 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Model-Based Optimization by Learning to Rank
Oct 15, 2024


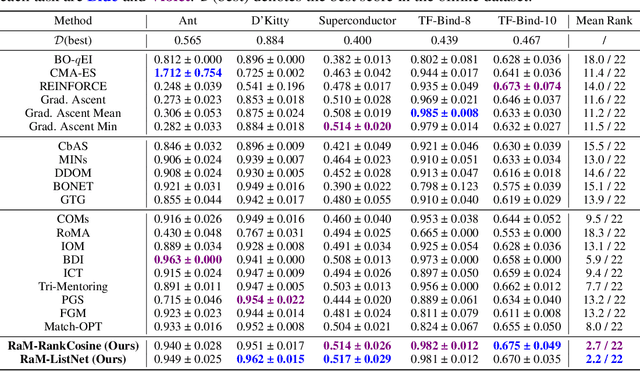
Offline model-based optimization (MBO) aims to identify a design that maximizes a black-box function using only a fixed, pre-collected dataset of designs and their corresponding scores. A common approach in offline MBO is to train a regression-based surrogate model by minimizing mean squared error (MSE) and then find the best design within this surrogate model by different optimizers (e.g., gradient ascent). However, a critical challenge is the risk of out-of-distribution errors, i.e., the surrogate model may typically overestimate the scores and mislead the optimizers into suboptimal regions. Prior works have attempted to address this issue in various ways, such as using regularization techniques and ensemble learning to enhance the robustness of the model, but it still remains. In this paper, we argue that regression models trained with MSE are not well-aligned with the primary goal of offline MBO, which is to select promising designs rather than to predict their scores precisely. Notably, if a surrogate model can maintain the order of candidate designs based on their relative score relationships, it can produce the best designs even without precise predictions. To validate it, we conduct experiments to compare the relationship between the quality of the final designs and MSE, finding that the correlation is really very weak. In contrast, a metric that measures order-maintaining quality shows a significantly stronger correlation. Based on this observation, we propose learning a ranking-based model that leverages learning to rank techniques to prioritize promising designs based on their relative scores. We show that the generalization error on ranking loss can be well bounded. Empirical results across diverse tasks demonstrate the superior performance of our proposed ranking-based models than twenty existing methods.
Neural Solver Selection for Combinatorial Optimization
Oct 13, 2024



Machine learning has increasingly been employed to solve NP-hard combinatorial optimization problems, resulting in the emergence of neural solvers that demonstrate remarkable performance, even with minimal domain-specific knowledge. To date, the community has created numerous open-source neural solvers with distinct motivations and inductive biases. While considerable efforts are devoted to designing powerful single solvers, our findings reveal that existing solvers typically demonstrate complementary performance across different problem instances. This suggests that significant improvements could be achieved through effective coordination of neural solvers at the instance level. In this work, we propose the first general framework to coordinate the neural solvers, which involves feature extraction, selection model, and selection strategy, aiming to allocate each instance to the most suitable solvers. To instantiate, we collect several typical neural solvers with state-of-the-art performance as alternatives, and explore various methods for each component of the framework. We evaluated our framework on two extensively studied combinatorial optimization problems, Traveling Salesman Problem (TSP) and Capacitated Vehicle Routing Problem (CVRP). Experimental results show that the proposed framework can effectively distribute instances and the resulting composite solver can achieve significantly better performance (e.g., reduce the optimality gap by 0.88\% on TSPLIB and 0.71\% on CVRPLIB) than the best individual neural solver with little extra time cost.
Detection-Rate-Emphasized Multi-objective Evolutionary Feature Selection for Network Intrusion Detection
Jun 13, 2024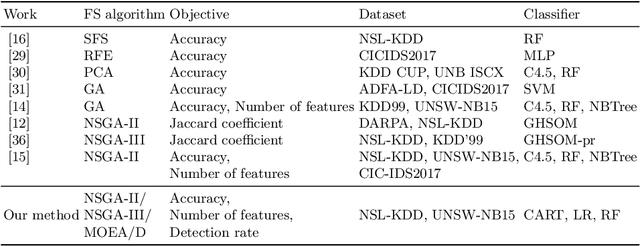


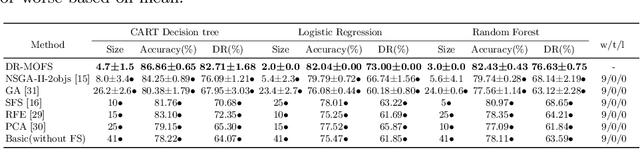
Network intrusion detection is one of the most important issues in the field of cyber security, and various machine learning techniques have been applied to build intrusion detection systems. However, since the number of features to describe the network connections is often large, where some features are redundant or noisy, feature selection is necessary in such scenarios, which can both improve the efficiency and accuracy. Recently, some researchers focus on using multi-objective evolutionary algorithms (MOEAs) to select features. But usually, they only consider the number of features and classification accuracy as the objectives, resulting in unsatisfactory performance on a critical metric, detection rate. This will lead to the missing of many real attacks and bring huge losses to the network system. In this paper, we propose DR-MOFS to model the feature selection problem in network intrusion detection as a three-objective optimization problem, where the number of features, accuracy and detection rate are optimized simultaneously, and use MOEAs to solve it. Experiments on two popular network intrusion detection datasets NSL-KDD and UNSW-NB15 show that in most cases the proposed method can outperform previous methods, i.e., lead to fewer features, higher accuracy and detection rate.
Confidence-aware Contrastive Learning for Selective Classification
Jun 07, 2024



Selective classification enables models to make predictions only when they are sufficiently confident, aiming to enhance safety and reliability, which is important in high-stakes scenarios. Previous methods mainly use deep neural networks and focus on modifying the architecture of classification layers to enable the model to estimate the confidence of its prediction. This work provides a generalization bound for selective classification, disclosing that optimizing feature layers helps improve the performance of selective classification. Inspired by this theory, we propose to explicitly improve the selective classification model at the feature level for the first time, leading to a novel Confidence-aware Contrastive Learning method for Selective Classification, CCL-SC, which similarizes the features of homogeneous instances and differentiates the features of heterogeneous instances, with the strength controlled by the model's confidence. The experimental results on typical datasets, i.e., CIFAR-10, CIFAR-100, CelebA, and ImageNet, show that CCL-SC achieves significantly lower selective risk than state-of-the-art methods, across almost all coverage degrees. Moreover, it can be combined with existing methods to bring further improvement.
Towards Generalizable Neural Solvers for Vehicle Routing Problems via Ensemble with Transferrable Local Policy
Aug 27, 2023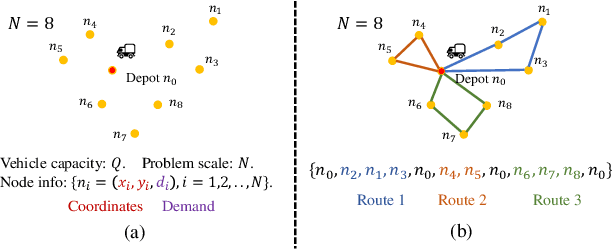
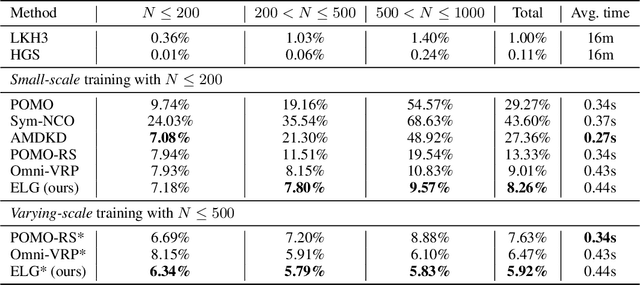
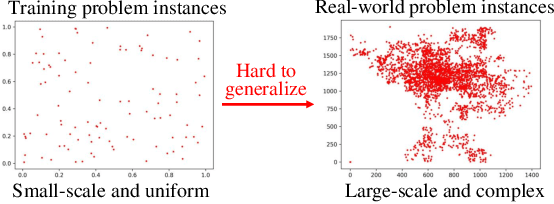

Machine learning has been adapted to help solve NP-hard combinatorial optimization problems. One prevalent way is learning to construct solutions by deep neural networks, which has been receiving more and more attention due to the high efficiency and less requirement for expert knowledge. However, many neural construction methods for Vehicle Routing Problems (VRPs) focus on synthetic problem instances with limited scales and specified node distributions, leading to poor performance on real-world problems which usually involve large scales together with complex and unknown node distributions. To make neural VRP solvers more practical in real-world scenarios, we design an auxiliary policy that learns from the local transferable topological features, named local policy, and integrate it with a typical constructive policy (which learns from the global information of VRP instances) to form an ensemble policy. With joint training, the aggregated policies perform cooperatively and complementarily to boost generalization. The experimental results on two well-known benchmarks, TSPLIB and CVRPLIB, of travelling salesman problem and capacitated VRP show that the ensemble policy consistently achieves better generalization than state-of-the-art construction methods and even works well on real-world problems with several thousand nodes.
Neural Network Pruning by Cooperative Coevolution
Apr 12, 2022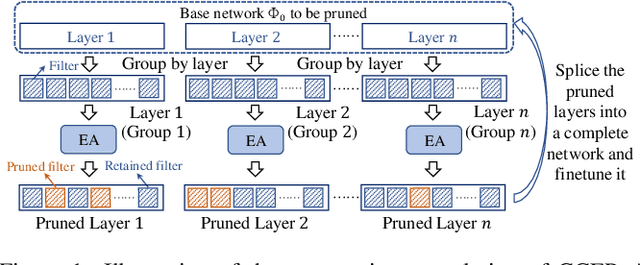
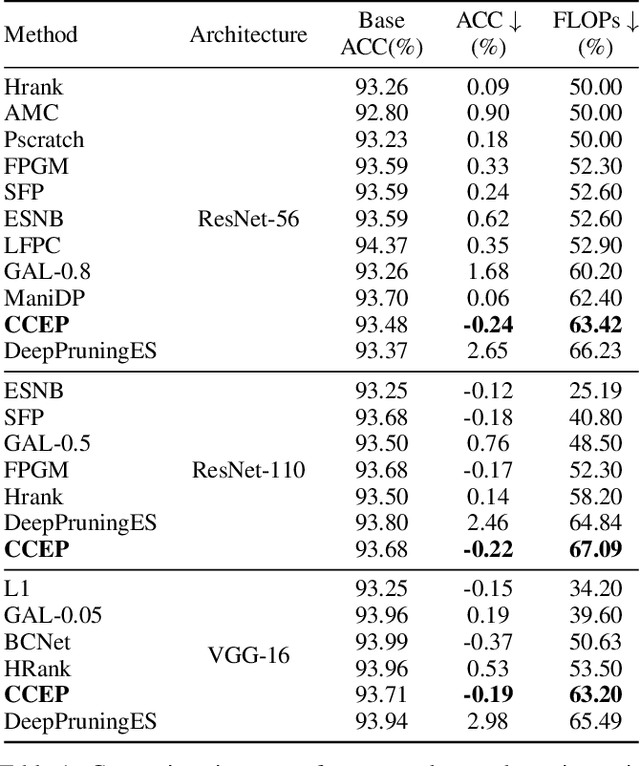

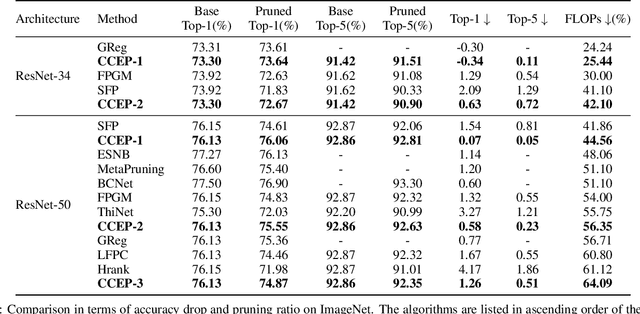
Neural network pruning is a popular model compression method which can significantly reduce the computing cost with negligible loss of accuracy. Recently, filters are often pruned directly by designing proper criteria or using auxiliary modules to measure their importance, which, however, requires expertise and trial-and-error. Due to the advantage of automation, pruning by evolutionary algorithms (EAs) has attracted much attention, but the performance is limited for deep neural networks as the search space can be quite large. In this paper, we propose a new filter pruning algorithm CCEP by cooperative coevolution, which prunes the filters in each layer by EAs separately. That is, CCEP reduces the pruning space by a divide-and-conquer strategy. The experiments show that CCEP can achieve a competitive performance with the state-of-the-art pruning methods, e.g., prune ResNet56 for $63.42\%$ FLOPs on CIFAR10 with $-0.24\%$ accuracy drop, and ResNet50 for $44.56\%$ FLOPs on ImageNet with $0.07\%$ accuracy drop.