 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Generative Search and Recommendation
Apr 10, 2025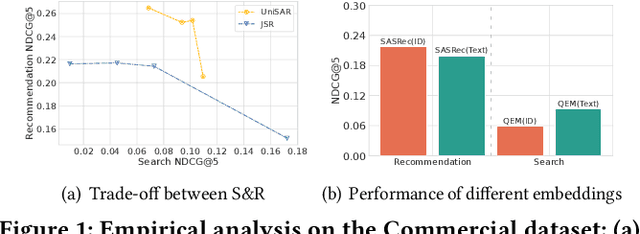
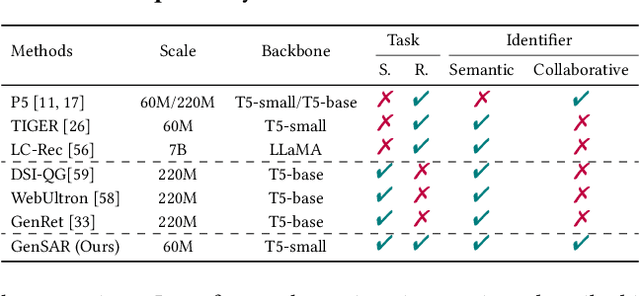
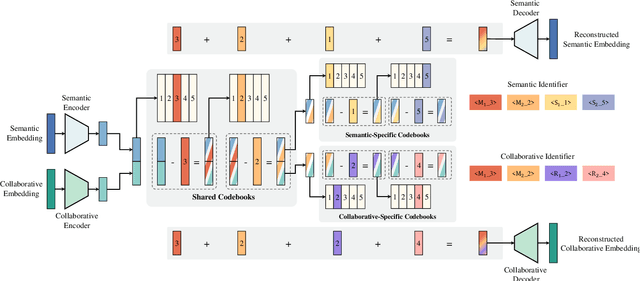

Modern commercial platforms typically offer both search and recommendation functionalities to serve diverse user needs, making joint modeling of these tasks an appealing direction. While prior work has shown that integrating search and recommendation can be mutually beneficial, it also reveals a performance trade-off: enhancements in one task often come at the expense of the other. This challenge arises from their distinct information requirements: search emphasizes semantic relevance between queries and items, whereas recommendation depends more on collaborative signals among users and items. Effectively addressing this trade-off requires tackling two key problems: (1) integrating both semantic and collaborative signals into item representations, and (2) guiding the model to distinguish and adapt to the unique demands of search and recommendation. The emergence of generative retrieval with Large Language Models (LLMs) presents new possibilities. This paradigm encodes items as identifiers and frames both search and recommendation as sequential generation tasks, offering the flexibility to leverage multiple identifiers and task-specific prompts. In light of this, we introduce GenSAR, a unified generative framework for balanced search and recommendation. Our approach designs dual-purpose identifiers and tailored training strategies to incorporate complementary signals and align with task-specific objectives. Experiments on both public and commercial datasets demonstrate that GenSAR effectively reduces the trade-off and achieves state-of-the-art performance on both tasks.
QE-RAG: A Robust Retrieval-Augmented Generation Benchmark for Query Entry Errors
Apr 05, 2025
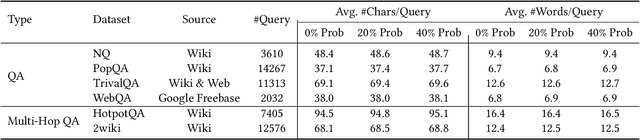
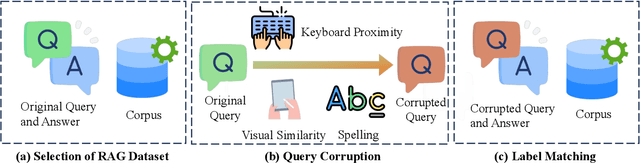
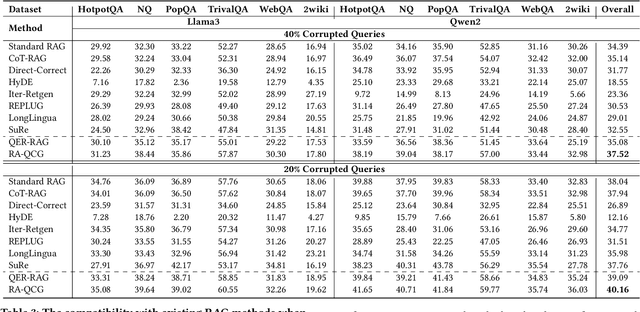
Retriever-augmented generation (RAG) has become a widely adopted approach for enhancing the factual accuracy of large language models (LLMs). While current benchmarks evaluate the performance of RAG methods from various perspectives, they share a common assumption that user queries used for retrieval are error-free. However, in real-world interactions between users and LLMs, query entry errors such as keyboard proximity errors, visual similarity errors, and spelling errors are frequent. The impact of these errors on current RAG methods against such errors remains largely unexplored. To bridge this gap, we propose QE-RAG, the first robust RAG benchmark designed specifically to evaluate performance against query entry errors. We augment six widely used datasets by injecting three common types of query entry errors into randomly selected user queries at rates of 20\% and 40\%, simulating typical user behavior in real-world scenarios. We analyze the impact of these errors on LLM outputs and find that corrupted queries degrade model performance, which can be mitigated through query correction and training a robust retriever for retrieving relevant documents. Based on these insights, we propose a contrastive learning-based robust retriever training method and a retrieval-augmented query correction method. Extensive in-domain and cross-domain experiments reveal that: (1) state-of-the-art RAG methods including sequential, branching, and iterative methods, exhibit poor robustness to query entry errors; (2) our method significantly enhances the robustness of RAG when handling query entry errors and it's compatible with existing RAG methods, further improving their robustness.
ReARTeR: Retrieval-Augmented Reasoning with Trustworthy Process Rewarding
Jan 14, 2025Retrieval-Augmented Generation (RAG) systems for Large Language Models (LLMs) hold promise in knowledge-intensive tasks but face limitations in complex multi-step reasoning. While recent methods have integrated RAG with chain-of-thought reasoning or test-time search using Process Reward Models (PRMs), these approaches encounter challenges such as a lack of explanations, bias in PRM training data, early-step bias in PRM scores, and insufficient post-training optimization of reasoning potential. To address these issues, we propose Retrieval-Augmented Reasoning through Trustworthy Process Rewarding (ReARTeR), a framework that enhances RAG systems' reasoning capabilities through post-training and test-time scaling. At test time, ReARTeR introduces Trustworthy Process Rewarding via a Process Reward Model for accurate scalar scoring and a Process Explanation Model (PEM) for generating natural language explanations, enabling step refinement. During post-training, it utilizes Monte Carlo Tree Search guided by Trustworthy Process Rewarding to collect high-quality step-level preference data, optimized through Iterative Preference Optimization. ReARTeR addresses three core challenges: (1) misalignment between PRM and PEM, tackled through off-policy preference learning; (2) bias in PRM training data, mitigated by balanced annotation methods and stronger annotations for challenging examples; and (3) early-step bias in PRM, resolved through a temporal-difference-based look-ahead search strategy. Experimental results on multi-step reasoning benchmarks demonstrate significant improvements, underscoring ReARTeR's potential to advance the reasoning capabilities of RAG systems.
Trigger$^3$: Refining Query Correction via Adaptive Model Selector
Dec 17, 2024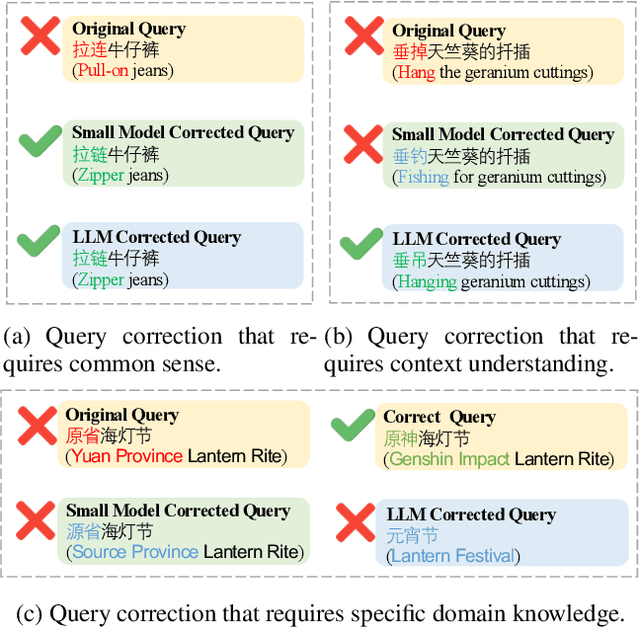

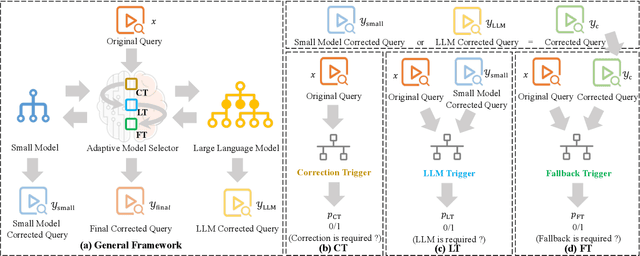

In search scenarios, user experience can be hindered by erroneous queries due to typos, voice errors, or knowledge gaps. Therefore, query correction is crucial for search engines. Current correction models, usually small models trained on specific data, often struggle with queries beyond their training scope or those requiring contextual understanding. While the advent of Large Language Models (LLMs) offers a potential solution, they are still limited by their pre-training data and inference cost, particularly for complex queries, making them not always effective for query correction. To tackle these, we propose Trigger$^3$, a large-small model collaboration framework that integrates the traditional correction model and LLM for query correction, capable of adaptively choosing the appropriate correction method based on the query and the correction results from the traditional correction model and LLM. Trigger$^3$ first employs a correction trigger to filter out correct queries. Incorrect queries are then corrected by the traditional correction model. If this fails, an LLM trigger is activated to call the LLM for correction. Finally, for queries that no model can correct, a fallback trigger decides to return the original query. Extensive experiments demonstrate Trigger$^3$ outperforms correction baselines while maintaining efficiency.
ReDeEP: Detecting Hallucination in Retrieval-Augmented Generation via Mechanistic Interpretability
Oct 15, 2024



Retrieval-Augmented Generation (RAG) models are designed to incorporate external knowledge, reducing hallucinations caused by insufficient parametric (internal) knowledge. However, even with accurate and relevant retrieved content, RAG models can still produce hallucinations by generating outputs that conflict with the retrieved information. Detecting such hallucinations requires disentangling how Large Language Models (LLMs) utilize external and parametric knowledge. Current detection methods often focus on one of these mechanisms or without decoupling their intertwined effects, making accurate detection difficult. In this paper, we investigate the internal mechanisms behind hallucinations in RAG scenarios. We discover hallucinations occur when the Knowledge FFNs in LLMs overemphasize parametric knowledge in the residual stream, while Copying Heads fail to effectively retain or integrate external knowledge from retrieved content. Based on these findings, we propose ReDeEP, a novel method that detects hallucinations by decoupling LLM's utilization of external context and parametric knowledge. Our experiments show that ReDeEP significantly improves RAG hallucination detection accuracy. Additionally, we introduce AARF, which mitigates hallucinations by modulating the contributions of Knowledge FFNs and Copying Heads.
LargePiG: Your Large Language Model is Secretly a Pointer Generator
Oct 15, 2024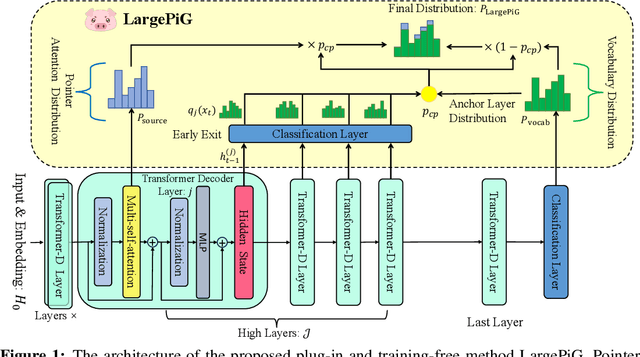
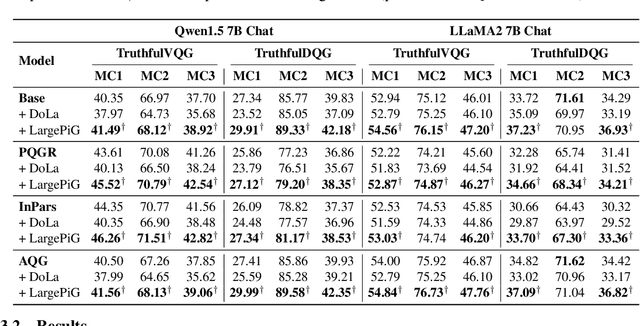
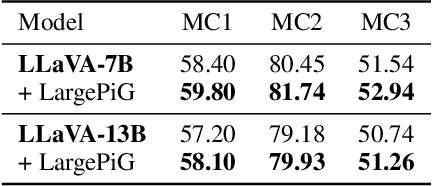
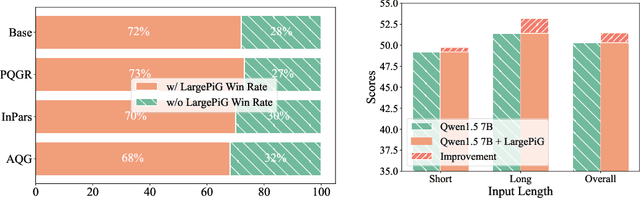
Recent research on query generation has focused on using Large Language Models (LLMs), which despite bringing state-of-the-art performance, also introduce issues with hallucinations in the generated queries. In this work, we introduce relevance hallucination and factuality hallucination as a new typology for hallucination problems brought by query generation based on LLMs. We propose an effective way to separate content from form in LLM-generated queries, which preserves the factual knowledge extracted and integrated from the inputs and compiles the syntactic structure, including function words, using the powerful linguistic capabilities of the LLM. Specifically, we introduce a model-agnostic and training-free method that turns the Large Language Model into a Pointer-Generator (LargePiG), where the pointer attention distribution leverages the LLM's inherent attention weights, and the copy probability is derived from the difference between the vocabulary distribution of the model's high layers and the last layer. To validate the effectiveness of LargePiG, we constructed two datasets for assessing the hallucination problems in query generation, covering both document and video scenarios. Empirical studies on various LLMs demonstrated the superiority of LargePiG on both datasets. Additional experiments also verified that LargePiG could reduce hallucination in large vision language models and improve the accuracy of document-based question-answering and factuality evaluation tasks.
GradCraft: Elevating Multi-task Recommendations through Holistic Gradient Crafting
Jul 29, 2024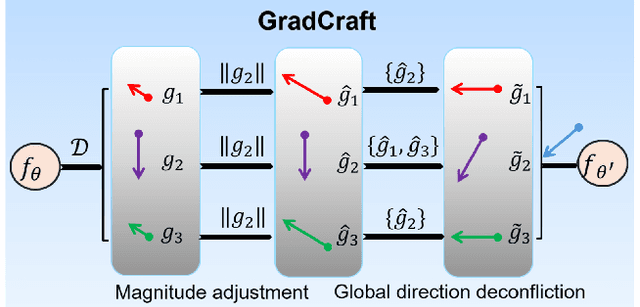

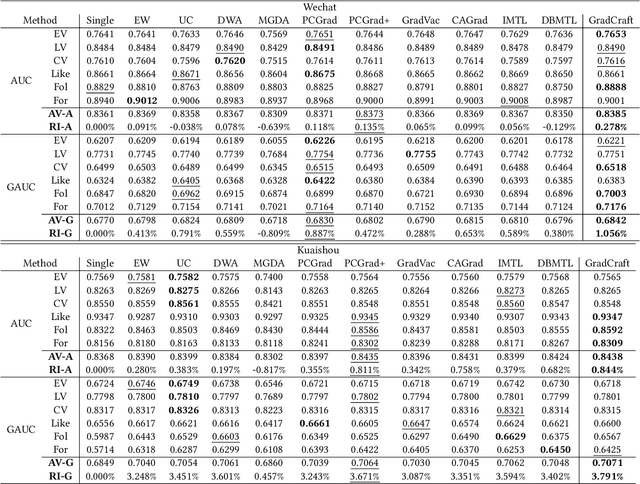
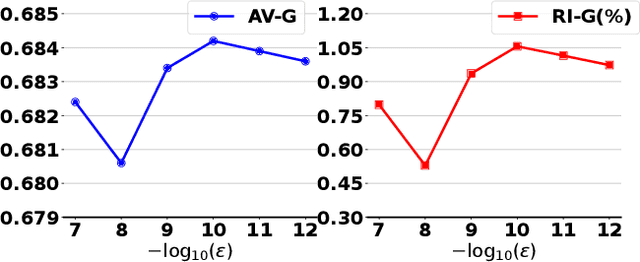
Recommender systems require the simultaneous optimization of multiple objectives to accurately model user interests, necessitating the application of multi-task learning methods. However, existing multi-task learning methods in recommendations overlook the specific characteristics of recommendation scenarios, falling short in achieving proper gradient balance. To address this challenge, we set the target of multi-task learning as attaining the appropriate magnitude balance and the global direction balance, and propose an innovative methodology named GradCraft in response. GradCraft dynamically adjusts gradient magnitudes to align with the maximum gradient norm, mitigating interference from gradient magnitudes for subsequent manipulation. It then employs projections to eliminate gradient conflicts in directions while considering all conflicting tasks simultaneously, theoretically guaranteeing the global resolution of direction conflicts. GradCraft ensures the concurrent achievement of appropriate magnitude balance and global direction balance, aligning with the inherent characteristics of recommendation scenarios. Both offline and online experiments attest to the efficacy of GradCraft in enhancing multi-task performance in recommendations. The source code for GradCraft can be accessed at https://github.com/baiyimeng/GradCraft.
TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou
Jul 23, 2024



The significance of modeling long-term user interests for CTR prediction tasks in large-scale recommendation systems is progressively gaining attention among researchers and practitioners. Existing work, such as SIM and TWIN, typically employs a two-stage approach to model long-term user behavior sequences for efficiency concerns. The first stage rapidly retrieves a subset of sequences related to the target item from a long sequence using a search-based mechanism namely the General Search Unit (GSU), while the second stage calculates the interest scores using the Exact Search Unit (ESU) on the retrieved results. Given the extensive length of user behavior sequences spanning the entire life cycle, potentially reaching up to 10^6 in scale, there is currently no effective solution for fully modeling such expansive user interests. To overcome this issue, we introduced TWIN-V2, an enhancement of TWIN, where a divide-and-conquer approach is applied to compress life-cycle behaviors and uncover more accurate and diverse user interests. Specifically, a hierarchical clustering method groups items with similar characteristics in life-cycle behaviors into a single cluster during the offline phase. By limiting the size of clusters, we can compress behavior sequences well beyond the magnitude of 10^5 to a length manageable for online inference in GSU retrieval. Cluster-aware target attention extracts comprehensive and multi-faceted long-term interests of users, thereby making the final recommendation results more accurate and diverse. Extensive offline experiments on a multi-billion-scale industrial dataset and online A/B tests have demonstrated the effectiveness of TWIN-V2. Under an efficient deployment framework, TWIN-V2 has been successfully deployed to the primary traffic that serves hundreds of millions of daily active users at Kuaishou.
UniSAR: Modeling User Transition Behaviors between Search and Recommendation
Apr 15, 2024Nowadays, many platforms provide users with both search and recommendation services as important tools for accessing information. The phenomenon has led to a correlation between user search and recommendation behaviors, providing an opportunity to model user interests in a fine-grained way. Existing approaches either model user search and recommendation behaviors separately or overlook the different transitions between user search and recommendation behaviors. In this paper, we propose a framework named UniSAR that effectively models the different types of fine-grained behavior transitions for providing users a Unified Search And Recommendation service. Specifically, UniSAR models the user transition behaviors between search and recommendation through three steps: extraction, alignment, and fusion, which are respectively implemented by transformers equipped with pre-defined masks, contrastive learning that aligns the extracted fine-grained user transitions, and cross-attentions that fuse different transitions. To provide users with a unified service, the learned representations are fed into the downstream search and recommendation models. Joint learning on both search and recommendation data is employed to utilize the knowledge and enhance each other. Experimental results on two public datasets demonstrated the effectiveness of UniSAR in terms of enhancing both search and recommendation simultaneously. The experimental analysis further validates that UniSAR enhances the results by successfully modeling the user transition behaviors between search and recommendation.
To Search or to Recommend: Predicting Open-App Motivation with Neural Hawkes Process
Apr 04, 2024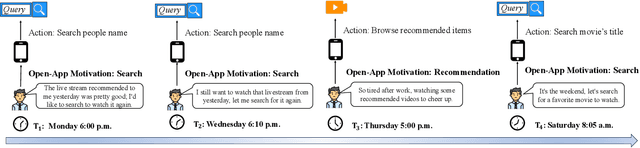
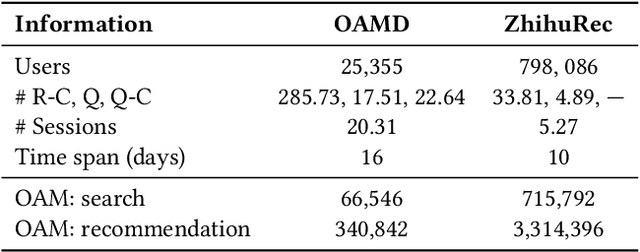
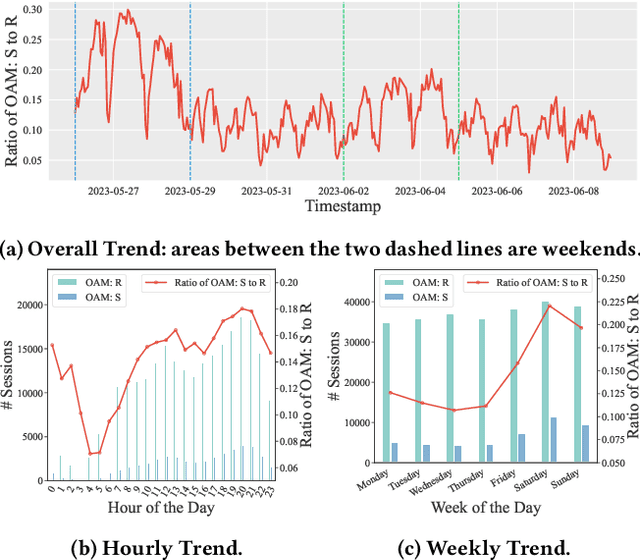
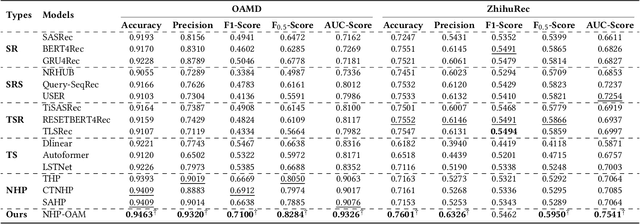
Incorporating Search and Recommendation (S&R) services within a singular application is prevalent in online platforms, leading to a new task termed open-app motivation prediction, which aims to predict whether users initiate the application with the specific intent of information searching, or to explore recommended content for entertainment. Studies have shown that predicting users' motivation to open an app can help to improve user engagement and enhance performance in various downstream tasks. However, accurately predicting open-app motivation is not trivial, as it is influenced by user-specific factors, search queries, clicked items, as well as their temporal occurrences. Furthermore, these activities occur sequentially and exhibit intricate temporal dependencies. Inspired by the success of the Neural Hawkes Process (NHP) in modeling temporal dependencies in sequences, this paper proposes a novel neural Hawkes process model to capture the temporal dependencies between historical user browsing and querying actions. The model, referred to as Neural Hawkes Process-based Open-App Motivation prediction model (NHP-OAM), employs a hierarchical transformer and a novel intensity function to encode multiple factors, and open-app motivation prediction layer to integrate time and user-specific information for predicting users' open-app motivations. To demonstrate the superiority of our NHP-OAM model and construct a benchmark for the Open-App Motivation Prediction task, we not only extend the public S&R dataset ZhihuRec but also construct a new real-world Open-App Motivation Dataset (OAMD). Experiments on these two datasets validate NHP-OAM's superiority over baseline models. Further downstream application experiments demonstrate NHP-OAM's effectiveness in predicting users' Open-App Motivation, highlighting the immense application value of NHP-OAM.