 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models in Conversational Recommender Systems
May 16, 2023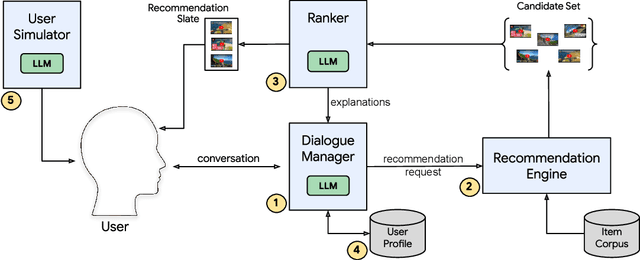



A Conversational Recommender System (CRS) offers increased transparency and control to users by enabling them to engage with the system through a real-time multi-turn dialogue. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to converse naturally and incorporate world knowledge and common-sense reasoning into language understanding, unlocking the potential of this paradigm. However, effectively leveraging LLMs within a CRS introduces new technical challenges, including properly understanding and controlling a complex conversation and retrieving from external sources of information. These issues are exacerbated by a large, evolving item corpus and a lack of conversational data for training. In this paper, we provide a roadmap for building an end-to-end large-scale CRS using LLMs. In particular, we propose new implementations for user preference understanding, flexible dialogue management and explainable recommendations as part of an integrated architecture powered by LLMs. For improved personalization, we describe how an LLM can consume interpretable natural language user profiles and use them to modulate session-level context. To overcome conversational data limitations in the absence of an existing production CRS, we propose techniques for building a controllable LLM-based user simulator to generate synthetic conversations. As a proof of concept we introduce RecLLM, a large-scale CRS for YouTube videos built on LaMDA, and demonstrate its fluency and diverse functionality through some illustrative example conversations.
ActionBert: Leveraging User Actions for Semantic Understanding of User Interfaces
Jan 25, 2021
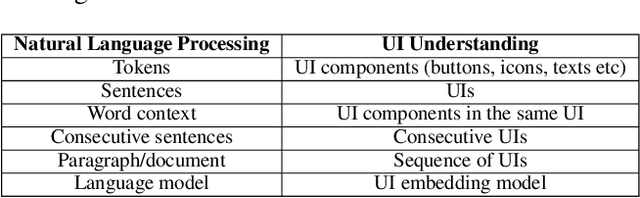
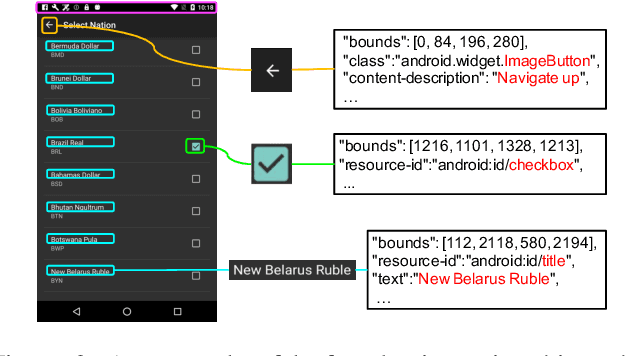
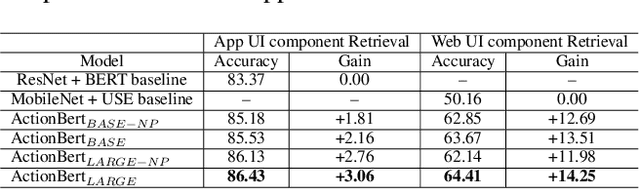
As mobile devices are becoming ubiquitous, regularly interacting with a variety of user interfaces (UIs) is a common aspect of daily life for many people. To improve the accessibility of these devices and to enable their usage in a variety of settings, building models that can assist users and accomplish tasks through the UI is vitally important. However, there are several challenges to achieve this. First, UI components of similar appearance can have different functionalities, making understanding their function more important than just analyzing their appearance. Second, domain-specific features like Document Object Model (DOM) in web pages and View Hierarchy (VH) in mobile applications provide important signals about the semantics of UI elements, but these features are not in a natural language format. Third, owing to a large diversity in UIs and absence of standard DOM or VH representations, building a UI understanding model with high coverage requires large amounts of training data. Inspired by the success of pre-training based approaches in NLP for tackling a variety of problems in a data-efficient way, we introduce a new pre-trained UI representation model called ActionBert. Our methodology is designed to leverage visual, linguistic and domain-specific features in user interaction traces to pre-train generic feature representations of UIs and their components. Our key intuition is that user actions, e.g., a sequence of clicks on different UI components, reveals important information about their functionality. We evaluate the proposed model on a wide variety of downstream tasks, ranging from icon classification to UI component retrieval based on its natural language description. Experiments show that the proposed ActionBert model outperforms multi-modal baselines across all downstream tasks by up to 15.5%.