 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubsurfaceGen: Procedural Generation of Field-Scale Earth Models and Seismic Data
May 28, 2026Full waveform inversion (FWI) is the gold standard for subsurface imaging, with applications from carbon sequestration to energy and mineral exploration to earthquake hazard assessment. Machine learning approaches to FWI need field-scale, geologically diverse, and physically realistic training data, but existing resources such as Marmousi, SEAM, and OpenFWI fall short on spatial extent, temporal extent, geological diversity, and physical realism. We address these limitations with SubsurfaceGen, a GPU-accelerated generator for 3D velocity models and seismic data. Along with SubsurfaceGen, we release a paired dataset of 4,276 2D velocity slices, 5 s wavefields, and 8 s shot gathers drawn from 42 realistic, field-scale 3D velocity models, each spanning 10 km x 10 km laterally and 6.19 km deep at 10 m resolution. The dataset spans six geological settings -- four built with SubsurfaceGen and two drawn from prior sources -- relevant for carbon sequestration and hydrocarbon exploration. We use this dataset to evaluate neural operators on wavefield prediction and encoder-decoders on end-to-end velocity inversion, holding out one geological setting for out-of-distribution testing. These experiments surface failure modes at field-scale and demonstrate how SubsurfaceGen and the associated dataset can impact ML-based FWI.
ShapeBench: A Scalable Benchmark and Diagnostic Suite for Standardized Evaluation in Aerodynamic Shape Optimization
May 20, 2026Rapid progress in aerodynamic shape optimization (ASO) has outpaced currently-available standardized evaluation frameworks. Fair comparison requires a unified benchmark spanning diverse shape classes, objective formulations, and matched-budget state-of-the-art baselines. We introduce ShapeBench, an open-source ASO benchmark with a unified API spanning 103 tasks across eight shape categories and multiple optimization regimes. Each ShapeBench task includes a validated surrogate for fast search; when feasible, a high-fidelity Computational Fluid Dynamics (CFD) pipeline for final verification is available, enabling systematic fidelity-gap analysis. ShapeBench provides a reproducible protocol with well-configured baselines to compare fairly using a consistent budget metric, allowing for comparison among both classical and LLM-driven methods, including general-purpose optimizers and a new domain-specialized evolutionary LLM baseline, ShapeEvolve. Results on ShapeBench demonstrate substantial variance in optimizer rankings across shape categories and problem formulations, with mean pairwise Spearman $ρ= 0.013$, so single-task conclusions do not reliably generalize across problem classes. The benchmark is also far from saturation; classical methods are rarely applicable across all shape categories and tasks, further highlighting the need for more general-purpose approaches.
SnareNet: Flexible Repair Layers for Neural Networks with Hard Constraints
Feb 10, 2026Neural networks are increasingly used as surrogate solvers and control policies, but unconstrained predictions can violate physical, operational, or safety requirements. We propose SnareNet, a feasibility-controlled architecture for learning mappings whose outputs must satisfy input-dependent nonlinear constraints. SnareNet appends a differentiable repair layer that navigates in the constraint map's range space, steering iterates toward feasibility and producing a repaired output that satisfies constraints to a user-specified tolerance. To stabilize end-to-end training, we introduce adaptive relaxation, which designs a relaxed feasible set that snares the neural network at initialization and shrinks it into the feasible set, enabling early exploration and strict feasibility later in training. On optimization-learning and trajectory planning benchmarks, SnareNet consistently attains improved objective quality while satisfying constraints more reliably than prior work.
Small Gradient Norm Regret for Online Convex Optimization
Jan 20, 2026This paper introduces a new problem-dependent regret measure for online convex optimization with smooth losses. The notion, which we call the $G^\star$ regret, depends on the cumulative squared gradient norm evaluated at the decision in hindsight $\sum_{t=1}^T \|\nabla \ell(x^\star)\|^2$. We show that the $G^\star$ regret strictly refines the existing $L^\star$ (small loss) regret, and that it can be arbitrarily sharper when the losses have vanishing curvature around the hindsight decision. We establish upper and lower bounds on the $G^\star$ regret and extend our results to dynamic regret and bandit settings. As a byproduct, we refine the existing convergence analysis of stochastic optimization algorithms in the interpolation regime. Some experiments validate our theoretical findings.
Gradient Methods with Online Scaling Part I. Theoretical Foundations
May 29, 2025This paper establishes the theoretical foundations of the online scaled gradient methods (OSGM), a framework that utilizes online learning to adapt stepsizes and provably accelerate first-order methods. OSGM quantifies the effectiveness of a stepsize by a feedback function motivated from a convergence measure and uses the feedback to adjust the stepsize through an online learning algorithm. Consequently, instantiations of OSGM achieve convergence rates that are asymptotically no worse than the optimal stepsize. OSGM yields desirable convergence guarantees on smooth convex problems, including 1) trajectory-dependent global convergence on smooth convex objectives; 2) an improved complexity result on smooth strongly convex problems, and 3) local superlinear convergence. Notably, OSGM constitutes a new family of first-order methods with non-asymptotic superlinear convergence, joining the celebrated quasi-Newton methods. Finally, OSGM explains the empirical success of the popular hypergradient-descent heuristic in optimization for machine learning.
Turbocharging Gaussian Process Inference with Approximate Sketch-and-Project
May 19, 2025Gaussian processes (GPs) play an essential role in biostatistics, scientific machine learning, and Bayesian optimization for their ability to provide probabilistic predictions and model uncertainty. However, GP inference struggles to scale to large datasets (which are common in modern applications), since it requires the solution of a linear system whose size scales quadratically with the number of samples in the dataset. We propose an approximate, distributed, accelerated sketch-and-project algorithm ($\texttt{ADASAP}$) for solving these linear systems, which improves scalability. We use the theory of determinantal point processes to show that the posterior mean induced by sketch-and-project rapidly converges to the true posterior mean. In particular, this yields the first efficient, condition number-free algorithm for estimating the posterior mean along the top spectral basis functions, showing that our approach is principled for GP inference. $\texttt{ADASAP}$ outperforms state-of-the-art solvers based on conjugate gradient and coordinate descent across several benchmark datasets and a large-scale Bayesian optimization task. Moreover, $\texttt{ADASAP}$ scales to a dataset with $> 3 \cdot 10^8$ samples, a feat which has not been accomplished in the literature.
Understanding Fixed Predictions via Confined Regions
Feb 22, 2025Machine learning models are designed to predict outcomes using features about an individual, but fail to take into account how individuals can change them. Consequently, models can assign fixed predictions that deny individuals recourse to change their outcome. This work develops a new paradigm to identify fixed predictions by finding confined regions in which all individuals receive fixed predictions. We introduce the first method, ReVer, for this task, using tools from mixed-integer quadratically constrained programming. Our approach certifies recourse for out-of-sample data, provides interpretable descriptions of confined regions, and runs in seconds on real world datasets. We conduct a comprehensive empirical study of confined regions across diverse applications. Our results highlight that existing point-wise verification methods fail to discover confined regions, while ReVer provably succeeds.
Enhancing Physics-Informed Neural Networks Through Feature Engineering
Feb 11, 2025Physics-Informed Neural Networks (PINNs) seek to solve partial differential equations (PDEs) with deep learning. Mainstream approaches that deploy fully-connected multi-layer deep learning architectures require prolonged training to achieve even moderate accuracy, while recent work on feature engineering allows higher accuracy and faster convergence. This paper introduces SAFE-NET, a Single-layered Adaptive Feature Engineering NETwork that achieves orders-of-magnitude lower errors with far fewer parameters than baseline feature engineering methods. SAFE-NET returns to basic ideas in machine learning, using Fourier features, a simplified single hidden layer network architecture, and an effective optimizer that improves the conditioning of the PINN optimization problem. Numerical results show that SAFE-NET converges faster and typically outperforms deeper networks and more complex architectures. It consistently uses fewer parameters -- on average, 65% fewer than the competing feature engineering methods -- while achieving comparable accuracy in less than 30% of the training epochs. Moreover, each SAFE-NET epoch is 95% faster than those of competing feature engineering approaches. These findings challenge the prevailing belief that modern PINNs effectively learn features in these scientific applications and highlight the efficiency gains possible through feature engineering.
SAPPHIRE: Preconditioned Stochastic Variance Reduction for Faster Large-Scale Statistical Learning
Jan 27, 2025Regularized empirical risk minimization (rERM) has become important in data-intensive fields such as genomics and advertising, with stochastic gradient methods typically used to solve the largest problems. However, ill-conditioned objectives and non-smooth regularizers undermine the performance of traditional stochastic gradient methods, leading to slow convergence and significant computational costs. To address these challenges, we propose the $\texttt{SAPPHIRE}$ ($\textbf{S}$ketching-based $\textbf{A}$pproximations for $\textbf{P}$roximal $\textbf{P}$reconditioning and $\textbf{H}$essian $\textbf{I}$nexactness with Variance-$\textbf{RE}$educed Gradients) algorithm, which integrates sketch-based preconditioning to tackle ill-conditioning and uses a scaled proximal mapping to minimize the non-smooth regularizer. This stochastic variance-reduced algorithm achieves condition-number-free linear convergence to the optimum, delivering an efficient and scalable solution for ill-conditioned composite large-scale convex machine learning problems. Extensive experiments on lasso and logistic regression demonstrate that $\texttt{SAPPHIRE}$ often converges $20$ times faster than other common choices such as $\texttt{Catalyst}$, $\texttt{SAGA}$, and $\texttt{SVRG}$. This advantage persists even when the objective is non-convex or the preconditioner is infrequently updated, highlighting its robust and practical effectiveness.
LLMs for Cold-Start Cutting Plane Separator Configuration
Dec 16, 2024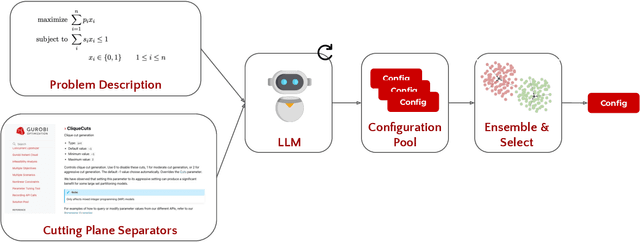
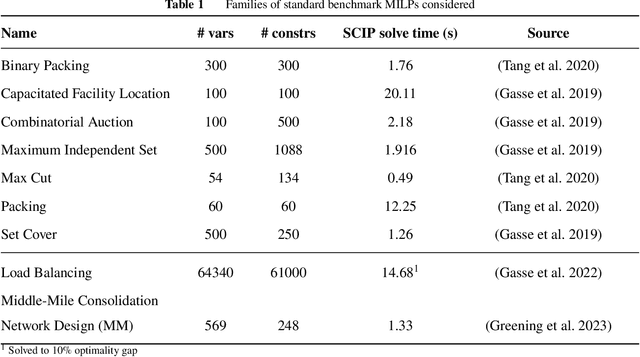

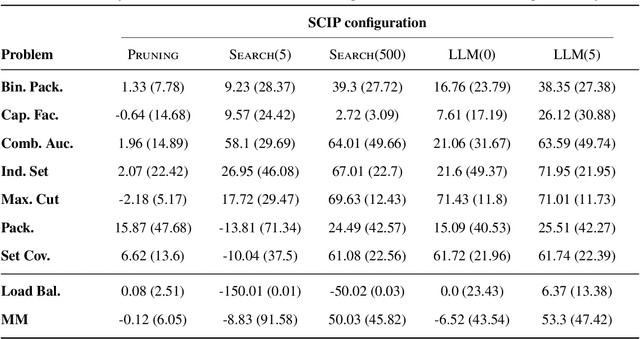
Mixed integer linear programming (MILP) solvers ship with a staggering number of parameters that are challenging to select a priori for all but expert optimization users, but can have an outsized impact on the performance of the MILP solver. Existing machine learning (ML) approaches to configure solvers require training ML models by solving thousands of related MILP instances, generalize poorly to new problem sizes, and often require implementing complex ML pipelines and custom solver interfaces that can be difficult to integrate into existing optimization workflows. In this paper, we introduce a new LLM-based framework to configure which cutting plane separators to use for a given MILP problem with little to no training data based on characteristics of the instance, such as a natural language description of the problem and the associated LaTeX formulation. We augment these LLMs with descriptions of cutting plane separators available in a given solver, grounded by summarizing the existing research literature on separators. While individual solver configurations have a large variance in performance, we present a novel ensembling strategy that clusters and aggregates configurations to create a small portfolio of high-performing configurations. Our LLM-based methodology requires no custom solver interface, can find a high-performing configuration by solving only a small number of MILPs, and can generate the configuration with simple API calls that run in under a second. Numerical results show our approach is competitive with existing configuration approaches on a suite of classic combinatorial optimization problems and real-world datasets with only a fraction of the training data and computation time.