 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models in Conversational Recommender Systems
May 16, 2023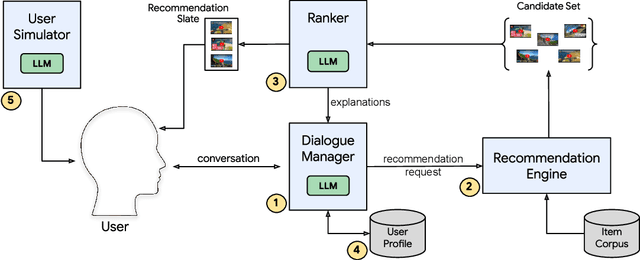



A Conversational Recommender System (CRS) offers increased transparency and control to users by enabling them to engage with the system through a real-time multi-turn dialogue. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to converse naturally and incorporate world knowledge and common-sense reasoning into language understanding, unlocking the potential of this paradigm. However, effectively leveraging LLMs within a CRS introduces new technical challenges, including properly understanding and controlling a complex conversation and retrieving from external sources of information. These issues are exacerbated by a large, evolving item corpus and a lack of conversational data for training. In this paper, we provide a roadmap for building an end-to-end large-scale CRS using LLMs. In particular, we propose new implementations for user preference understanding, flexible dialogue management and explainable recommendations as part of an integrated architecture powered by LLMs. For improved personalization, we describe how an LLM can consume interpretable natural language user profiles and use them to modulate session-level context. To overcome conversational data limitations in the absence of an existing production CRS, we propose techniques for building a controllable LLM-based user simulator to generate synthetic conversations. As a proof of concept we introduce RecLLM, a large-scale CRS for YouTube videos built on LaMDA, and demonstrate its fluency and diverse functionality through some illustrative example conversations.
Evaluation of Synthetic Datasets for Conversational Recommender Systems
Dec 12, 2022

For researchers leveraging Large-Language Models (LLMs) in the generation of training datasets, especially for conversational recommender systems - the absence of robust evaluation frameworks has been a long-standing problem. The efficiency brought about by LLMs in the data generation phase is impeded during the process of evaluation of the generated data, since it generally requires human-raters to ensure that the data generated is of high quality and has sufficient diversity. Since the quality of training data is critical for downstream applications, it is important to develop metrics that evaluate the quality holistically and identify biases. In this paper, we present a framework that takes a multi-faceted approach towards evaluating datasets produced by generative models and discuss the advantages and limitations of various evaluation methods.
Environment Generation for Zero-Shot Compositional Reinforcement Learning
Jan 21, 2022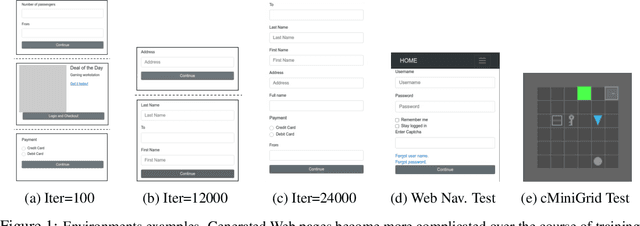
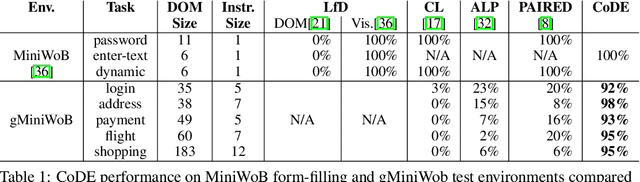

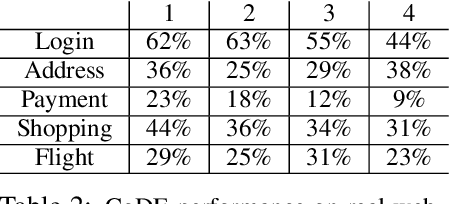
Many real-world problems are compositional - solving them requires completing interdependent sub-tasks, either in series or in parallel, that can be represented as a dependency graph. Deep reinforcement learning (RL) agents often struggle to learn such complex tasks due to the long time horizons and sparse rewards. To address this problem, we present Compositional Design of Environments (CoDE), which trains a Generator agent to automatically build a series of compositional tasks tailored to the RL agent's current skill level. This automatic curriculum not only enables the agent to learn more complex tasks than it could have otherwise, but also selects tasks where the agent's performance is weak, enhancing its robustness and ability to generalize zero-shot to unseen tasks at test-time. We analyze why current environment generation techniques are insufficient for the problem of generating compositional tasks, and propose a new algorithm that addresses these issues. Our results assess learning and generalization across multiple compositional tasks, including the real-world problem of learning to navigate and interact with web pages. We learn to generate environments composed of multiple pages or rooms, and train RL agents capable of completing wide-range of complex tasks in those environments. We contribute two new benchmark frameworks for generating compositional tasks, compositional MiniGrid and gMiniWoB for web navigation.CoDE yields 4x higher success rate than the strongest baseline, and demonstrates strong performance of real websites learned on 3500 primitive tasks.
Adversarial Environment Generation for Learning to Navigate the Web
Mar 02, 2021
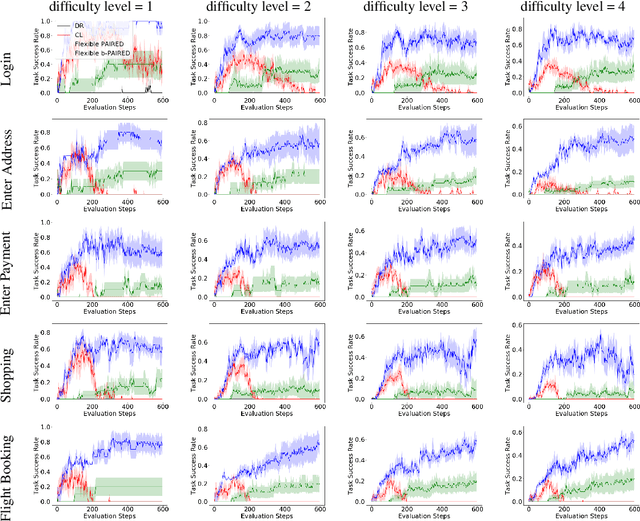
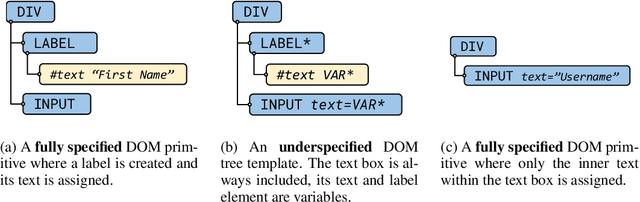
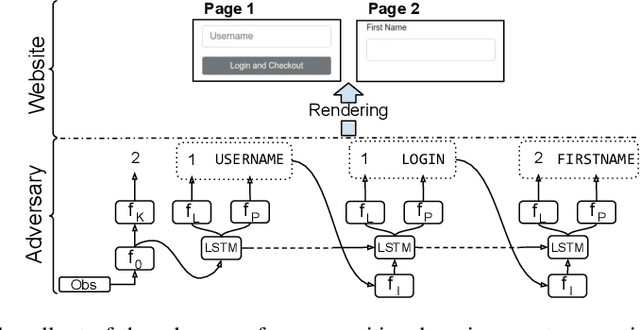
Learning to autonomously navigate the web is a difficult sequential decision making task. The state and action spaces are large and combinatorial in nature, and websites are dynamic environments consisting of several pages. One of the bottlenecks of training web navigation agents is providing a learnable curriculum of training environments that can cover the large variety of real-world websites. Therefore, we propose using Adversarial Environment Generation (AEG) to generate challenging web environments in which to train reinforcement learning (RL) agents. We provide a new benchmarking environment, gMiniWoB, which enables an RL adversary to use compositional primitives to learn to generate arbitrarily complex websites. To train the adversary, we propose a new technique for maximizing regret using the difference in the scores obtained by a pair of navigator agents. Our results show that our approach significantly outperforms prior methods for minimax regret AEG. The regret objective trains the adversary to design a curriculum of environments that are "just-the-right-challenge" for the navigator agents; our results show that over time, the adversary learns to generate increasingly complex web navigation tasks. The navigator agents trained with our technique learn to complete challenging, high-dimensional web navigation tasks, such as form filling, booking a flight etc. We show that the navigator agent trained with our proposed Flexible b-PAIRED technique significantly outperforms competitive automatic curriculum generation baselines -- including a state-of-the-art RL web navigation approach -- on a set of challenging unseen test environments, and achieves more than 80% success rate on some tasks.