 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Investigation on Inductive Bias of Isolation Forest
May 19, 2025Isolation Forest (iForest) stands out as a widely-used unsupervised anomaly detector valued for its exceptional runtime efficiency and performance on large-scale tasks. Despite its widespread adoption, a theoretical foundation explaining iForest's success remains unclear. This paper theoretically investigates the conditions and extent of iForest's effectiveness by analyzing its inductive bias through the formulation of depth functions and growth processes. Since directly analyzing the depth function proves intractable due to iForest's random splitting mechanism, we model the growth process of iForest as a random walk, enabling us to derive the expected depth function using transition probabilities. Our case studies reveal key inductive biases: iForest exhibits lower sensitivity to central anomalies while demonstrating greater parameter adaptability compared to $k$-Nearest Neighbor anomaly detectors. Our study provides theoretical understanding of the effectiveness of iForest and establishes a foundation for further theoretical exploration.
The Role of Depth, Width, and Tree Size in Expressiveness of Deep Forest
Jul 06, 2024



Random forests are classical ensemble algorithms that construct multiple randomized decision trees and aggregate their predictions using naive averaging. \citet{zhou2019deep} further propose a deep forest algorithm with multi-layer forests, which outperforms random forests in various tasks. The performance of deep forests is related to three hyperparameters in practice: depth, width, and tree size, but little has been known about its theoretical explanation. This work provides the first upper and lower bounds on the approximation complexity of deep forests concerning the three hyperparameters. Our results confirm the distinctive role of depth, which can exponentially enhance the expressiveness of deep forests compared with width and tree size. Experiments confirm the theoretical findings.
Beimingwu: A Learnware Dock System
Jan 24, 2024

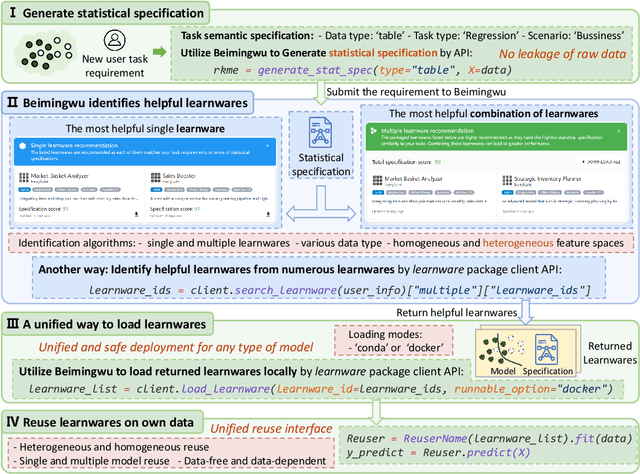

The learnware paradigm proposed by Zhou [2016] aims to enable users to reuse numerous existing well-trained models instead of building machine learning models from scratch, with the hope of solving new user tasks even beyond models' original purposes. In this paradigm, developers worldwide can submit their high-performing models spontaneously to the learnware dock system (formerly known as learnware market) without revealing their training data. Once the dock system accepts the model, it assigns a specification and accommodates the model. This specification allows the model to be adequately identified and assembled to reuse according to future users' needs, even if they have no prior knowledge of the model. This paradigm greatly differs from the current big model direction and it is expected that a learnware dock system housing millions or more high-performing models could offer excellent capabilities for both planned tasks where big models are applicable; and unplanned, specialized, data-sensitive scenarios where big models are not present or applicable. This paper describes Beimingwu, the first open-source learnware dock system providing foundational support for future research of learnware paradigm.The system significantly streamlines the model development for new user tasks, thanks to its integrated architecture and engine design, extensive engineering implementations and optimizations, and the integration of various algorithms for learnware identification and reuse. Notably, this is possible even for users with limited data and minimal expertise in machine learning, without compromising the raw data's security. Beimingwu supports the entire process of learnware paradigm. The system lays the foundation for future research in learnware-related algorithms and systems, and prepares the ground for hosting a vast array of learnwares and establishing a learnware ecosystem.