 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder-based Rehearsal Learning
May 06, 2026When a machine learning (ML) model forecasts an undesired event, one often seeks a decision to avoid it, known as the avoiding undesired future (AUF) problem. Many rehearsal learning methods have been proposed for AUF, but they rely on an underlying graph structure; learning such a graph from observational data is challenging and can incur substantial estimation error. In this work, we demonstrate that the order structure can be sufficient for AUF decision-making, and propose the first order-based rehearsal learning method. Although an order is less informative than a graph, it can be sufficient to identify the influence of decisions from observational data, suggesting that learning the entire graph is not always necessary. To learn the order, we develop an information-theoretic method that imposes no restrictions on the form of structural functions or the type of noise distributions. For AUF decision-making, we construct an order-based sampler to approximate the influence of decisions and, combined with a surrogate objective for maximizing the post-decision success probability, reduce the AUF task to a differentiable optimization problem. Experiments show that our order learning method outperforms existing methods, and that our AUF approach not only surpasses methods relying on learned graphs or learned orders, but also matches or even exceeds oracle baselines that are given the true graph.
How Can Reinforcement Learning Achieve Expert-level Placement?
Apr 28, 2026Chip placement is a critical step in physical design. While reinforcement learning (RL)-based methods have recently emerged, their training primarily focuses on wirelength optimization, and therefore often fail to achieve expert-quality layouts. We identify the reward design as the primary cause for the performance gap with experts, and instead of formalizing intricate processes, we circumvent this by directly learning from expert layouts to derive a reward model. Our approach starts from the final expert layouts to infer step-by-step expert trajectories. Using these trajectories as demonstrations or preferences, we train a model that captures the latent implicit rewards in expert results. Experiments show that our framework can efficiently learn from even a single design and generalize well to unseen cases.
Robust Length Prediction: A Perspective from Heavy-Tailed Prompt-Conditioned Distributions
Apr 09, 2026Output-length prediction is important for efficient LLM serving, as it directly affects batching, memory reservation, and scheduling. For prompt-only length prediction, most existing methods use a one-shot sampled length as the label, implicitly treating each prompt as if it had one true target length. We show that this is unreliable: even under a fixed model and decoding setup, the same prompt induces a \emph{prompt-conditioned output length distribution}, not a deterministic scalar, and this distribution is consistent with \emph{heavy-tailed} behavior. Motivated by this, we cast length prediction as robust estimation from heavy-tailed prompt-conditioned length distributions. We propose prompt-conditioned length distribution (ProD) methods, which construct training targets from multiple independent generations of the same prompt. Two variants are developed to reuse the served LLM's hidden states: \mbox{ProD-M}, which uses a median-based target for robust point prediction, and ProD-D, which uses a distributional target that preserves prompt-conditioned uncertainty. We provide theoretical justifications by analyzing the estimation error under a surrogate model. Experiments across diverse scenarios show consistent gains in prediction quality.
Advancing Automated Algorithm Design via Evolutionary Stagewise Design with LLMs
Mar 09, 2026With the rapid advancement of human science and technology, problems in industrial scenarios are becoming increasingly challenging, bringing significant challenges to traditional algorithm design. Automated algorithm design with LLMs emerges as a promising solution, but the currently adopted black-box modeling deprives LLMs of any awareness of the intrinsic mechanism of the target problem, leading to hallucinated designs. In this paper, we introduce Evolutionary Stagewise Algorithm Design (EvoStage), a novel evolutionary paradigm that bridges the gap between the rigorous demands of industrial-scale algorithm design and the LLM-based algorithm design methods. Drawing inspiration from CoT, EvoStage decomposes the algorithm design process into sequential, manageable stages and integrates real-time intermediate feedback to iteratively refine algorithm design directions. To further reduce the algorithm design space and avoid falling into local optima, we introduce a multi-agent system and a "global-local perspective" mechanism. We apply EvoStage to the design of two types of common optimizers: designing parameter configuration schedules of the Adam optimizer for chip placement, and designing acquisition functions of Bayesian optimization for black-box optimization. Experimental results across open-source benchmarks demonstrate that EvoStage outperforms human-expert designs and existing LLM-based methods within only a couple of evolution steps, even achieving the historically state-of-the-art half-perimeter wire-length results on every tested chip case. Furthermore, when deployed on a commercial-grade 3D chip placement tool, EvoStage significantly surpasses the original performance metrics, achieving record-breaking efficiency. We hope EvoStage can significantly advance automated algorithm design in the real world, helping elevate human productivity.
Dynamic Regret via Discounted-to-Dynamic Reduction with Applications to Curved Losses and Adam Optimizer
Feb 09, 2026We study dynamic regret minimization in non-stationary online learning, with a primary focus on follow-the-regularized-leader (FTRL) methods. FTRL is important for curved losses and for understanding adaptive optimizers such as Adam, yet existing dynamic regret analyses are less explored for FTRL. To address this, we build on the discounted-to-dynamic reduction and present a modular way to obtain dynamic regret bounds of FTRL-related problems. Specifically, we focus on two representative curved losses: linear regression and logistic regression. Our method not only simplifies existing proofs for the optimal dynamic regret of online linear regression, but also yields new dynamic regret guarantees for online logistic regression. Beyond online convex optimization, we apply the reduction to analyze the Adam optimizers, obtaining optimal convergence rates in stochastic, non-convex, and non-smooth settings. The reduction also enables a more detailed treatment of Adam with two discount parameters $(β_1,β_2)$, leading to new results for both clipped and clip-free variants of Adam optimizers.
ZipMoE: Efficient On-Device MoE Serving via Lossless Compression and Cache-Affinity Scheduling
Jan 29, 2026While Mixture-of-Experts (MoE) architectures substantially bolster the expressive power of large-language models, their prohibitive memory footprint severely impedes the practical deployment on resource-constrained edge devices, especially when model behavior must be preserved without relying on lossy quantization. In this paper, we present ZipMoE, an efficient and semantically lossless on-device MoE serving system. ZipMoE exploits the synergy between the hardware properties of edge devices and the statistical redundancy inherent to MoE parameters via a caching-scheduling co-design with provable performance guarantee. Fundamentally, our design shifts the paradigm of on-device MoE inference from an I/O-bound bottleneck to a compute-centric workflow that enables efficient parallelization. We implement a prototype of ZipMoE and conduct extensive experiments on representative edge computing platforms using popular open-source MoE models and real-world workloads. Our evaluation reveals that ZipMoE achieves up to $72.77\%$ inference latency reduction and up to $6.76\times$ higher throughput than the state-of-the-art systems.
A Simple, Optimal and Efficient Algorithm for Online Exp-Concave Optimization
Dec 29, 2025Online eXp-concave Optimization (OXO) is a fundamental problem in online learning. The standard algorithm, Online Newton Step (ONS), balances statistical optimality and computational practicality, guaranteeing an optimal regret of $O(d \log T)$, where $d$ is the dimension and $T$ is the time horizon. ONS faces a computational bottleneck due to the Mahalanobis projections at each round. This step costs $Ω(d^ω)$ arithmetic operations for bounded domains, even for the unit ball, where $ω\in (2,3]$ is the matrix-multiplication exponent. As a result, the total runtime can reach $\tilde{O}(d^ωT)$, particularly when iterates frequently oscillate near the domain boundary. For Stochastic eXp-concave Optimization (SXO), computational cost is also a challenge. Deploying ONS with online-to-batch conversion for SXO requires $T = \tilde{O}(d/ε)$ rounds to achieve an excess risk of $ε$, and thereby necessitates an $\tilde{O}(d^{ω+1}/ε)$ runtime. A COLT'13 open problem posed by Koren [2013] asks for an SXO algorithm with runtime less than $\tilde{O}(d^{ω+1}/ε)$. This paper proposes a simple variant of ONS, LightONS, which reduces the total runtime to $O(d^2 T + d^ω\sqrt{T \log T})$ while preserving the optimal $O(d \log T)$ regret. LightONS implies an SXO method with runtime $\tilde{O}(d^3/ε)$, thereby answering the open problem. Importantly, LightONS preserves the elegant structure of ONS by leveraging domain-conversion techniques from parameter-free online learning to introduce a hysteresis mechanism that delays expensive Mahalanobis projections until necessary. This design enables LightONS to serve as an efficient plug-in replacement of ONS in broader scenarios, even beyond regret minimization, including gradient-norm adaptive regret, parametric stochastic bandits, and memory-efficient online learning.
Re$^{\text{2}}$MaP: Macro Placement by Recursively Prototyping and Packing Tree-based Relocating
Nov 11, 2025This work introduces the Re$^{\text{2}}$MaP method, which generates expert-quality macro placements through recursively prototyping and packing tree-based relocating. We first perform multi-level macro grouping and PPA-aware cell clustering to produce a unified connection matrix that captures both wirelength and dataflow among macros and clusters. Next, we use DREAMPlace to build a mixed-size placement prototype and obtain reference positions for each macro and cluster. Based on this prototype, we introduce ABPlace, an angle-based analytical method that optimizes macro positions on an ellipse to distribute macros uniformly near chip periphery, while optimizing wirelength and dataflow. A packing tree-based relocating procedure is then designed to jointly adjust the locations of macro groups and the macros within each group, by optimizing an expertise-inspired cost function that captures various design constraints through evolutionary search. Re$^{\text{2}}$MaP repeats the above process: Only a subset of macro groups are positioned in each iteration, and the remaining macros are deferred to the next iteration to improve the prototype's accuracy. Using a well-established backend flow with sufficient timing optimizations, Re$^{\text{2}}$MaP achieves up to 22.22% (average 10.26%) improvement in worst negative slack (WNS) and up to 97.91% (average 33.97%) improvement in total negative slack (TNS) compared to the state-of-the-art academic placer Hier-RTLMP. It also ranks higher on WNS, TNS, power, design rule check (DRC) violations, and runtime than the conference version ReMaP, across seven tested cases. Our code is available at https://github.com/lamda-bbo/Re2MaP.
Optimistic Online-to-Batch Conversions for Accelerated Convergence and Universality
Nov 10, 2025
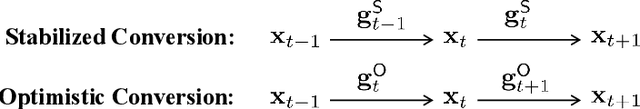
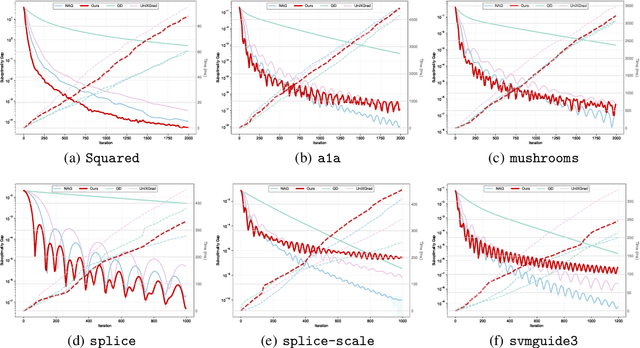
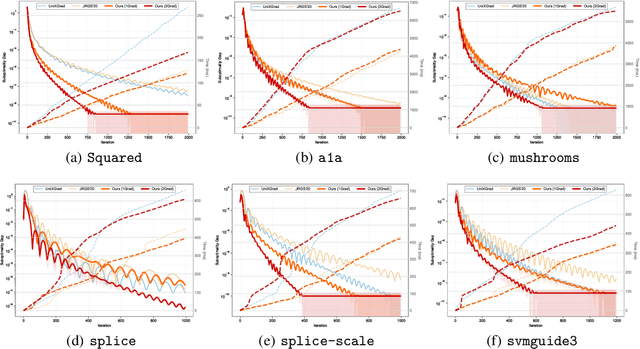
In this work, we study offline convex optimization with smooth objectives, where the classical Nesterov's Accelerated Gradient (NAG) method achieves the optimal accelerated convergence. Extensive research has aimed to understand NAG from various perspectives, and a recent line of work approaches this from the viewpoint of online learning and online-to-batch conversion, emphasizing the role of optimistic online algorithms for acceleration. In this work, we contribute to this perspective by proposing novel optimistic online-to-batch conversions that incorporate optimism theoretically into the analysis, thereby significantly simplifying the online algorithm design while preserving the optimal convergence rates. Specifically, we demonstrate the effectiveness of our conversions through the following results: (i) when combined with simple online gradient descent, our optimistic conversion achieves the optimal accelerated convergence; (ii) our conversion also applies to strongly convex objectives, and by leveraging both optimistic online-to-batch conversion and optimistic online algorithms, we achieve the optimal accelerated convergence rate for strongly convex and smooth objectives, for the first time through the lens of online-to-batch conversion; (iii) our optimistic conversion can achieve universality to smoothness -- applicable to both smooth and non-smooth objectives without requiring knowledge of the smoothness coefficient -- and remains efficient as non-universal methods by using only one gradient query in each iteration. Finally, we highlight the effectiveness of our optimistic online-to-batch conversions by a precise correspondence with NAG.
TreeLoRA: Efficient Continual Learning via Layer-Wise LoRAs Guided by a Hierarchical Gradient-Similarity Tree
Jun 12, 2025Many real-world applications collect data in a streaming environment, where learning tasks are encountered sequentially. This necessitates continual learning (CL) to update models online, enabling adaptation to new tasks while preserving past knowledge to prevent catastrophic forgetting. Nowadays, with the flourish of large pre-trained models (LPMs), efficiency has become increasingly critical for CL, due to their substantial computational demands and growing parameter sizes. In this paper, we introduce TreeLoRA (K-D Tree of Low-Rank Adapters), a novel approach that constructs layer-wise adapters by leveraging hierarchical gradient similarity to enable efficient CL, particularly for LPMs. To reduce the computational burden of task similarity estimation, we employ bandit techniques to develop an algorithm based on lower confidence bounds to efficiently explore the task structure. Furthermore, we use sparse gradient updates to facilitate parameter optimization, making the approach better suited for LPMs. Theoretical analysis is provided to justify the rationale behind our approach, and experiments on both vision transformers (ViTs) and large language models (LLMs) demonstrate the effectiveness and efficiency of our approach across various domains, including vision and natural language processing tasks.