 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViDove: A Translation Agent System with Multimodal Context and Memory-Augmented Reasoning
Jul 09, 2025LLM-based translation agents have achieved highly human-like translation results and are capable of handling longer and more complex contexts with greater efficiency. However, they are typically limited to text-only inputs. In this paper, we introduce ViDove, a translation agent system designed for multimodal input. Inspired by the workflow of human translators, ViDove leverages visual and contextual background information to enhance the translation process. Additionally, we integrate a multimodal memory system and long-short term memory modules enriched with domain-specific knowledge, enabling the agent to perform more accurately and adaptively in real-world scenarios. As a result, ViDove achieves significantly higher translation quality in both subtitle generation and general translation tasks, with a 28% improvement in BLEU scores and a 15% improvement in SubER compared to previous state-of-the-art baselines. Moreover, we introduce DoveBench, a new benchmark for long-form automatic video subtitling and translation, featuring 17 hours of high-quality, human-annotated data. Our code is available here: https://github.com/pigeonai-org/ViDove
Towards Universal Offline Black-Box Optimization via Learning Language Model Embeddings
Jun 08, 2025The pursuit of universal black-box optimization (BBO) algorithms is a longstanding goal. However, unlike domains such as language or vision, where scaling structured data has driven generalization, progress in offline BBO remains hindered by the lack of unified representations for heterogeneous numerical spaces. Thus, existing offline BBO approaches are constrained to single-task and fixed-dimensional settings, failing to achieve cross-domain universal optimization. Recent advances in language models (LMs) offer a promising path forward: their embeddings capture latent relationships in a unifying way, enabling universal optimization across different data types possible. In this paper, we discuss multiple potential approaches, including an end-to-end learning framework in the form of next-token prediction, as well as prioritizing the learning of latent spaces with strong representational capabilities. To validate the effectiveness of these methods, we collect offline BBO tasks and data from open-source academic works for training. Experiments demonstrate the universality and effectiveness of our proposed methods. Our findings suggest that unifying language model priors and learning string embedding space can overcome traditional barriers in universal BBO, paving the way for general-purpose BBO algorithms. The code is provided at https://github.com/lamda-bbo/universal-offline-bbo.
Offline Model-Based Optimization by Learning to Rank
Oct 15, 2024


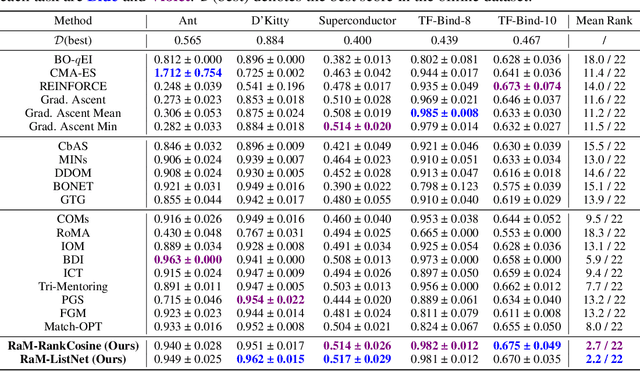
Offline model-based optimization (MBO) aims to identify a design that maximizes a black-box function using only a fixed, pre-collected dataset of designs and their corresponding scores. A common approach in offline MBO is to train a regression-based surrogate model by minimizing mean squared error (MSE) and then find the best design within this surrogate model by different optimizers (e.g., gradient ascent). However, a critical challenge is the risk of out-of-distribution errors, i.e., the surrogate model may typically overestimate the scores and mislead the optimizers into suboptimal regions. Prior works have attempted to address this issue in various ways, such as using regularization techniques and ensemble learning to enhance the robustness of the model, but it still remains. In this paper, we argue that regression models trained with MSE are not well-aligned with the primary goal of offline MBO, which is to select promising designs rather than to predict their scores precisely. Notably, if a surrogate model can maintain the order of candidate designs based on their relative score relationships, it can produce the best designs even without precise predictions. To validate it, we conduct experiments to compare the relationship between the quality of the final designs and MSE, finding that the correlation is really very weak. In contrast, a metric that measures order-maintaining quality shows a significantly stronger correlation. Based on this observation, we propose learning a ranking-based model that leverages learning to rank techniques to prioritize promising designs based on their relative scores. We show that the generalization error on ranking loss can be well bounded. Empirical results across diverse tasks demonstrate the superior performance of our proposed ranking-based models than twenty existing methods.
Packing: Towards 2x NLP BERT Acceleration
Jun 29, 2021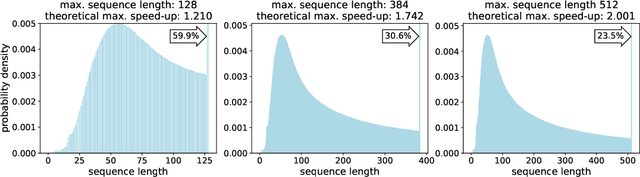
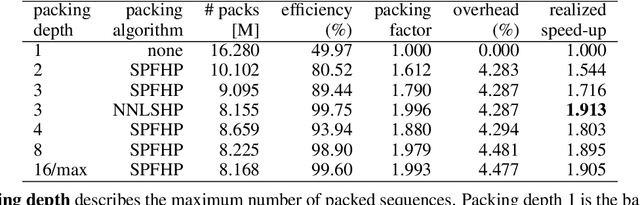


We find that at sequence length 512 padding tokens represent in excess of 50% of the Wikipedia dataset used for pretraining BERT (Bidirectional Encoder Representations from Transformers). Therefore by removing all padding we achieve a 2x speed-up in terms of sequences/sec. To exploit this characteristic of the dataset, we develop and contrast two deterministic packing algorithms. Both algorithms rely on the assumption that sequences are interchangeable and therefore packing can be performed on the histogram of sequence lengths, rather than per sample. This transformation of the problem leads to algorithms which are fast and have linear complexity in dataset size. The shortest-pack-first histogram-packing (SPFHP) algorithm determines the packing order for the Wikipedia dataset of over 16M sequences in 0.02 seconds. The non-negative least-squares histogram-packing (NNLSHP) algorithm converges in 28.4 seconds but produces solutions which are more depth efficient, managing to get near optimal packing by combining a maximum of 3 sequences in one sample. Using the dataset with multiple sequences per sample requires additional masking in the attention layer and a modification of the MLM loss function. We demonstrate that both of these changes are straightforward to implement and have relatively little impact on the achievable performance gain on modern hardware. Finally, we pretrain BERT-Large using the packed dataset, demonstrating no loss of convergence and the desired 2x speed-up.