 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Learnability of Offline Model-Based Optimization: A Ranking Perspective
Mar 04, 2026Offline model-based optimization (MBO) seeks to discover high-performing designs using only a fixed dataset of past evaluations. Most existing methods rely on learning a surrogate model via regression and implicitly assume that good predictive accuracy leads to good optimization performance. In this work, we challenge this assumption and study offline MBO from a learnability perspective. We argue that offline optimization is fundamentally a problem of ranking high-quality designs rather than accurate value prediction. Specifically, we introduce an optimization-oriented risk based on ranking between near-optimal and suboptimal designs, and develop a unified theoretical framework that connects surrogate learning to final optimization. We prove the theoretical advantages of ranking over regression, and identify distributional mismatch between the training data and near-optimal designs as the dominant error. Inspired by this, we design a distribution-aware ranking method to reduce this mismatch. Empirical results across various tasks show that our approach outperforms twenty existing methods, validating our theoretical findings. Additionally, both theoretical and empirical results reveal intrinsic limitations in offline MBO, showing a regime in which no offline method can avoid over-optimistic extrapolation.
Breaking the Prototype Bias Loop: Confidence-Aware Federated Contrastive Learning for Highly Imbalanced Clients
Mar 03, 2026Local class imbalance and data heterogeneity across clients often trap prototype-based federated contrastive learning in a prototype bias loop: biased local prototypes induced by imbalanced data are aggregated into biased global prototypes, which are repeatedly reused as contrastive anchors, accumulating errors across communication rounds. To break this loop, we propose Confidence-Aware Federated Contrastive Learning (CAFedCL), a novel framework that improves the prototype aggregation mechanism and strengthens the contrastive alignment guided by prototypes. CAFedCL employs a confidence-aware aggregation mechanism that leverages predictive uncertainty to downweight high-variance local prototypes. In addition, generative augmentation for minority classes and geometric consistency regularization are integrated to stabilize the structure between classes. From a theoretical perspective, we provide an expectation-based analysis showing that our aggregation reduces estimation variance, thereby bounding global prototype drift and ensuring convergence. Extensive experiments under varying levels of class imbalance and data heterogeneity demonstrate that CAFedCL consistently outperforms representative federated baselines in both accuracy and client fairness.
Enhance and Reuse: A Dual-Mechanism Approach to Boost Deep Forest for Label Distribution Learning
Feb 06, 2026Label distribution learning (LDL) requires the learner to predict the degree of correlation between each sample and each label. To achieve this, a crucial task during learning is to leverage the correlation among labels. Deep Forest (DF) is a deep learning framework based on tree ensembles, whose training phase does not rely on backpropagation. DF performs in-model feature transform using the prediction of each layer and achieves competitive performance on many tasks. However, its exploration in the field of LDL is still in its infancy. The few existing methods that apply DF to the field of LDL do not have effective ways to utilize the correlation among labels. Therefore, we propose a method named Enhanced and Reused Feature Deep Forest (ERDF). It mainly contains two mechanisms: feature enhancement exploiting label correlation and measure-aware feature reuse. The first one is to utilize the correlation among labels to enhance the original features, enabling the samples to acquire more comprehensive information for the task of LDL. The second one performs a reuse operation on the features of samples that perform worse than the previous layer on the validation set, in order to ensure the stability of the training process. This kind of Enhance-Reuse pattern not only enables samples to enrich their features but also validates the effectiveness of their new features and conducts a reuse process to prevent the noise from spreading further. Experiments show that our method outperforms other comparison algorithms on six evaluation metrics.
Theoretical Investigation on Inductive Bias of Isolation Forest
May 19, 2025Isolation Forest (iForest) stands out as a widely-used unsupervised anomaly detector valued for its exceptional runtime efficiency and performance on large-scale tasks. Despite its widespread adoption, a theoretical foundation explaining iForest's success remains unclear. This paper theoretically investigates the conditions and extent of iForest's effectiveness by analyzing its inductive bias through the formulation of depth functions and growth processes. Since directly analyzing the depth function proves intractable due to iForest's random splitting mechanism, we model the growth process of iForest as a random walk, enabling us to derive the expected depth function using transition probabilities. Our case studies reveal key inductive biases: iForest exhibits lower sensitivity to central anomalies while demonstrating greater parameter adaptability compared to $k$-Nearest Neighbor anomaly detectors. Our study provides theoretical understanding of the effectiveness of iForest and establishes a foundation for further theoretical exploration.
Compressing Model with Few Class-Imbalance Samples: An Out-of-Distribution Expedition
Feb 09, 2025



In recent years, as a compromise between privacy and performance, few-sample model compression has been widely adopted to deal with limited data resulting from privacy and security concerns. However, when the number of available samples is extremely limited, class imbalance becomes a common and tricky problem. Achieving an equal number of samples across all classes is often costly and impractical in real-world applications, and previous studies on few-sample model compression have mostly ignored this significant issue. Our experiments comprehensively demonstrate that class imbalance negatively affects the overall performance of few-sample model compression methods. To address this problem, we propose a novel and adaptive framework named OOD-Enhanced Few-Sample Model Compression (OE-FSMC). This framework integrates easily accessible out-of-distribution (OOD) data into both the compression and fine-tuning processes, effectively rebalancing the training distribution. We also incorporate a joint distillation loss and a regularization term to reduce the risk of the model overfitting to the OOD data. Extensive experiments on multiple benchmark datasets show that our framework can be seamlessly incorporated into existing few-sample model compression methods, effectively mitigating the accuracy degradation caused by class imbalance.
Improving Multi-Label Contrastive Learning by Leveraging Label Distribution
Jan 31, 2025



In multi-label learning, leveraging contrastive learning to learn better representations faces a key challenge: selecting positive and negative samples and effectively utilizing label information. Previous studies selected positive and negative samples based on the overlap between labels and used them for label-wise loss balancing. However, these methods suffer from a complex selection process and fail to account for the varying importance of different labels. To address these problems, we propose a novel method that improves multi-label contrastive learning through label distribution. Specifically, when selecting positive and negative samples, we only need to consider whether there is an intersection between labels. To model the relationships between labels, we introduce two methods to recover label distributions from logical labels, based on Radial Basis Function (RBF) and contrastive loss, respectively. We evaluate our method on nine widely used multi-label datasets, including image and vector datasets. The results demonstrate that our method outperforms state-of-the-art methods in six evaluation metrics.
Offline Model-Based Optimization by Learning to Rank
Oct 15, 2024


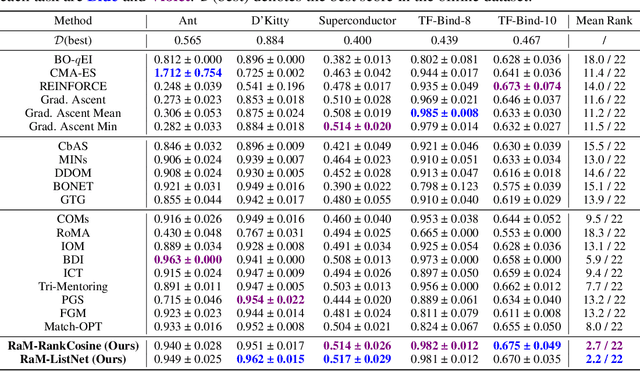
Offline model-based optimization (MBO) aims to identify a design that maximizes a black-box function using only a fixed, pre-collected dataset of designs and their corresponding scores. A common approach in offline MBO is to train a regression-based surrogate model by minimizing mean squared error (MSE) and then find the best design within this surrogate model by different optimizers (e.g., gradient ascent). However, a critical challenge is the risk of out-of-distribution errors, i.e., the surrogate model may typically overestimate the scores and mislead the optimizers into suboptimal regions. Prior works have attempted to address this issue in various ways, such as using regularization techniques and ensemble learning to enhance the robustness of the model, but it still remains. In this paper, we argue that regression models trained with MSE are not well-aligned with the primary goal of offline MBO, which is to select promising designs rather than to predict their scores precisely. Notably, if a surrogate model can maintain the order of candidate designs based on their relative score relationships, it can produce the best designs even without precise predictions. To validate it, we conduct experiments to compare the relationship between the quality of the final designs and MSE, finding that the correlation is really very weak. In contrast, a metric that measures order-maintaining quality shows a significantly stronger correlation. Based on this observation, we propose learning a ranking-based model that leverages learning to rank techniques to prioritize promising designs based on their relative scores. We show that the generalization error on ranking loss can be well bounded. Empirical results across diverse tasks demonstrate the superior performance of our proposed ranking-based models than twenty existing methods.
Mask-Encoded Sparsification: Mitigating Biased Gradients in Communication-Efficient Split Learning
Aug 25, 2024This paper introduces a novel framework designed to achieve a high compression ratio in Split Learning (SL) scenarios where resource-constrained devices are involved in large-scale model training. Our investigations demonstrate that compressing feature maps within SL leads to biased gradients that can negatively impact the convergence rates and diminish the generalization capabilities of the resulting models. Our theoretical analysis provides insights into how compression errors critically hinder SL performance, which previous methodologies underestimate. To address these challenges, we employ a narrow bit-width encoded mask to compensate for the sparsification error without increasing the order of time complexity. Supported by rigorous theoretical analysis, our framework significantly reduces compression errors and accelerates the convergence. Extensive experiments also verify that our method outperforms existing solutions regarding training efficiency and communication complexity.
The Role of Depth, Width, and Tree Size in Expressiveness of Deep Forest
Jul 06, 2024



Random forests are classical ensemble algorithms that construct multiple randomized decision trees and aggregate their predictions using naive averaging. \citet{zhou2019deep} further propose a deep forest algorithm with multi-layer forests, which outperforms random forests in various tasks. The performance of deep forests is related to three hyperparameters in practice: depth, width, and tree size, but little has been known about its theoretical explanation. This work provides the first upper and lower bounds on the approximation complexity of deep forests concerning the three hyperparameters. Our results confirm the distinctive role of depth, which can exponentially enhance the expressiveness of deep forests compared with width and tree size. Experiments confirm the theoretical findings.
Confidence-aware Contrastive Learning for Selective Classification
Jun 07, 2024



Selective classification enables models to make predictions only when they are sufficiently confident, aiming to enhance safety and reliability, which is important in high-stakes scenarios. Previous methods mainly use deep neural networks and focus on modifying the architecture of classification layers to enable the model to estimate the confidence of its prediction. This work provides a generalization bound for selective classification, disclosing that optimizing feature layers helps improve the performance of selective classification. Inspired by this theory, we propose to explicitly improve the selective classification model at the feature level for the first time, leading to a novel Confidence-aware Contrastive Learning method for Selective Classification, CCL-SC, which similarizes the features of homogeneous instances and differentiates the features of heterogeneous instances, with the strength controlled by the model's confidence. The experimental results on typical datasets, i.e., CIFAR-10, CIFAR-100, CelebA, and ImageNet, show that CCL-SC achieves significantly lower selective risk than state-of-the-art methods, across almost all coverage degrees. Moreover, it can be combined with existing methods to bring further improvement.