 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation-Guided Structural Transfer for Continual Learning Beyond Sparse Distributed Memory
Dec 17, 2025Sparse neural systems are gaining traction for efficient continual learning due to their modularity and low interference. Architectures such as Sparse Distributed Memory Multi-Layer Perceptrons (SDMLP) construct task-specific subnetworks via Top-K activation and have shown resilience against catastrophic forgetting. However, their rigid modularity limits cross-task knowledge reuse and leads to performance degradation under high sparsity. We propose Selective Subnetwork Distillation (SSD), a structurally guided continual learning framework that treats distillation not as a regularizer but as a topology-aligned information conduit. SSD identifies neurons with high activation frequency and selectively distills knowledge within previous Top-K subnetworks and output logits, without requiring replay or task labels. This enables structural realignment while preserving sparse modularity. Experiments on Split CIFAR-10, CIFAR-100, and MNIST demonstrate that SSD improves accuracy, retention, and representation coverage, offering a structurally grounded solution for sparse continual learning.
LexPam: Legal Procedure Awareness-Guided Mathematical Reasoning
Apr 03, 2025The legal mathematical reasoning ability of LLMs is crucial when applying them to real-world scenarios, as it directly affects the credibility of the LLM. While existing legal LLMs can perform general judicial question answering, their legal mathematical reasoning capabilities have not been trained. Open-domain reasoning models, though able to generate detailed calculation steps, do not follow the reasoning logic required for legal scenarios. Additionally, there is currently a lack of legal mathematical reasoning datasets to help validate and enhance LLMs' reasoning abilities in legal contexts. To address these issues, we propose the first Chinese legal Mathematical Reasoning Dataset, LexNum, which includes three common legal mathematical reasoning scenarios: economic compensation, work injury compensation, and traffic accident compensation. Based on LexNum, we tested the performance of existing legal LLMs and reasoning LLMs, and introduced LexPam, a reinforcement learning algorithm guided by legal procedural awareness to train LLMs, enhancing their mathematical reasoning abilities in legal scenarios. Experiments on tasks in the three legal scenarios show that the performance of existing legal LLMs and reasoning models in legal mathematical reasoning tasks is unsatisfactory. LexPam can enhance the LLM's ability in these tasks.
Artificial Intelligence-derived Vascular Age from Photoplethysmography: A Novel Digital Biomarker for Cardiovascular Health
Feb 19, 2025With the increasing availability of wearable devices, photoplethysmography (PPG) has emerged as a promising non-invasive tool for monitoring human hemodynamics. We propose a deep learning framework to estimate vascular age (AI-vascular age) from PPG signals, incorporating a distribution-aware loss to address biases caused by imbalanced data. The model was developed using data from the UK Biobank (UKB), with 98,672 participants in the development cohort and 113,559 participants (144,683 data pairs) for clinical evaluation. After adjusting for key confounders, individuals with a vascular age gap (AI-vascular age minus calendar age) exceeding 9 years had a significantly higher risk of major adverse cardiovascular and cerebrovascular events (MACCE) (HR = 2.37, p < 0.005) and secondary outcomes, including diabetes (HR = 2.69, p < 0.005), hypertension (HR = 2.88, p < 0.005), coronary heart disease (HR = 2.20, p < 0.005), heart failure (HR = 2.15, p < 0.005), myocardial infarction (HR = 2.51, p < 0.005), stroke (HR = 2.55, p < 0.005), and all-cause mortality (HR = 2.51, p < 0.005). Conversely, participants with a vascular age gap below -9 years exhibited a significantly lower incidence of these outcomes. We further evaluated the longitudinal applicability of AI-vascular age using serial PPG data from the UKB, demonstrating its value in risk stratification by leveraging AI-vascular age at two distinct time points to predict future MACCE incidence. External validation was performed on a MIMIC-III-derived cohort (n = 2,343), where each one-year increase in vascular age gap was significantly associated with elevated in-hospital mortality risk (OR = 1.02, p < 0.005). In conclusion, our study establishes AI-vascular age as a novel, non-invasive digital biomarker for cardiovascular health assessment.
Deep Inertia $L_p$ Half-Quadratic Splitting Unrolling Network for Sparse View CT Reconstruction
Aug 13, 2024



Sparse view computed tomography (CT) reconstruction poses a challenging ill-posed inverse problem, necessitating effective regularization techniques. In this letter, we employ $L_p$-norm ($0<p<1$) regularization to induce sparsity and introduce inertial steps, leading to the development of the inertial $L_p$-norm half-quadratic splitting algorithm. We rigorously prove the convergence of this algorithm. Furthermore, we leverage deep learning to initialize the conjugate gradient method, resulting in a deep unrolling network with theoretical guarantees. Our extensive numerical experiments demonstrate that our proposed algorithm surpasses existing methods, particularly excelling in fewer scanned views and complex noise conditions.
* This paper was accepted by IEEE Signal Processing Letters on July 28, 2024
Towards Efficient Deep Spiking Neural Networks Construction with Spiking Activity based Pruning
Jun 03, 2024



The emergence of deep and large-scale spiking neural networks (SNNs) exhibiting high performance across diverse complex datasets has led to a need for compressing network models due to the presence of a significant number of redundant structural units, aiming to more effectively leverage their low-power consumption and biological interpretability advantages. Currently, most model compression techniques for SNNs are based on unstructured pruning of individual connections, which requires specific hardware support. Hence, we propose a structured pruning approach based on the activity levels of convolutional kernels named Spiking Channel Activity-based (SCA) network pruning framework. Inspired by synaptic plasticity mechanisms, our method dynamically adjusts the network's structure by pruning and regenerating convolutional kernels during training, enhancing the model's adaptation to the current target task. While maintaining model performance, this approach refines the network architecture, ultimately reducing computational load and accelerating the inference process. This indicates that structured dynamic sparse learning methods can better facilitate the application of deep SNNs in low-power and high-efficiency scenarios.
Unveiling and Mitigating Memorization in Text-to-image Diffusion Models through Cross Attention
Mar 17, 2024



Recent advancements in text-to-image diffusion models have demonstrated their remarkable capability to generate high-quality images from textual prompts. However, increasing research indicates that these models memorize and replicate images from their training data, raising tremendous concerns about potential copyright infringement and privacy risks. In our study, we provide a novel perspective to understand this memorization phenomenon by examining its relationship with cross-attention mechanisms. We reveal that during memorization, the cross-attention tends to focus disproportionately on the embeddings of specific tokens. The diffusion model is overfitted to these token embeddings, memorizing corresponding training images. To elucidate this phenomenon, we further identify and discuss various intrinsic findings of cross-attention that contribute to memorization. Building on these insights, we introduce an innovative approach to detect and mitigate memorization in diffusion models. The advantage of our proposed method is that it will not compromise the speed of either the training or the inference processes in these models while preserving the quality of generated images. Our code is available at https://github.com/renjie3/MemAttn .
Enhancing Adaptive History Reserving by Spiking Convolutional Block Attention Module in Recurrent Neural Networks
Jan 08, 2024

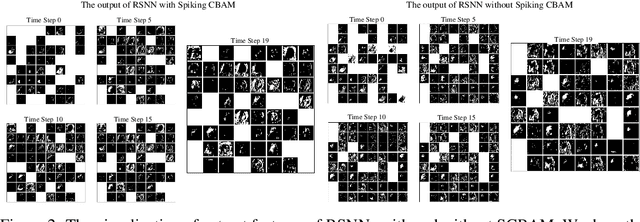
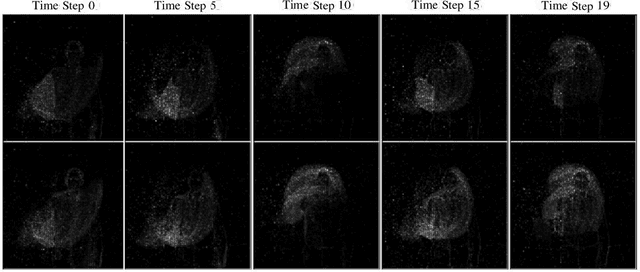
Spiking neural networks (SNNs) serve as one type of efficient model to process spatio-temporal patterns in time series, such as the Address-Event Representation data collected from Dynamic Vision Sensor (DVS). Although convolutional SNNs have achieved remarkable performance on these AER datasets, benefiting from the predominant spatial feature extraction ability of convolutional structure, they ignore temporal features related to sequential time points. In this paper, we develop a recurrent spiking neural network (RSNN) model embedded with an advanced spiking convolutional block attention module (SCBAM) component to combine both spatial and temporal features of spatio-temporal patterns. It invokes the history information in spatial and temporal channels adaptively through SCBAM, which brings the advantages of efficient memory calling and history redundancy elimination. The performance of our model was evaluated in DVS128-Gesture dataset and other time-series datasets. The experimental results show that the proposed SRNN-SCBAM model makes better use of the history information in spatial and temporal dimensions with less memory space, and achieves higher accuracy compared to other models.
Exploring Memorization in Fine-tuned Language Models
Oct 10, 2023



LLMs have shown great capabilities in various tasks but also exhibited memorization of training data, thus raising tremendous privacy and copyright concerns. While prior work has studied memorization during pre-training, the exploration of memorization during fine-tuning is rather limited. Compared with pre-training, fine-tuning typically involves sensitive data and diverse objectives, thus may bring unique memorization behaviors and distinct privacy risks. In this work, we conduct the first comprehensive analysis to explore LMs' memorization during fine-tuning across tasks. Our studies with open-sourced and our own fine-tuned LMs across various tasks indicate that fine-tuned memorization presents a strong disparity among tasks. We provide an understanding of this task disparity via sparse coding theory and unveil a strong correlation between memorization and attention score distribution. By investigating its memorization behavior, multi-task fine-tuning paves a potential strategy to mitigate fine-tuned memorization.
3D Reconstruction of Spherical Images based on Incremental Structure from Motion
Jun 24, 20233D reconstruction plays an increasingly important role in modern photogrammetric systems. Conventional satellite or aerial-based remote sensing (RS) platforms can provide the necessary data sources for the 3D reconstruction of large-scale landforms and cities. Even with low-altitude UAVs (Unmanned Aerial Vehicles), 3D reconstruction in complicated situations, such as urban canyons and indoor scenes, is challenging due to the frequent tracking failures between camera frames and high data collection costs. Recently, spherical images have been extensively exploited due to the capability of recording surrounding environments from one camera exposure. Classical 3D reconstruction pipelines, however, cannot be used for spherical images. Besides, there exist few software packages for 3D reconstruction of spherical images. Based on the imaging geometry of spherical cameras, this study investigates the algorithms for the relative orientation using spherical correspondences, absolute orientation using 3D correspondences between scene and spherical points, and the cost functions for BA (bundle adjustment) optimization. In addition, an incremental SfM (Structure from Motion) workflow has been proposed for spherical images using the above-mentioned algorithms. The proposed solution is finally verified by using three spherical datasets captured by both consumer-grade and professional spherical cameras. The results demonstrate that the proposed SfM workflow can achieve the successful 3D reconstruction of complex scenes and provide useful clues for the implementation in open-source software packages. The source code of the designed SfM workflow would be made publicly available.
Biologically inspired structure learning with reverse knowledge distillation for spiking neural networks
Apr 19, 2023Spiking neural networks (SNNs) have superb characteristics in sensory information recognition tasks due to their biological plausibility. However, the performance of some current spiking-based models is limited by their structures which means either fully connected or too-deep structures bring too much redundancy. This redundancy from both connection and neurons is one of the key factors hindering the practical application of SNNs. Although Some pruning methods were proposed to tackle this problem, they normally ignored the fact the neural topology in the human brain could be adjusted dynamically. Inspired by this, this paper proposed an evolutionary-based structure construction method for constructing more reasonable SNNs. By integrating the knowledge distillation and connection pruning method, the synaptic connections in SNNs can be optimized dynamically to reach an optimal state. As a result, the structure of SNNs could not only absorb knowledge from the teacher model but also search for deep but sparse network topology. Experimental results on CIFAR100 and DVS-Gesture show that the proposed structure learning method can get pretty well performance while reducing the connection redundancy. The proposed method explores a novel dynamical way for structure learning from scratch in SNNs which could build a bridge to close the gap between deep learning and bio-inspired neural dynamics.