 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQE-RAG: A Robust Retrieval-Augmented Generation Benchmark for Query Entry Errors
Paper and Code
Apr 05, 2025
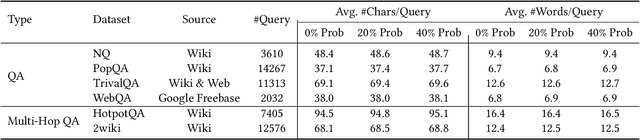
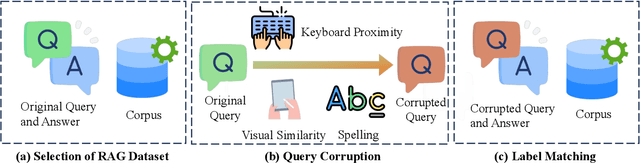
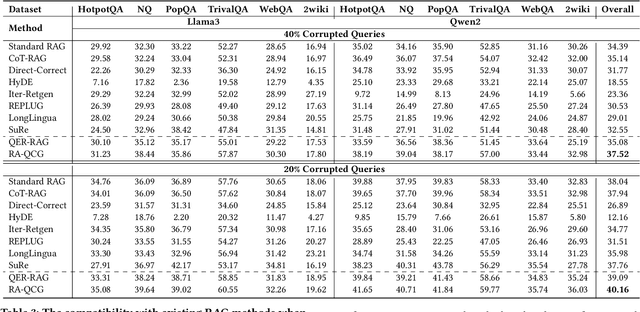
Retriever-augmented generation (RAG) has become a widely adopted approach for enhancing the factual accuracy of large language models (LLMs). While current benchmarks evaluate the performance of RAG methods from various perspectives, they share a common assumption that user queries used for retrieval are error-free. However, in real-world interactions between users and LLMs, query entry errors such as keyboard proximity errors, visual similarity errors, and spelling errors are frequent. The impact of these errors on current RAG methods against such errors remains largely unexplored. To bridge this gap, we propose QE-RAG, the first robust RAG benchmark designed specifically to evaluate performance against query entry errors. We augment six widely used datasets by injecting three common types of query entry errors into randomly selected user queries at rates of 20\% and 40\%, simulating typical user behavior in real-world scenarios. We analyze the impact of these errors on LLM outputs and find that corrupted queries degrade model performance, which can be mitigated through query correction and training a robust retriever for retrieving relevant documents. Based on these insights, we propose a contrastive learning-based robust retriever training method and a retrieval-augmented query correction method. Extensive in-domain and cross-domain experiments reveal that: (1) state-of-the-art RAG methods including sequential, branching, and iterative methods, exhibit poor robustness to query entry errors; (2) our method significantly enhances the robustness of RAG when handling query entry errors and it's compatible with existing RAG methods, further improving their robustness.