 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond NL2Code: A Structured Survey of Multimodal Code Intelligence
Jun 16, 2026While Large Language Models (LLMs) have substantially advanced text-to-code synthesis, many real programming tasks specify intent through visual artifacts such as screenshots, charts, vector drawings, videos, and interactive states. These tasks require models to connect visual perception to executable programs, because correctness depends not only on syntax but also on layout, data semantics, interaction behavior, and domain-specific constraints that apply after execution. This survey examines Multimodal Code Intelligence, covering systems that generate, edit, refine, or reason with code under visually grounded inputs and outputs. We first formulate the field by the role that code plays in each task, distinguishing code as a rendered artifact, an editable symbolic structure, a scientific representation, an intermediate reasoning trace, or an executable policy or tool interface. We then organize benchmarks and methods into four domains: Graphical User Interface, Scientific Visualization, Structured Graphics, and Frontier Tasks and Frameworks. This taxonomy connects mature artifact-generation problems to emerging agentic and unified settings and allows us to compare how different tasks treat evidence of correctness. Looking ahead, we argue that future research may benefit from four verification-centered directions. Multi-signal validation can combine complementary evidence of correctness, multi-state verification can test behavior across execution trajectories, cross-task transfer testing can probe reusable visual-code skills, and verifiable agent traces can reveal whether agent actions are grounded in visual evidence. Together, these directions may move this field from single-output imitation toward evidence-grounded executable systems. An ongoing project and resources are available on \href{https://github.com/xjywhu/Awesome-Multimodal-LLM-for-Code}{GitHub}.
Cookie-Bench: Continuous On-screen Key Interaction Evaluation for Web Generation
May 28, 2026Front-end web code has become a core product surface for every frontier LLM release, yet evaluating these interactive applications at development speed remains costly because human-judged leaderboards like Arena do not scale. Existing automated proxies typically lean on reference implementations, test suites, or rigid checklists, and tend to miss the reasoned synthesis a human reviewer performs over a live session. We articulate a new evaluation regime that is simultaneously reference-free, autonomously driven, and holistically reasoned, and instantiate it through two artifacts. \textbf{\dataname} is an 11-domain, 54-leaf, 1,000-query WebDev benchmark spanning both static-presentation and interactive-application tasks, balanced across three difficulty tiers and three target-language groups, with briefs rewritten to resist recall from circulated prompts. \textbf{\framename}, grounded in Flavell's metacognitive monitoring, separates evidence accumulation from judgment across three stages: Static Perception forms a first impression from passive observation; Agent-Driven Interaction explores the application autonomously while capturing continuous screen video, audio, and per-step screenshots; Dynamic Scoring issues holistic functionality and aesthetics verdicts with structured failure attribution only after the evidence chain is complete. On \dataname, \framename aligns closely with expert human ratings while surfacing substantial headroom across 13 frontier LLMs on interactive web generation. \noindenthttps://anonymous.4open.science/r/Cookie-3CE/
OmniDiagram: Advancing Unified Diagram Code Generation via Visual Interrogation Reward
Apr 07, 2026The paradigm of programmable diagram generation is evolving rapidly, playing a crucial role in structured visualization. However, most existing studies are confined to a narrow range of task formulations and language support, constraining their applicability to diverse diagram types. In this work, we propose OmniDiagram, a unified framework that incorporates diverse diagram code languages and task definitions. To address the challenge of aligning code logic with visual fidelity in Reinforcement Learning (RL), we introduce a novel visual feedback strategy named Visual Interrogation Verifies All (\textsc{Viva}). Unlike brittle syntax-based rules or pixel-level matching, \textsc{Viva} rewards the visual structure of rendered diagrams through a generative approach. Specifically, \textsc{Viva} actively generates targeted visual inquiries to scrutinize diagram visual fidelity and provides fine-grained feedback for optimization. This mechanism facilitates a self-evolving training process, effectively obviating the need for manually annotated ground truth code. Furthermore, we construct M3$^2$Diagram, the first large-scale diagram code generation dataset, containing over 196k high-quality instances. Experimental results confirm that the combination of SFT and our \textsc{Viva}-based RL allows OmniDiagram to establish a new state-of-the-art (SOTA) across diagram code generation benchmarks.
Automating Hardware Design and Verification from Architectural Papers via a Neural-Symbolic Graph Framework
Nov 08, 2025The reproduction of hardware architectures from academic papers remains a significant challenge due to the lack of publicly available source code and the complexity of hardware description languages (HDLs). To this end, we propose \textbf{ArchCraft}, a Framework that converts abstract architectural descriptions from academic papers into synthesizable Verilog projects with register-transfer level (RTL) verification. ArchCraft introduces a structured workflow, which uses formal graphs to capture the Architectural Blueprint and symbols to define the Functional Specification, translating unstructured academic papers into verifiable, hardware-aware designs. The framework then generates RTL and testbench (TB) code decoupled via these symbols to facilitate verification and debugging, ultimately reporting the circuit's Power, Area, and Performance (PPA). Moreover, we propose the first benchmark, \textbf{ArchSynthBench}, for synthesizing hardware from architectural descriptions, with a complete set of evaluation indicators, 50 project-level circuits, and around 600 circuit blocks. We systematically assess ArchCraft on ArchSynthBench, where the experiment results demonstrate the superiority of our proposed method, surpassing direct generation methods and the VerilogCoder framework in both paper understanding and code completion. Furthermore, evaluation and physical implementation of the generated executable RTL code show that these implementations meet all timing constraints without violations, and their performance metrics are consistent with those reported in the original papers.
ChartEdit: How Far Are MLLMs From Automating Chart Analysis? Evaluating MLLMs' Capability via Chart Editing
May 17, 2025Although multimodal large language models (MLLMs) show promise in generating chart rendering code, chart editing presents a greater challenge. This difficulty stems from its nature as a labor-intensive task for humans that also demands MLLMs to integrate chart understanding, complex reasoning, and precise intent interpretation. While many MLLMs claim such editing capabilities, current assessments typically rely on limited case studies rather than robust evaluation methodologies, highlighting the urgent need for a comprehensive evaluation framework. In this work, we propose ChartEdit, a new high-quality benchmark designed for chart editing tasks. This benchmark comprises $1,405$ diverse editing instructions applied to $233$ real-world charts, with each instruction-chart instance having been manually annotated and validated for accuracy. Utilizing ChartEdit, we evaluate the performance of 10 mainstream MLLMs across two types of experiments, assessing them at both the code and chart levels. The results suggest that large-scale models can generate code to produce images that partially match the reference images. However, their ability to generate accurate edits according to the instructions remains limited. The state-of-the-art (SOTA) model achieves a score of only $59.96$, highlighting significant challenges in precise modification. In contrast, small-scale models, including chart-domain models, struggle both with following editing instructions and generating overall chart images, underscoring the need for further development in this area. Code is available at https://github.com/xxlllz/ChartEdit.
Beyond Guilt: Legal Judgment Prediction with Trichotomous Reasoning
Dec 19, 2024



In legal practice, judges apply the trichotomous dogmatics of criminal law, sequentially assessing the elements of the offense, unlawfulness, and culpability to determine whether an individual's conduct constitutes a crime. Although current legal large language models (LLMs) show promising accuracy in judgment prediction, they lack trichotomous reasoning capabilities due to the absence of an appropriate benchmark dataset, preventing them from predicting innocent outcomes. As a result, every input is automatically assigned a charge, limiting their practical utility in legal contexts. To bridge this gap, we introduce LJPIV, the first benchmark dataset for Legal Judgment Prediction with Innocent Verdicts. Adhering to the trichotomous dogmatics, we extend three widely-used legal datasets through LLM-based augmentation and manual verification. Our experiments with state-of-the-art legal LLMs and novel strategies that integrate trichotomous reasoning into zero-shot prompting and fine-tuning reveal: (1) current legal LLMs have significant room for improvement, with even the best models achieving an F1 score of less than 0.3 on LJPIV; and (2) our strategies notably enhance both in-domain and cross-domain judgment prediction accuracy, especially for cases resulting in an innocent verdict.
ControlBurn: Nonlinear Feature Selection with Sparse Tree Ensembles
Jul 08, 2022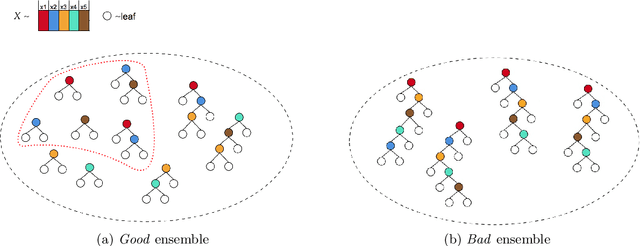

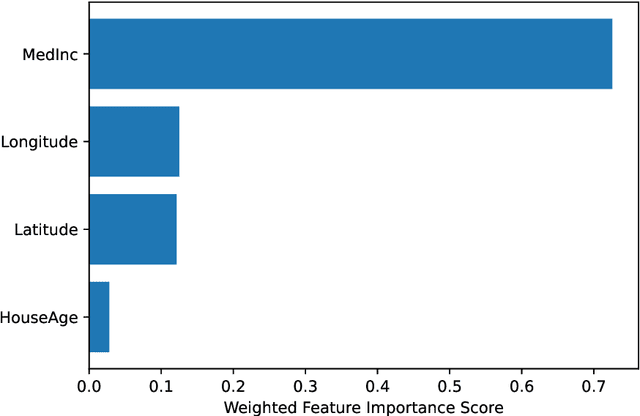
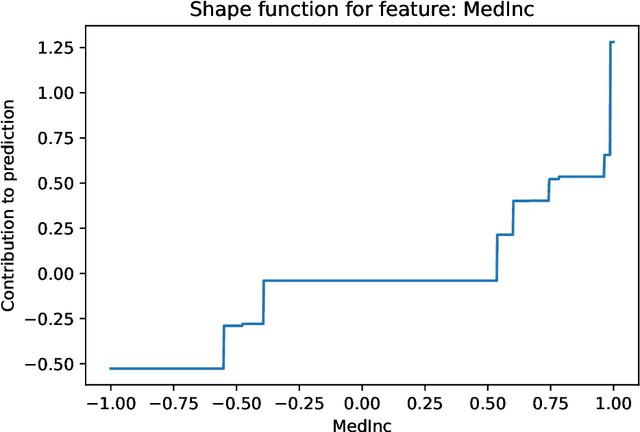
ControlBurn is a Python package to construct feature-sparse tree ensembles that support nonlinear feature selection and interpretable machine learning. The algorithms in this package first build large tree ensembles that prioritize basis functions with few features and then select a feature-sparse subset of these basis functions using a weighted lasso optimization criterion. The package includes visualizations to analyze the features selected by the ensemble and their impact on predictions. Hence ControlBurn offers the accuracy and flexibility of tree-ensemble models and the interpretability of sparse generalized additive models. ControlBurn is scalable and flexible: for example, it can use warm-start continuation to compute the regularization path (prediction error for any number of selected features) for a dataset with tens of thousands of samples and hundreds of features in seconds. For larger datasets, the runtime scales linearly in the number of samples and features (up to a log factor), and the package support acceleration using sketching. Moreover, the ControlBurn framework accommodates feature costs, feature groupings, and $\ell_0$-based regularizers. The package is user-friendly and open-source: its documentation and source code appear on https://pypi.org/project/ControlBurn/ and https://github.com/udellgroup/controlburn/.