 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnware of Language Models: Specialized Small Language Models Can Do Big
May 19, 2025The learnware paradigm offers a novel approach to machine learning by enabling users to reuse a set of well-trained models for tasks beyond the models' original purposes. It eliminates the need to build models from scratch, instead relying on specifications (representations of a model's capabilities) to identify and leverage the most suitable models for new tasks. While learnware has proven effective in many scenarios, its application to language models has remained largely unexplored. At the same time, large language models (LLMs) have demonstrated remarkable universal question-answering abilities, yet they face challenges in specialized scenarios due to data scarcity, privacy concerns, and high computational costs, thus more and more specialized small language models (SLMs) are being trained for specific domains. To address these limitations systematically, the learnware paradigm provides a promising solution by enabling maximum utilization of specialized SLMs, and allowing users to identify and reuse them in a collaborative and privacy-preserving manner. This paper presents a preliminary attempt to apply the learnware paradigm to language models. We simulated a learnware system comprising approximately 100 learnwares of specialized SLMs with 8B parameters, fine-tuned across finance, healthcare, and mathematics domains. Each learnware contains an SLM and a specification, which enables users to identify the most relevant models without exposing their own data. Experimental results demonstrate promising performance: by selecting one suitable learnware for each task-specific inference, the system outperforms the base SLMs on all benchmarks. Compared to LLMs, the system outperforms Qwen1.5-110B, Qwen2.5-72B, and Llama3.1-70B-Instruct by at least 14% in finance domain tasks, and surpasses Flan-PaLM-540B (ranked 7th on the Open Medical LLM Leaderboard) in medical domain tasks.
AI-Driven Review Systems: Evaluating LLMs in Scalable and Bias-Aware Academic Reviews
Aug 19, 2024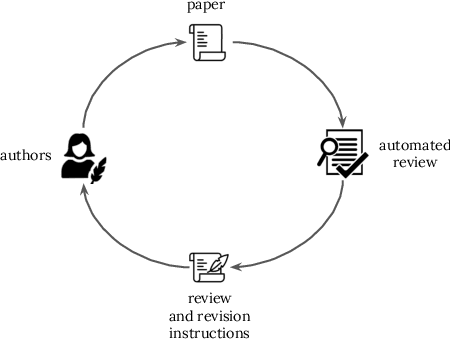

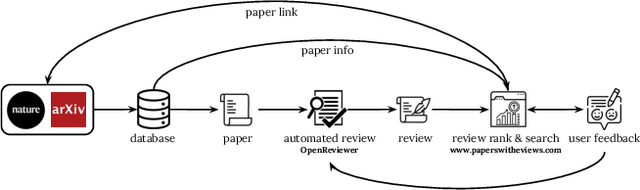

Automatic reviewing helps handle a large volume of papers, provides early feedback and quality control, reduces bias, and allows the analysis of trends. We evaluate the alignment of automatic paper reviews with human reviews using an arena of human preferences by pairwise comparisons. Gathering human preference may be time-consuming; therefore, we also use an LLM to automatically evaluate reviews to increase sample efficiency while reducing bias. In addition to evaluating human and LLM preferences among LLM reviews, we fine-tune an LLM to predict human preferences, predicting which reviews humans will prefer in a head-to-head battle between LLMs. We artificially introduce errors into papers and analyze the LLM's responses to identify limitations, use adaptive review questions, meta prompting, role-playing, integrate visual and textual analysis, use venue-specific reviewing materials, and predict human preferences, improving upon the limitations of the traditional review processes. We make the reviews of publicly available arXiv and open-access Nature journal papers available online, along with a free service which helps authors review and revise their research papers and improve their quality. This work develops proof-of-concept LLM reviewing systems that quickly deliver consistent, high-quality reviews and evaluate their quality. We mitigate the risks of misuse, inflated review scores, overconfident ratings, and skewed score distributions by augmenting the LLM with multiple documents, including the review form, reviewer guide, code of ethics and conduct, area chair guidelines, and previous year statistics, by finding which errors and shortcomings of the paper may be detected by automated reviews, and evaluating pairwise reviewer preferences. This work identifies and addresses the limitations of using LLMs as reviewers and evaluators and enhances the quality of the reviewing process.
On Training Implicit Models
Nov 24, 2021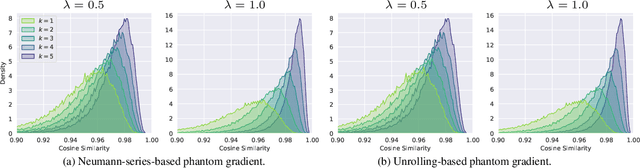
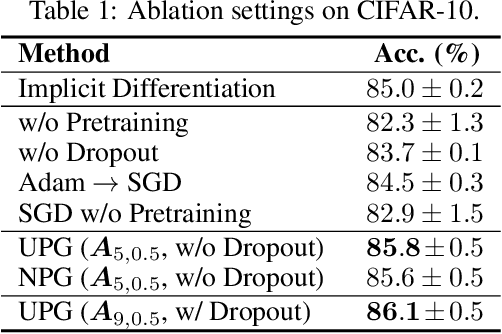

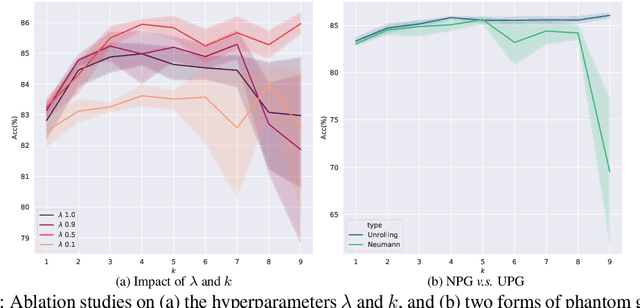
This paper focuses on training implicit models of infinite layers. Specifically, previous works employ implicit differentiation and solve the exact gradient for the backward propagation. However, is it necessary to compute such an exact but expensive gradient for training? In this work, we propose a novel gradient estimate for implicit models, named phantom gradient, that 1) forgoes the costly computation of the exact gradient; and 2) provides an update direction empirically preferable to the implicit model training. We theoretically analyze the condition under which an ascent direction of the loss landscape could be found, and provide two specific instantiations of the phantom gradient based on the damped unrolling and Neumann series. Experiments on large-scale tasks demonstrate that these lightweight phantom gradients significantly accelerate the backward passes in training implicit models by roughly 1.7 times, and even boost the performance over approaches based on the exact gradient on ImageNet.
Learnable Cost Volume Using the Cayley Representation
Jul 21, 2020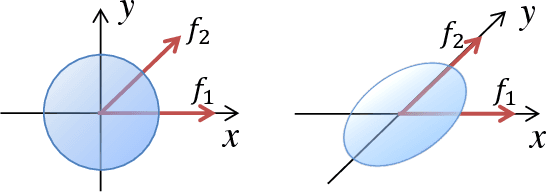
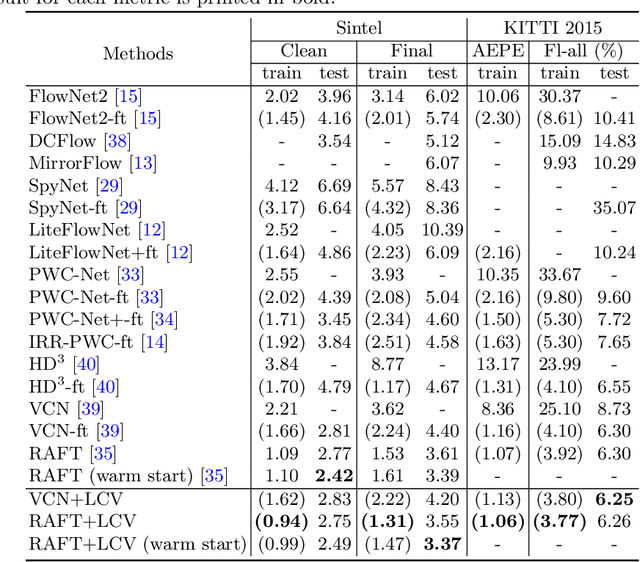

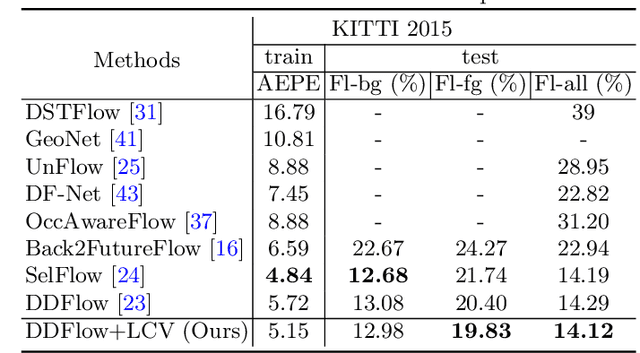
Cost volume is an essential component of recent deep models for optical flow estimation and is usually constructed by calculating the inner product between two feature vectors. However, the standard inner product in the commonly-used cost volume may limit the representation capacity of flow models because it neglects the correlation among different channel dimensions and weighs each dimension equally. To address this issue, we propose a learnable cost volume (LCV) using an elliptical inner product, which generalizes the standard inner product by a positive definite kernel matrix. To guarantee its positive definiteness, we perform spectral decomposition on the kernel matrix and re-parameterize it via the Cayley representation. The proposed LCV is a lightweight module and can be easily plugged into existing models to replace the vanilla cost volume. Experimental results show that the LCV module not only improves the accuracy of state-of-the-art models on standard benchmarks, but also promotes their robustness against illumination change, noises, and adversarial perturbations of the input signals.
Semi-Supervised Learning with Meta-Gradient
Jul 08, 2020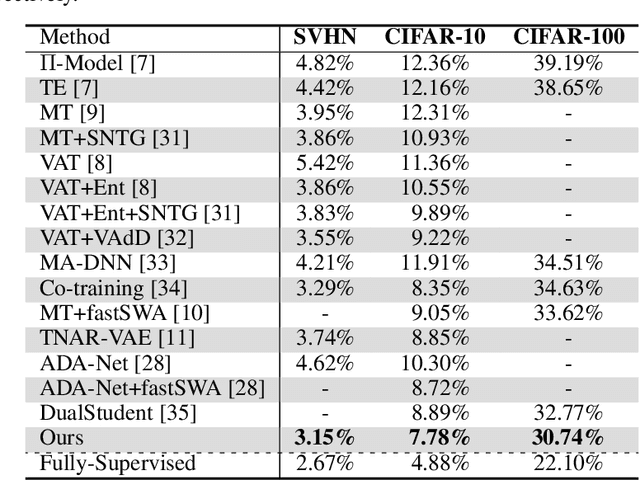
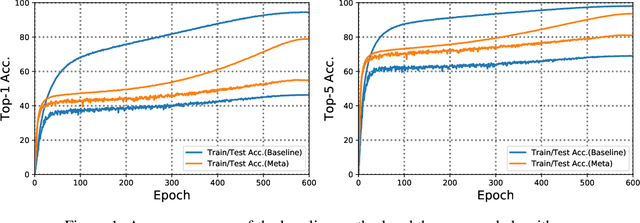
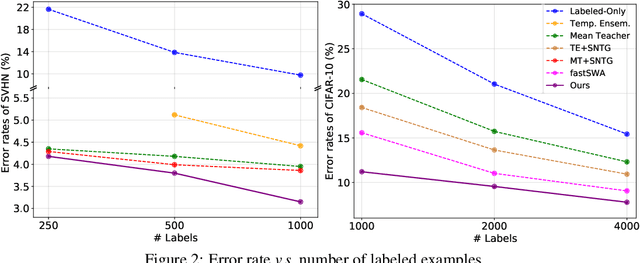
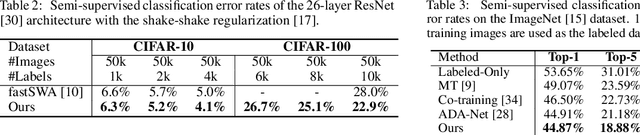
In this work, we propose a simple yet effective meta-learning algorithm in thesemi-supervised settings. We notice that existing consistency-based approachesmostly do not consider the essential role of the label information for consistencyregularization. To alleviate this issue, we bridge the relationship between theconsistency loss and label information by unfolding and differentiating throughone optimization step. Specifically, we exploit the pseudo labels of the unlabeledexamples which are guided by the meta-gradients of the labeled data loss so thatthe model can generalize well on the labeled examples. In addition, we introduce asimple first-order approximation to avoid computing higher-order derivatives andguarantee scalability. Extensive evaluations on the SVHN, CIFAR, and ImageNetdatasets demonstrate that the proposed algorithm performs favorably against thestate-of-the-art methods.
Dependency Aware Filter Pruning
May 06, 2020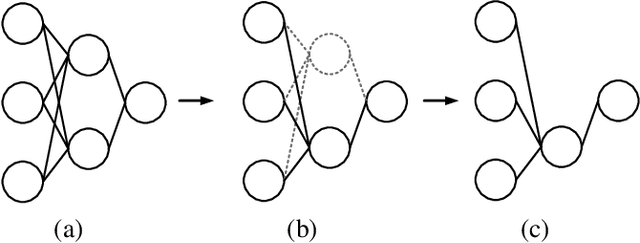

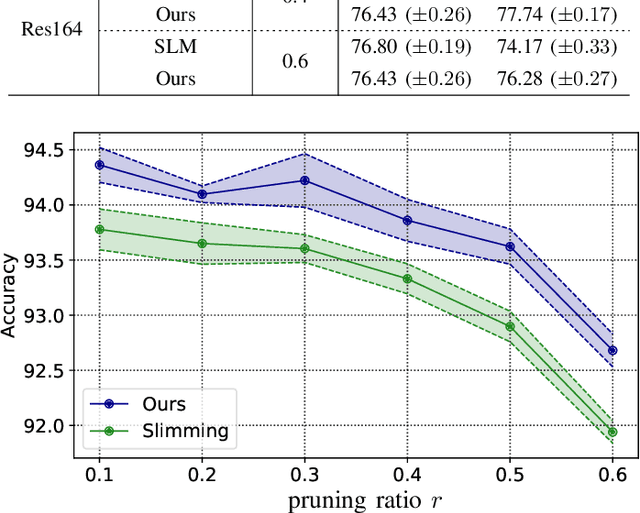
Convolutional neural networks (CNNs) are typically over-parameterized, bringing considerable computational overhead and memory footprint in inference. Pruning a proportion of unimportant filters is an efficient way to mitigate the inference cost. For this purpose, identifying unimportant convolutional filters is the key to effective filter pruning. Previous work prunes filters according to either their weight norms or the corresponding batch-norm scaling factors, while neglecting the sequential dependency between adjacent layers. In this paper, we further develop the norm-based importance estimation by taking the dependency between the adjacent layers into consideration. Besides, we propose a novel mechanism to dynamically control the sparsity-inducing regularization so as to achieve the desired sparsity. In this way, we can identify unimportant filters and search for the optimal network architecture within certain resource budgets in a more principled manner. Comprehensive experimental results demonstrate the proposed method performs favorably against the existing strong baseline on the CIFAR, SVHN, and ImageNet datasets. The training sources will be publicly available after the review process.
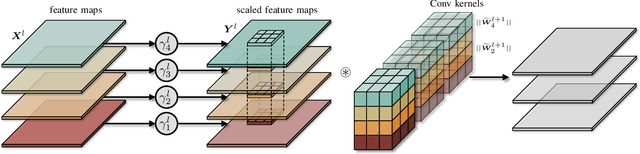
Model-Agnostic Structured Sparsification with Learnable Channel Shuffle
Feb 19, 2020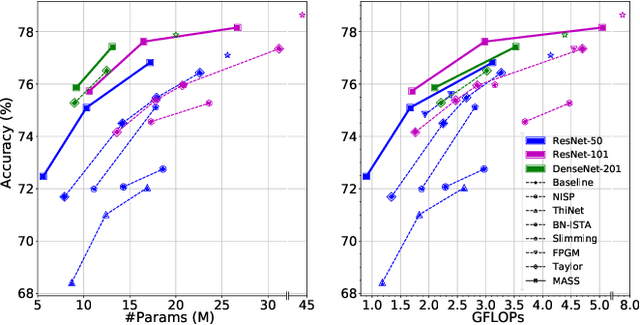

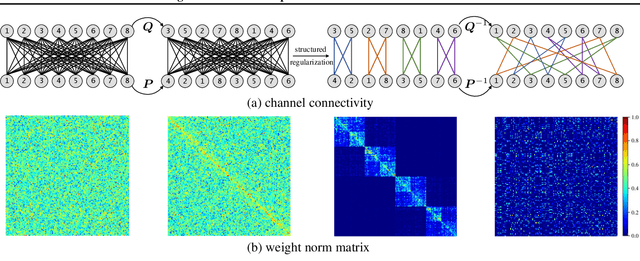
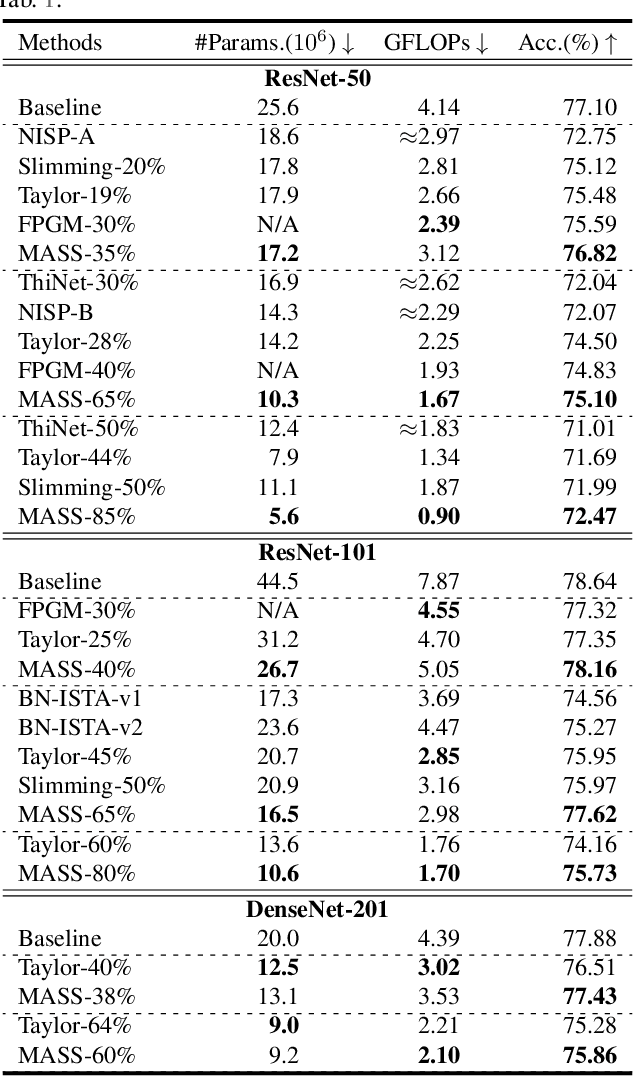
Recent advances in convolutional neural networks (CNNs) usually come with the expense of considerable computational overhead and memory footprint. Network compression aims to alleviate this issue by training compact models with comparable performance. However, existing compression techniques either entail dedicated expert design or compromise with a moderate performance drop. To this end, we propose a model-agnostic structured sparsification method for efficient network compression. The proposed method automatically induces structurally sparse representations of the convolutional weights, thereby facilitating the implementation of the compressed model with the highly-optimized group convolution. We further address the problem of inter-group communication with a learnable channel shuffle mechanism. The proposed approach is model-agnostic and highly compressible with a negligible performance drop. Extensive experimental results and analysis demonstrate that our approach performs favorably against the state-of-the-art network pruning methods. The code will be publicly available after the review process.
AdaSample: Adaptive Sampling of Hard Positives for Descriptor Learning
Nov 27, 2019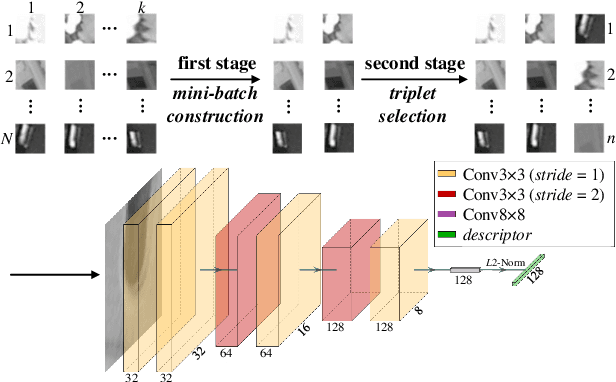
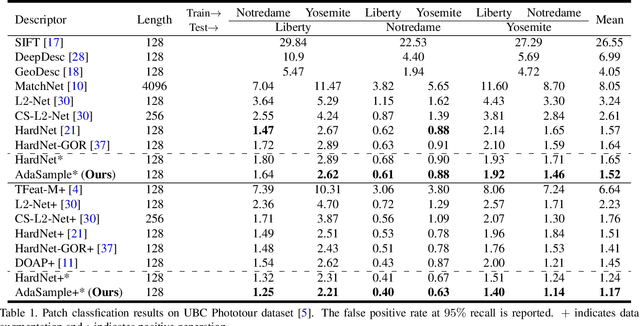
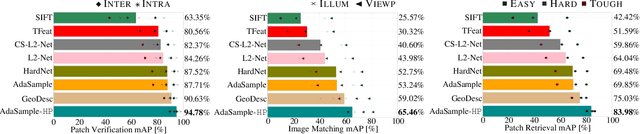
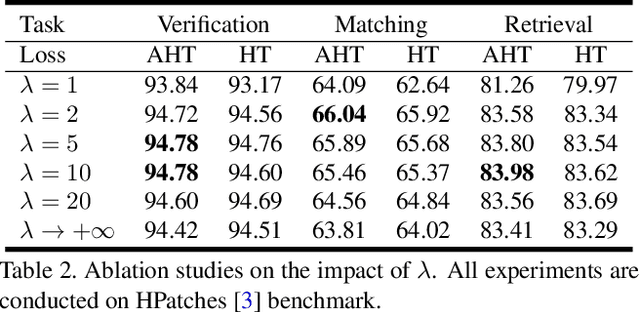
Triplet loss has been widely employed in a wide range of computer vision tasks, including local descriptor learning. The effectiveness of the triplet loss heavily relies on the triplet selection, in which a common practice is to first sample intra-class patches (positives) from the dataset for batch construction and then mine in-batch negatives to form triplets. For high-informativeness triplet collection, researchers mostly focus on mining hard negatives in the second stage, while paying relatively less attention to constructing informative batches. To alleviate this issue, we propose AdaSample, an adaptive online batch sampler, in this paper. Specifically, hard positives are sampled based on their informativeness. In this way, we formulate a hardness-aware positive mining pipeline within a novel maximum loss minimization training protocol. The efficacy of the proposed method is evaluated on several standard benchmarks, where it demonstrates a significant and consistent performance gain on top of the existing strong baselines.
Res2Net: A New Multi-scale Backbone Architecture
Apr 02, 2019
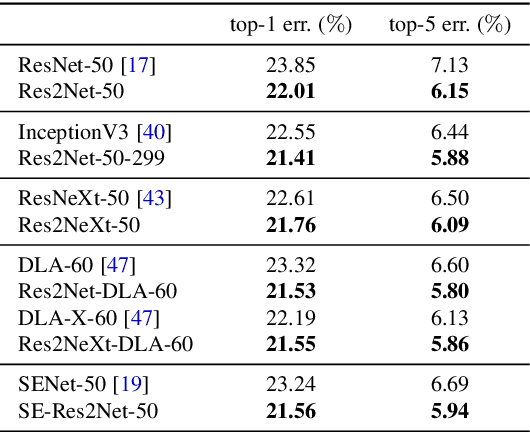
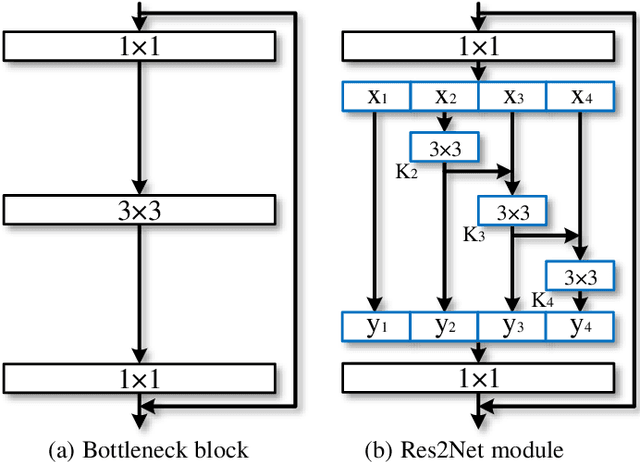
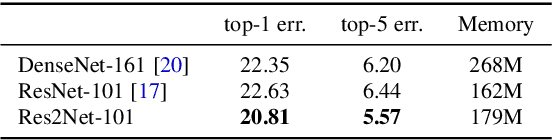
Representing features at multiple scales is of great importance for numerous vision tasks. Recent advances in backbone convolutional neural networks (CNNs) continually demonstrate stronger multi-scale representation ability, leading to consistent performance gains on a wide range of applications. However, most existing methods represent the multi-scale features in a layer-wise manner. In this paper, we propose a novel building block for CNNs, namely Res2Net, by constructing hierarchical residual-like connections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of receptive fields for each network layer. The proposed Res2Net block can be plugged into the state-of-the-art backbone CNN models, e.g., ResNet, ResNeXt, and DLA. We evaluate the Res2Net block on all these models and demonstrate consistent performance gains over baseline models on widely-used datasets, e.g., CIFAR-100 and ImageNet. Further ablation studies and experimental results on representative computer vision tasks, i.e., object detection, class activation mapping, and salient object detection, further verify the superiority of the Res2Net over the state-of-the-art baseline methods. The source code and trained models will be made publicly available.