 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSandwich Reasoning: An Answer-Reasoning-Answer Approach for Low-Latency Query Correction
Jan 07, 2026Query correction is a critical entry point in modern search pipelines, demanding high accuracy strictly within real-time latency constraints. Chain-of-Thought (CoT) reasoning improves accuracy but incurs prohibitive latency for real-time query correction. A potential solution is to output an answer before reasoning to reduce latency; however, under autoregressive decoding, the early answer is independent of subsequent reasoning, preventing the model from leveraging its reasoning capability to improve accuracy. To address this issue, we propose Sandwich Reasoning (SandwichR), a novel approach that explicitly aligns a fast initial answer with post-hoc reasoning, enabling low-latency query correction without sacrificing reasoning-aware accuracy. SandwichR follows an Answer-Reasoning-Answer paradigm, producing an initial correction, an explicit reasoning process, and a final refined correction. To align the initial answer with post-reasoning insights, we design a consistency-aware reinforcement learning (RL) strategy: a dedicated consistency reward enforces alignment between the initial and final corrections, while margin-based rejection sampling prioritizes borderline samples where reasoning drives the most impactful corrective gains. Additionally, we construct a high-quality query correction dataset, addressing the lack of specialized benchmarks for complex query correction. Experimental results demonstrate that SandwichR achieves SOTA accuracy comparable to standard CoT while delivering a 40-70% latency reduction, resolving the latency-accuracy trade-off in online search.
PrLM: Learning Explicit Reasoning for Personalized RAG via Contrastive Reward Optimization
Aug 10, 2025Personalized retrieval-augmented generation (RAG) aims to produce user-tailored responses by incorporating retrieved user profiles alongside the input query. Existing methods primarily focus on improving retrieval and rely on large language models (LLMs) to implicitly integrate the retrieved context with the query. However, such models are often sensitive to retrieval quality and may generate responses that are misaligned with user preferences. To address this limitation, we propose PrLM, a reinforcement learning framework that trains LLMs to explicitly reason over retrieved user profiles. Guided by a contrastively trained personalization reward model, PrLM effectively learns from user responses without requiring annotated reasoning paths. Experiments on three personalized text generation datasets show that PrLM outperforms existing methods and remains robust across varying numbers of retrieved profiles and different retrievers.
SyLeR: A Framework for Explicit Syllogistic Legal Reasoning in Large Language Models
Apr 05, 2025Syllogistic reasoning is a fundamental aspect of legal decision-making, enabling logical conclusions by connecting general legal principles with specific case facts. Although existing large language models (LLMs) can generate responses to legal questions, they fail to perform explicit syllogistic reasoning, often producing implicit and unstructured answers that lack explainability and trustworthiness. To address this limitation, we propose SyLeR, a novel framework that empowers LLMs to engage in explicit syllogistic legal reasoning. SyLeR integrates a tree-structured hierarchical retrieval mechanism to effectively combine relevant legal statutes and precedent cases, forming comprehensive major premises. This is followed by a two-stage fine-tuning process: supervised fine-tuning warm-up establishes a foundational understanding of syllogistic reasoning, while reinforcement learning with a structure-aware reward mechanism refines the ability of the model to generate diverse logically sound and well-structured reasoning paths. We conducted extensive experiments across various dimensions, including in-domain and cross-domain user groups (legal laypersons and practitioners), multiple languages (Chinese and French), and different LLM backbones (legal-specific and open-domain LLMs). The results show that SyLeR significantly improves response accuracy and consistently delivers explicit, explainable, and trustworthy legal reasoning.
QE-RAG: A Robust Retrieval-Augmented Generation Benchmark for Query Entry Errors
Apr 05, 2025
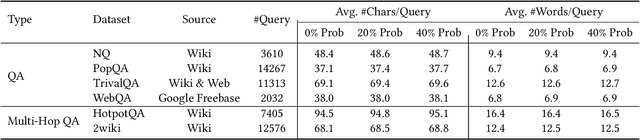
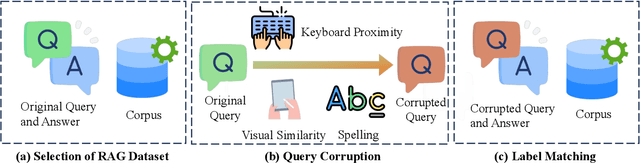
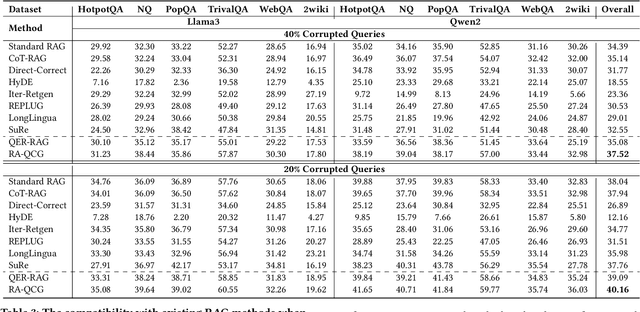
Retriever-augmented generation (RAG) has become a widely adopted approach for enhancing the factual accuracy of large language models (LLMs). While current benchmarks evaluate the performance of RAG methods from various perspectives, they share a common assumption that user queries used for retrieval are error-free. However, in real-world interactions between users and LLMs, query entry errors such as keyboard proximity errors, visual similarity errors, and spelling errors are frequent. The impact of these errors on current RAG methods against such errors remains largely unexplored. To bridge this gap, we propose QE-RAG, the first robust RAG benchmark designed specifically to evaluate performance against query entry errors. We augment six widely used datasets by injecting three common types of query entry errors into randomly selected user queries at rates of 20\% and 40\%, simulating typical user behavior in real-world scenarios. We analyze the impact of these errors on LLM outputs and find that corrupted queries degrade model performance, which can be mitigated through query correction and training a robust retriever for retrieving relevant documents. Based on these insights, we propose a contrastive learning-based robust retriever training method and a retrieval-augmented query correction method. Extensive in-domain and cross-domain experiments reveal that: (1) state-of-the-art RAG methods including sequential, branching, and iterative methods, exhibit poor robustness to query entry errors; (2) our method significantly enhances the robustness of RAG when handling query entry errors and it's compatible with existing RAG methods, further improving their robustness.
LexPam: Legal Procedure Awareness-Guided Mathematical Reasoning
Apr 03, 2025The legal mathematical reasoning ability of LLMs is crucial when applying them to real-world scenarios, as it directly affects the credibility of the LLM. While existing legal LLMs can perform general judicial question answering, their legal mathematical reasoning capabilities have not been trained. Open-domain reasoning models, though able to generate detailed calculation steps, do not follow the reasoning logic required for legal scenarios. Additionally, there is currently a lack of legal mathematical reasoning datasets to help validate and enhance LLMs' reasoning abilities in legal contexts. To address these issues, we propose the first Chinese legal Mathematical Reasoning Dataset, LexNum, which includes three common legal mathematical reasoning scenarios: economic compensation, work injury compensation, and traffic accident compensation. Based on LexNum, we tested the performance of existing legal LLMs and reasoning LLMs, and introduced LexPam, a reinforcement learning algorithm guided by legal procedural awareness to train LLMs, enhancing their mathematical reasoning abilities in legal scenarios. Experiments on tasks in the three legal scenarios show that the performance of existing legal LLMs and reasoning models in legal mathematical reasoning tasks is unsatisfactory. LexPam can enhance the LLM's ability in these tasks.
CitaLaw: Enhancing LLM with Citations in Legal Domain
Dec 19, 2024



In this paper, we propose CitaLaw, the first benchmark designed to evaluate LLMs' ability to produce legally sound responses with appropriate citations. CitaLaw features a diverse set of legal questions for both laypersons and practitioners, paired with a comprehensive corpus of law articles and precedent cases as a reference pool. This framework enables LLM-based systems to retrieve supporting citations from the reference corpus and align these citations with the corresponding sentences in their responses. Moreover, we introduce syllogism-inspired evaluation methods to assess the legal alignment between retrieved references and LLM-generated responses, as well as their consistency with user questions. Extensive experiments on 2 open-domain and 7 legal-specific LLMs demonstrate that integrating legal references substantially enhances response quality. Furthermore, our proposed syllogism-based evaluation method exhibits strong agreement with human judgments.
Beyond Guilt: Legal Judgment Prediction with Trichotomous Reasoning
Dec 19, 2024



In legal practice, judges apply the trichotomous dogmatics of criminal law, sequentially assessing the elements of the offense, unlawfulness, and culpability to determine whether an individual's conduct constitutes a crime. Although current legal large language models (LLMs) show promising accuracy in judgment prediction, they lack trichotomous reasoning capabilities due to the absence of an appropriate benchmark dataset, preventing them from predicting innocent outcomes. As a result, every input is automatically assigned a charge, limiting their practical utility in legal contexts. To bridge this gap, we introduce LJPIV, the first benchmark dataset for Legal Judgment Prediction with Innocent Verdicts. Adhering to the trichotomous dogmatics, we extend three widely-used legal datasets through LLM-based augmentation and manual verification. Our experiments with state-of-the-art legal LLMs and novel strategies that integrate trichotomous reasoning into zero-shot prompting and fine-tuning reveal: (1) current legal LLMs have significant room for improvement, with even the best models achieving an F1 score of less than 0.3 on LJPIV; and (2) our strategies notably enhance both in-domain and cross-domain judgment prediction accuracy, especially for cases resulting in an innocent verdict.
Trigger$^3$: Refining Query Correction via Adaptive Model Selector
Dec 17, 2024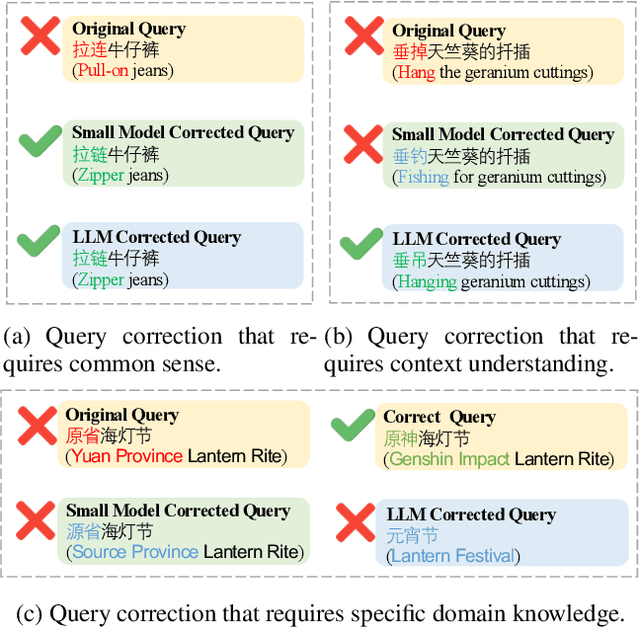

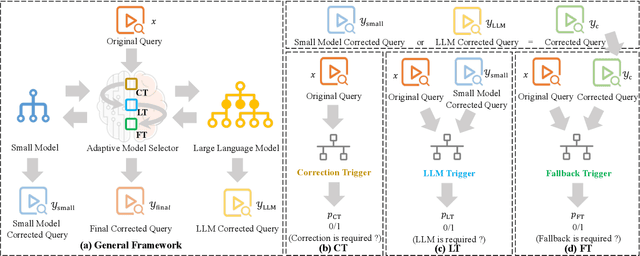

In search scenarios, user experience can be hindered by erroneous queries due to typos, voice errors, or knowledge gaps. Therefore, query correction is crucial for search engines. Current correction models, usually small models trained on specific data, often struggle with queries beyond their training scope or those requiring contextual understanding. While the advent of Large Language Models (LLMs) offers a potential solution, they are still limited by their pre-training data and inference cost, particularly for complex queries, making them not always effective for query correction. To tackle these, we propose Trigger$^3$, a large-small model collaboration framework that integrates the traditional correction model and LLM for query correction, capable of adaptively choosing the appropriate correction method based on the query and the correction results from the traditional correction model and LLM. Trigger$^3$ first employs a correction trigger to filter out correct queries. Incorrect queries are then corrected by the traditional correction model. If this fails, an LLM trigger is activated to call the LLM for correction. Finally, for queries that no model can correct, a fallback trigger decides to return the original query. Extensive experiments demonstrate Trigger$^3$ outperforms correction baselines while maintaining efficiency.
Effective In-Context Example Selection through Data Compression
May 19, 2024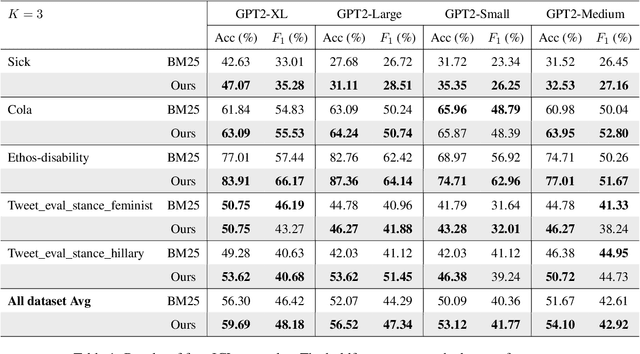
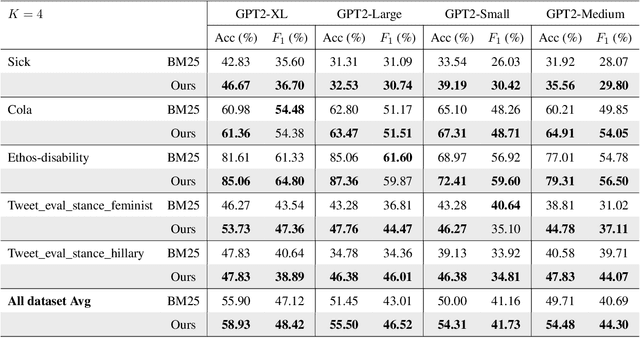
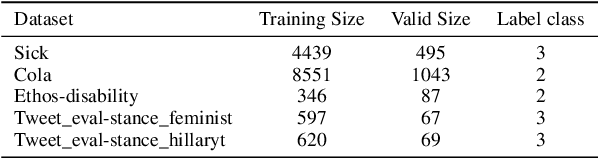

In-context learning has been extensively validated in large language models. However, the mechanism and selection strategy for in-context example selection, which is a crucial ingredient in this approach, lacks systematic and in-depth research. In this paper, we propose a data compression approach to the selection of in-context examples. We introduce a two-stage method that can effectively choose relevant examples and retain sufficient information about the training dataset within the in-context examples. Our method shows a significant improvement of an average of 5.90% across five different real-world datasets using four language models.
Logic Rules as Explanations for Legal Case Retrieval
Mar 03, 2024In this paper, we address the issue of using logic rules to explain the results from legal case retrieval. The task is critical to legal case retrieval because the users (e.g., lawyers or judges) are highly specialized and require the system to provide logical, faithful, and interpretable explanations before making legal decisions. Recently, research efforts have been made to learn explainable legal case retrieval models. However, these methods usually select rationales (key sentences) from the legal cases as explanations, failing to provide faithful and logically correct explanations. In this paper, we propose Neural-Symbolic enhanced Legal Case Retrieval (NS-LCR), a framework that explicitly conducts reasoning on the matching of legal cases through learning case-level and law-level logic rules. The learned rules are then integrated into the retrieval process in a neuro-symbolic manner. Benefiting from the logic and interpretable nature of the logic rules, NS-LCR is equipped with built-in faithful explainability. We also show that NS-LCR is a model-agnostic framework that can be plugged in for multiple legal retrieval models. To showcase NS-LCR's superiority, we enhance existing benchmarks by adding manually annotated logic rules and introducing a novel explainability metric using Large Language Models (LLMs). Our comprehensive experiments reveal NS-LCR's effectiveness for ranking, alongside its proficiency in delivering reliable explanations for legal case retrieval.