 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Learnability of Offline Model-Based Optimization: A Ranking Perspective
Mar 04, 2026Offline model-based optimization (MBO) seeks to discover high-performing designs using only a fixed dataset of past evaluations. Most existing methods rely on learning a surrogate model via regression and implicitly assume that good predictive accuracy leads to good optimization performance. In this work, we challenge this assumption and study offline MBO from a learnability perspective. We argue that offline optimization is fundamentally a problem of ranking high-quality designs rather than accurate value prediction. Specifically, we introduce an optimization-oriented risk based on ranking between near-optimal and suboptimal designs, and develop a unified theoretical framework that connects surrogate learning to final optimization. We prove the theoretical advantages of ranking over regression, and identify distributional mismatch between the training data and near-optimal designs as the dominant error. Inspired by this, we design a distribution-aware ranking method to reduce this mismatch. Empirical results across various tasks show that our approach outperforms twenty existing methods, validating our theoretical findings. Additionally, both theoretical and empirical results reveal intrinsic limitations in offline MBO, showing a regime in which no offline method can avoid over-optimistic extrapolation.
Towards Universal Offline Black-Box Optimization via Learning Language Model Embeddings
Jun 08, 2025The pursuit of universal black-box optimization (BBO) algorithms is a longstanding goal. However, unlike domains such as language or vision, where scaling structured data has driven generalization, progress in offline BBO remains hindered by the lack of unified representations for heterogeneous numerical spaces. Thus, existing offline BBO approaches are constrained to single-task and fixed-dimensional settings, failing to achieve cross-domain universal optimization. Recent advances in language models (LMs) offer a promising path forward: their embeddings capture latent relationships in a unifying way, enabling universal optimization across different data types possible. In this paper, we discuss multiple potential approaches, including an end-to-end learning framework in the form of next-token prediction, as well as prioritizing the learning of latent spaces with strong representational capabilities. To validate the effectiveness of these methods, we collect offline BBO tasks and data from open-source academic works for training. Experiments demonstrate the universality and effectiveness of our proposed methods. Our findings suggest that unifying language model priors and learning string embedding space can overcome traditional barriers in universal BBO, paving the way for general-purpose BBO algorithms. The code is provided at https://github.com/lamda-bbo/universal-offline-bbo.
Offline Model-Based Optimization by Learning to Rank
Oct 15, 2024


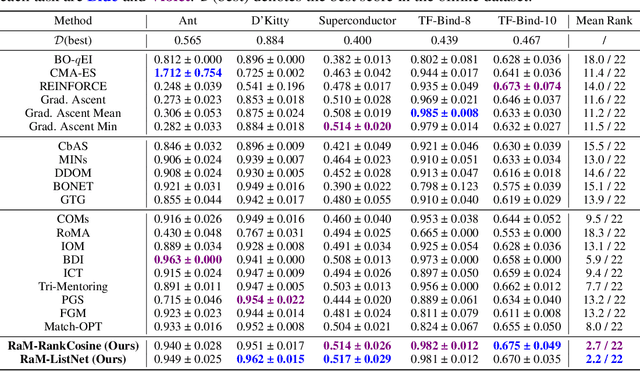
Offline model-based optimization (MBO) aims to identify a design that maximizes a black-box function using only a fixed, pre-collected dataset of designs and their corresponding scores. A common approach in offline MBO is to train a regression-based surrogate model by minimizing mean squared error (MSE) and then find the best design within this surrogate model by different optimizers (e.g., gradient ascent). However, a critical challenge is the risk of out-of-distribution errors, i.e., the surrogate model may typically overestimate the scores and mislead the optimizers into suboptimal regions. Prior works have attempted to address this issue in various ways, such as using regularization techniques and ensemble learning to enhance the robustness of the model, but it still remains. In this paper, we argue that regression models trained with MSE are not well-aligned with the primary goal of offline MBO, which is to select promising designs rather than to predict their scores precisely. Notably, if a surrogate model can maintain the order of candidate designs based on their relative score relationships, it can produce the best designs even without precise predictions. To validate it, we conduct experiments to compare the relationship between the quality of the final designs and MSE, finding that the correlation is really very weak. In contrast, a metric that measures order-maintaining quality shows a significantly stronger correlation. Based on this observation, we propose learning a ranking-based model that leverages learning to rank techniques to prioritize promising designs based on their relative scores. We show that the generalization error on ranking loss can be well bounded. Empirical results across diverse tasks demonstrate the superior performance of our proposed ranking-based models than twenty existing methods.
Offline Multi-Objective Optimization
Jun 06, 2024



Offline optimization aims to maximize a black-box objective function with a static dataset and has wide applications. In addition to the objective function being black-box and expensive to evaluate, numerous complex real-world problems entail optimizing multiple conflicting objectives, i.e., multi-objective optimization (MOO). Nevertheless, offline MOO has not progressed as much as offline single-objective optimization (SOO), mainly due to the lack of benchmarks like Design-Bench for SOO. To bridge this gap, we propose a first benchmark for offline MOO, covering a range of problems from synthetic to real-world tasks. This benchmark provides tasks, datasets, and open-source examples, which can serve as a foundation for method comparisons and advancements in offline MOO. Furthermore, we analyze how the current related methods can be adapted to offline MOO from four fundamental perspectives, including data, model architecture, learning algorithm, and search algorithm. Empirical results show improvements over the best value of the training set, demonstrating the effectiveness of offline MOO methods. As no particular method stands out significantly, there is still an open challenge in further enhancing the effectiveness of offline MOO. We finally discuss future challenges for offline MOO, with the hope of shedding some light on this emerging field. Our code is available at \url{https://github.com/lamda-bbo/offline-moo}.