 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient RLHF Pipeline: A Unified View from Contextual Bandits
Feb 11, 2025Reinforcement Learning from Human Feedback (RLHF) is a widely used approach for aligning Large Language Models (LLMs) with human preferences. While recent advancements have provided valuable insights into various stages and settings of RLHF, a comprehensive theoretical understanding of the entire RLHF pipeline remains lacking. Towards this end, we propose a unified framework for the RLHF pipeline from the view of contextual bandits and provide provable efficiency guarantees. In particular, we decompose the RLHF process into two distinct stages: (post-)training and deployment, exploring both passive and active data collection strategies during the training phase. By employing the Bradley-Terry preference model with a linearly parameterized reward function, we reformulate RLHF as a contextual preference bandit problem. We then develop novel algorithms for each stage, demonstrating significant improvements over existing approaches in both statistical and computational efficiency. Finally, we apply our method to train and deploy Llama-3-8B-Instruct on the Ultrafeedback-binarized dataset, and empirical results confirm the effectiveness of our approach.
Near-Optimal Dynamic Regret for Adversarial Linear Mixture MDPs
Nov 05, 2024
We study episodic linear mixture MDPs with the unknown transition and adversarial rewards under full-information feedback, employing dynamic regret as the performance measure. We start with in-depth analyses of the strengths and limitations of the two most popular methods: occupancy-measure-based and policy-based methods. We observe that while the occupancy-measure-based method is effective in addressing non-stationary environments, it encounters difficulties with the unknown transition. In contrast, the policy-based method can deal with the unknown transition effectively but faces challenges in handling non-stationary environments. Building on this, we propose a novel algorithm that combines the benefits of both methods. Specifically, it employs (i) an occupancy-measure-based global optimization with a two-layer structure to handle non-stationary environments; and (ii) a policy-based variance-aware value-targeted regression to tackle the unknown transition. We bridge these two parts by a novel conversion. Our algorithm enjoys an $\widetilde{\mathcal{O}}(d \sqrt{H^3 K} + \sqrt{HK(H + \bar{P}_K)})$ dynamic regret, where $d$ is the feature dimension, $H$ is the episode length, $K$ is the number of episodes, $\bar{P}_K$ is the non-stationarity measure. We show it is minimax optimal up to logarithmic factors by establishing a matching lower bound. To the best of our knowledge, this is the first work that achieves near-optimal dynamic regret for adversarial linear mixture MDPs with the unknown transition without prior knowledge of the non-stationarity measure.
Improved Algorithm for Adversarial Linear Mixture MDPs with Bandit Feedback and Unknown Transition
Mar 07, 2024We study reinforcement learning with linear function approximation, unknown transition, and adversarial losses in the bandit feedback setting. Specifically, we focus on linear mixture MDPs whose transition kernel is a linear mixture model. We propose a new algorithm that attains an $\widetilde{O}(d\sqrt{HS^3K} + \sqrt{HSAK})$ regret with high probability, where $d$ is the dimension of feature mappings, $S$ is the size of state space, $A$ is the size of action space, $H$ is the episode length and $K$ is the number of episodes. Our result strictly improves the previous best-known $\widetilde{O}(dS^2 \sqrt{K} + \sqrt{HSAK})$ result in Zhao et al. (2023a) since $H \leq S$ holds by the layered MDP structure. Our advancements are primarily attributed to (i) a new least square estimator for the transition parameter that leverages the visit information of all states, as opposed to only one state in prior work, and (ii) a new self-normalized concentration tailored specifically to handle non-independent noises, originally proposed in the dynamic assortment area and firstly applied in reinforcement learning to handle correlations between different states.
Dynamic Regret of Online Markov Decision Processes
Aug 26, 2022
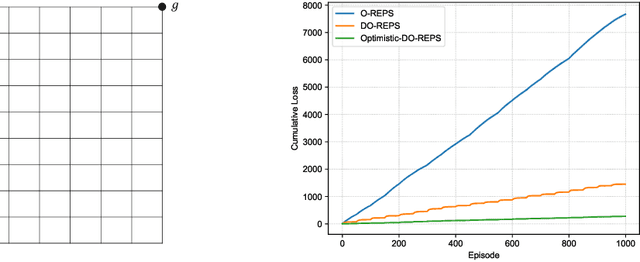
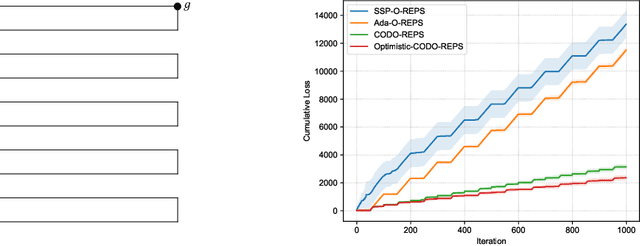
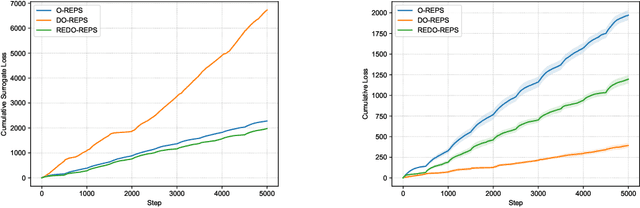
We investigate online Markov Decision Processes (MDPs) with adversarially changing loss functions and known transitions. We choose dynamic regret as the performance measure, defined as the performance difference between the learner and any sequence of feasible changing policies. The measure is strictly stronger than the standard static regret that benchmarks the learner's performance with a fixed compared policy. We consider three foundational models of online MDPs, including episodic loop-free Stochastic Shortest Path (SSP), episodic SSP, and infinite-horizon MDPs. For these three models, we propose novel online ensemble algorithms and establish their dynamic regret guarantees respectively, in which the results for episodic (loop-free) SSP are provably minimax optimal in terms of time horizon and certain non-stationarity measure. Furthermore, when the online environments encountered by the learner are predictable, we design improved algorithms and achieve better dynamic regret bounds for the episodic (loop-free) SSP; and moreover, we demonstrate impossibility results for the infinite-horizon MDPs.