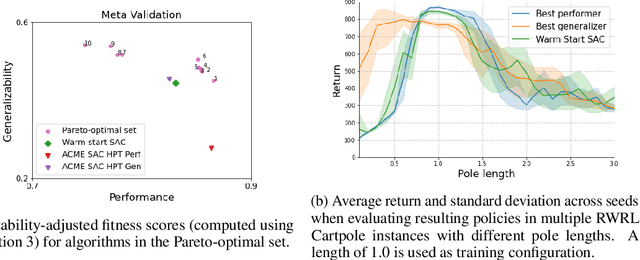
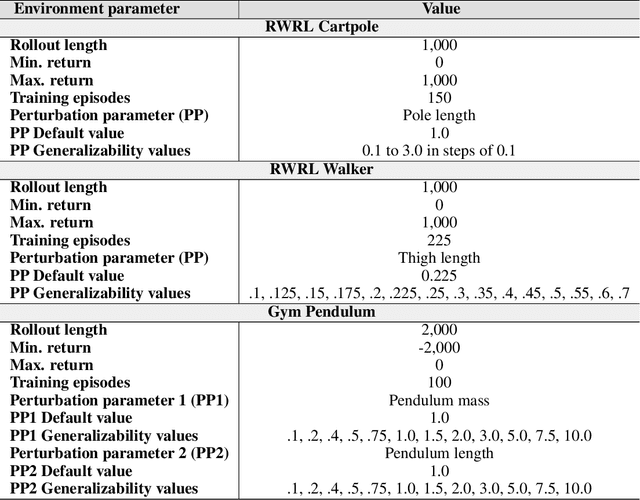
Performance, generalizability, and stability are three Reinforcement Learning (RL) challenges relevant to many practical applications in which they present themselves in combination. Still, state-of-the-art RL algorithms fall short when addressing multiple RL objectives simultaneously and current human-driven design practices might not be well-suited for multi-objective RL. In this paper we present MetaPG, an evolutionary method that discovers new RL algorithms represented as graphs, following a multi-objective search criteria in which different RL objectives are encoded in separate fitness scores. Our findings show that, when using a graph-based implementation of Soft Actor-Critic (SAC) to initialize the population, our method is able to find new algorithms that improve upon SAC's performance and generalizability by 3% and 17%, respectively, and reduce instability up to 65%. In addition, we analyze the graph structure of the best algorithms in the population and offer an interpretation of specific elements that help trading performance for generalizability and vice versa. We validate our findings in three different continuous control tasks: RWRL Cartpole, RWRL Walker, and Gym Pendulum.
Environment Generation for Zero-Shot Compositional Reinforcement Learning
Jan 21, 2022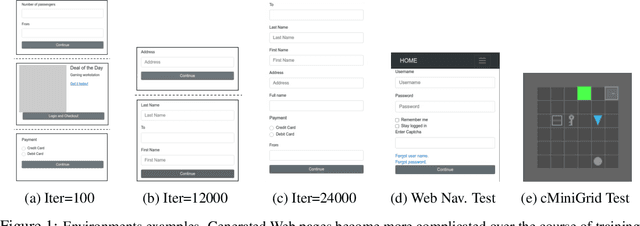
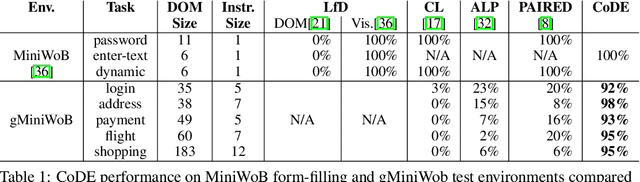

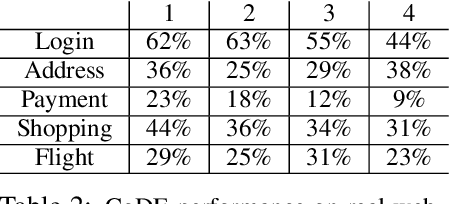
Many real-world problems are compositional - solving them requires completing interdependent sub-tasks, either in series or in parallel, that can be represented as a dependency graph. Deep reinforcement learning (RL) agents often struggle to learn such complex tasks due to the long time horizons and sparse rewards. To address this problem, we present Compositional Design of Environments (CoDE), which trains a Generator agent to automatically build a series of compositional tasks tailored to the RL agent's current skill level. This automatic curriculum not only enables the agent to learn more complex tasks than it could have otherwise, but also selects tasks where the agent's performance is weak, enhancing its robustness and ability to generalize zero-shot to unseen tasks at test-time. We analyze why current environment generation techniques are insufficient for the problem of generating compositional tasks, and propose a new algorithm that addresses these issues. Our results assess learning and generalization across multiple compositional tasks, including the real-world problem of learning to navigate and interact with web pages. We learn to generate environments composed of multiple pages or rooms, and train RL agents capable of completing wide-range of complex tasks in those environments. We contribute two new benchmark frameworks for generating compositional tasks, compositional MiniGrid and gMiniWoB for web navigation.CoDE yields 4x higher success rate than the strongest baseline, and demonstrates strong performance of real websites learned on 3500 primitive tasks.
Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
Jan 11, 2022
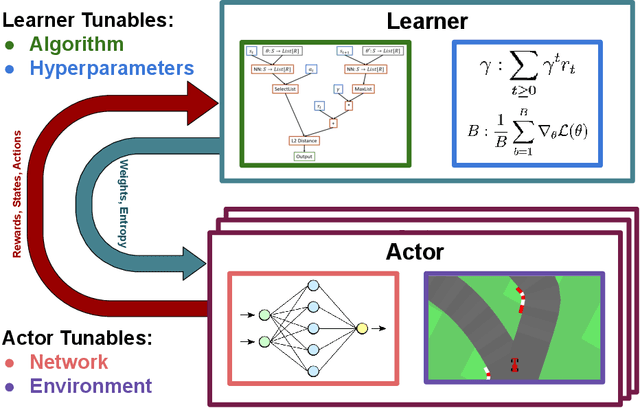
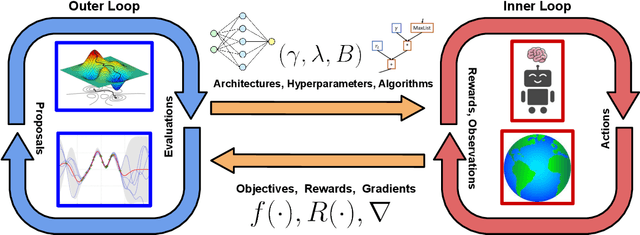

The combination of Reinforcement Learning (RL) with deep learning has led to a series of impressive feats, with many believing (deep) RL provides a path towards generally capable agents. However, the success of RL agents is often highly sensitive to design choices in the training process, which may require tedious and error-prone manual tuning. This makes it challenging to use RL for new problems, while also limits its full potential. In many other areas of machine learning, AutoML has shown it is possible to automate such design choices and has also yielded promising initial results when applied to RL. However, Automated Reinforcement Learning (AutoRL) involves not only standard applications of AutoML but also includes additional challenges unique to RL, that naturally produce a different set of methods. As such, AutoRL has been emerging as an important area of research in RL, providing promise in a variety of applications from RNA design to playing games such as Go. Given the diversity of methods and environments considered in RL, much of the research has been conducted in distinct subfields, ranging from meta-learning to evolution. In this survey we seek to unify the field of AutoRL, we provide a common taxonomy, discuss each area in detail and pose open problems which would be of interest to researchers going forward.
RL-DARTS: Differentiable Architecture Search for Reinforcement Learning
Jun 04, 2021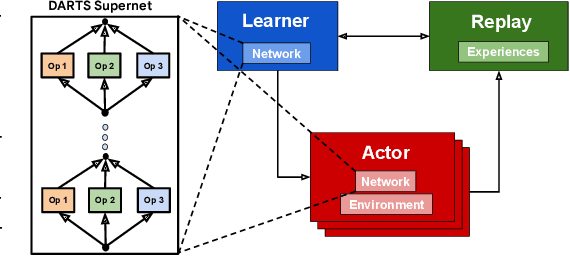
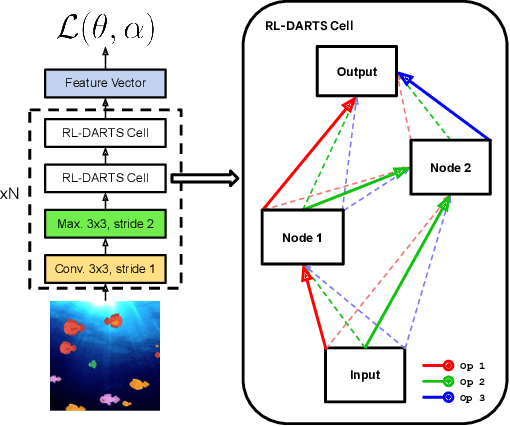
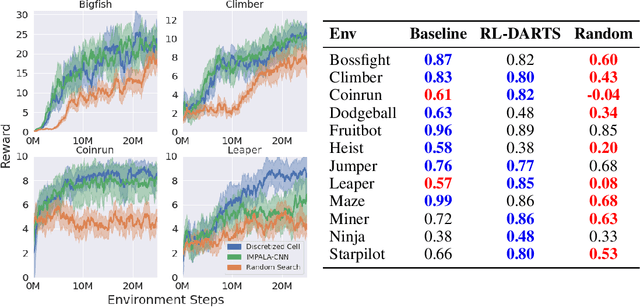
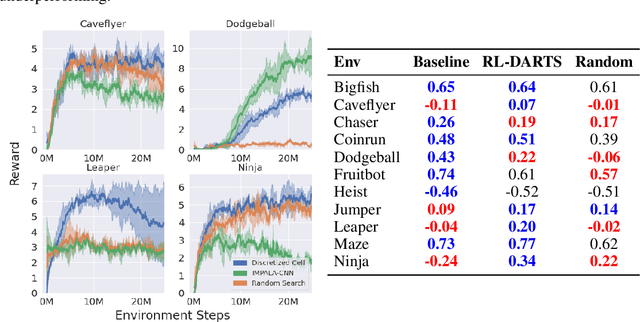
We introduce RL-DARTS, one of the first applications of Differentiable Architecture Search (DARTS) in reinforcement learning (RL) to search for convolutional cells, applied to the Procgen benchmark. We outline the initial difficulties of applying neural architecture search techniques in RL, and demonstrate that by simply replacing the image encoder with a DARTS supernet, our search method is sample-efficient, requires minimal extra compute resources, and is also compatible with off-policy and on-policy RL algorithms, needing only minor changes in preexisting code. Surprisingly, we find that the supernet can be used as an actor for inference to generate replay data in standard RL training loops, and thus train end-to-end. Throughout this training process, we show that the supernet gradually learns better cells, leading to alternative architectures which can be highly competitive against manually designed policies, but also verify previous design choices for RL policies.