 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Review Systems: Evaluating LLMs in Scalable and Bias-Aware Academic Reviews
Aug 19, 2024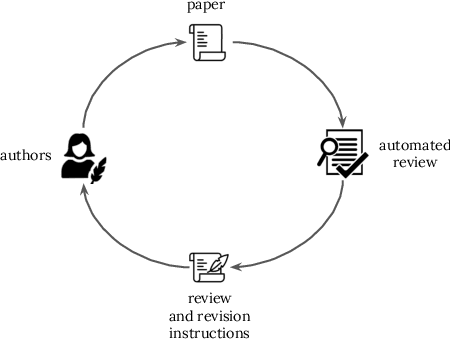

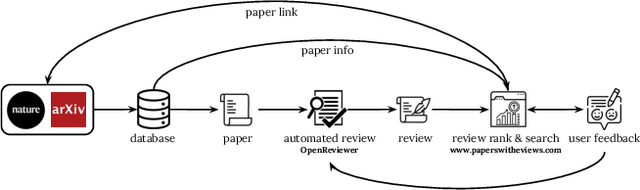

Automatic reviewing helps handle a large volume of papers, provides early feedback and quality control, reduces bias, and allows the analysis of trends. We evaluate the alignment of automatic paper reviews with human reviews using an arena of human preferences by pairwise comparisons. Gathering human preference may be time-consuming; therefore, we also use an LLM to automatically evaluate reviews to increase sample efficiency while reducing bias. In addition to evaluating human and LLM preferences among LLM reviews, we fine-tune an LLM to predict human preferences, predicting which reviews humans will prefer in a head-to-head battle between LLMs. We artificially introduce errors into papers and analyze the LLM's responses to identify limitations, use adaptive review questions, meta prompting, role-playing, integrate visual and textual analysis, use venue-specific reviewing materials, and predict human preferences, improving upon the limitations of the traditional review processes. We make the reviews of publicly available arXiv and open-access Nature journal papers available online, along with a free service which helps authors review and revise their research papers and improve their quality. This work develops proof-of-concept LLM reviewing systems that quickly deliver consistent, high-quality reviews and evaluate their quality. We mitigate the risks of misuse, inflated review scores, overconfident ratings, and skewed score distributions by augmenting the LLM with multiple documents, including the review form, reviewer guide, code of ethics and conduct, area chair guidelines, and previous year statistics, by finding which errors and shortcomings of the paper may be detected by automated reviews, and evaluating pairwise reviewer preferences. This work identifies and addresses the limitations of using LLMs as reviewers and evaluators and enhances the quality of the reviewing process.