 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Practical World Model-based Reinforcement Learning for Vision-Language-Action Models
Mar 21, 2026Vision-Language-Action (VLA) models show strong generalization for robotic control, but finetuning them with reinforcement learning (RL) is constrained by the high cost and safety risks of real-world interaction. Training VLA models in interactive world models avoids these issues but introduces several challenges, including pixel-level world modeling, multi-view consistency, and compounding errors under sparse rewards. Building on recent advances across large multimodal models and model-based RL, we propose VLA-MBPO, a practical framework to tackle these problems in VLA finetuning. Our approach has three key design choices: (i) adapting unified multimodal models (UMMs) for data-efficient world modeling; (ii) an interleaved view decoding mechanism to enforce multi-view consistency; and (iii) chunk-level branched rollout to mitigate error compounding. Theoretical analysis and experiments across simulation and real-world tasks demonstrate that VLA-MBPO significantly improves policy performance and sample efficiency, underscoring its robustness and scalability for real-world robotic deployment.
Speedup Patch: Learning a Plug-and-Play Policy to Accelerate Embodied Manipulation
Mar 21, 2026While current embodied policies exhibit remarkable manipulation skills, their execution remains unsatisfactorily slow as they inherit the tardy pacing of human demonstrations. Existing acceleration methods typically require policy retraining or costly online interactions, limiting their scalability for large-scale foundation models. In this paper, we propose Speedup Patch (SuP), a lightweight, policy-agnostic framework that enables plug-and-play acceleration using solely offline data. SuP introduces an external scheduler that adaptively downsamples action chunks provided by embodied policies to eliminate redundancies. Specifically, we formalize the optimization of our scheduler as a Constrained Markov Decision Process (CMDP) aimed at maximizing efficiency without compromising task performance. Since direct success evaluation is infeasible in offline settings, SuP introduces World Model based state deviation as a surrogate metric to enforce safety constraints. By leveraging a learned world model as a virtual evaluator to predict counterfactual trajectories, the scheduler can be optimized via offline reinforcement learning. Empirical results on simulation benchmarks (Libero, Bigym) and real-world tasks validate that SuP achieves an overall 1.8x execution speedup for diverse policies while maintaining their original success rates.
Implicit Non-Causal Factors are Out via Dataset Splitting for Domain Generalization Object Detection
Jan 27, 2026Open world object detection faces a significant challenge in domain-invariant representation, i.e., implicit non-causal factors. Most domain generalization (DG) methods based on domain adversarial learning (DAL) pay much attention to learn domain-invariant information, but often overlook the potential non-causal factors. We unveil two critical causes: 1) The domain discriminator-based DAL method is subject to the extremely sparse domain label, i.e., assigning only one domain label to each dataset, thus can only associate explicit non-causal factor, which is incredibly limited. 2) The non-causal factors, induced by unidentified data bias, are excessively implicit and cannot be solely discerned by conventional DAL paradigm. Based on these key findings, inspired by the Granular-Ball perspective, we propose an improved DAL method, i.e., GB-DAL. The proposed GB-DAL utilizes Prototype-based Granular Ball Splitting (PGBS) module to generate more dense domains from limited datasets, akin to more fine-grained granular balls, indicating more potential non-causal factors. Inspired by adversarial perturbations akin to non-causal factors, we propose a Simulated Non-causal Factors (SNF) module as a means of data augmentation to reduce the implicitness of non-causal factors, and facilitate the training of GB-DAL. Comparative experiments on numerous benchmarks demonstrate that our method achieves better generalization performance in novel circumstances.
Optimization of Private Semantic Communication Performance: An Uncooperative Covert Communication Method
Aug 11, 2025In this paper, a novel covert semantic communication framework is investigated. Within this framework, a server extracts and transmits the semantic information, i.e., the meaning of image data, to a user over several time slots. An attacker seeks to detect and eavesdrop the semantic transmission to acquire details of the original image. To avoid data meaning being eavesdropped by an attacker, a friendly jammer is deployed to transmit jamming signals to interfere the attacker so as to hide the transmitted semantic information. Meanwhile, the server will strategically select time slots for semantic information transmission. Due to limited energy, the jammer will not communicate with the server and hence the server does not know the transmit power of the jammer. Therefore, the server must jointly optimize the semantic information transmitted at each time slot and the corresponding transmit power to maximize the privacy and the semantic information transmission quality of the user. To solve this problem, we propose a prioritised sampling assisted twin delayed deep deterministic policy gradient algorithm to jointly determine the transmitted semantic information and the transmit power per time slot without the communications between the server and the jammer. Compared to standard reinforcement learning methods, the propose method uses an additional Q network to estimate Q values such that the agent can select the action with a lower Q value from the two Q networks thus avoiding local optimal action selection and estimation bias of Q values. Simulation results show that the proposed algorithm can improve the privacy and the semantic information transmission quality by up to 77.8% and 14.3% compared to the traditional reinforcement learning methods.
Perception-Enhanced Multitask Multimodal Semantic Communication for UAV-Assisted Integrated Sensing and Communication System
Mar 25, 2025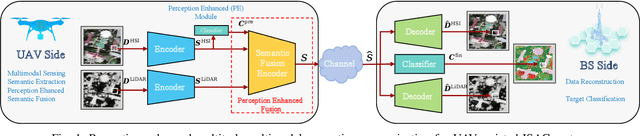
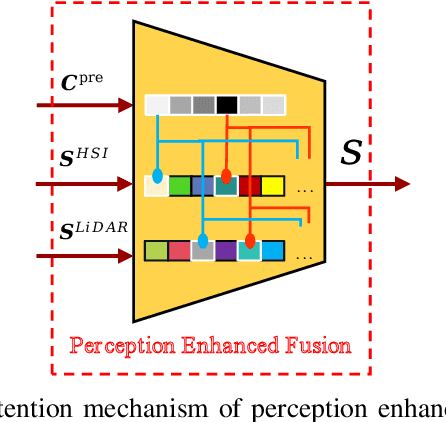


Recent advances in integrated sensing and communication (ISAC) unmanned aerial vehicles (UAVs) have enabled their widespread deployment in critical applications such as emergency management. This paper investigates the challenge of efficient multitask multimodal data communication in UAV-assisted ISAC systems, in the considered system model, hyperspectral (HSI) and LiDAR data are collected by UAV-mounted sensors for both target classification and data reconstruction at the terrestrial BS. The limited channel capacity and complex environmental conditions pose significant challenges to effective air-to-ground communication. To tackle this issue, we propose a perception-enhanced multitask multimodal semantic communication (PE-MMSC) system that strategically leverages the onboard computational and sensing capabilities of UAVs. In particular, we first propose a robust multimodal feature fusion method that adaptively combines HSI and LiDAR semantics while considering channel noise and task requirements. Then the method introduces a perception-enhanced (PE) module incorporating attention mechanisms to perform coarse classification on UAV side, thereby optimizing the attention-based multimodal fusion and transmission. Experimental results demonstrate that the proposed PE-MMSC system achieves 5\%--10\% higher target classification accuracy compared to conventional systems without PE module, while maintaining comparable data reconstruction quality with acceptable computational overheads.
Structure-Based Molecule Optimization via Gradient-Guided Bayesian Update
Nov 21, 2024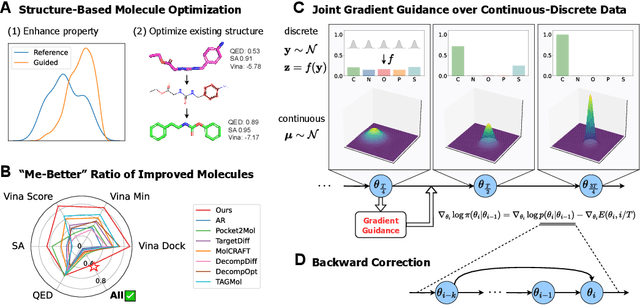
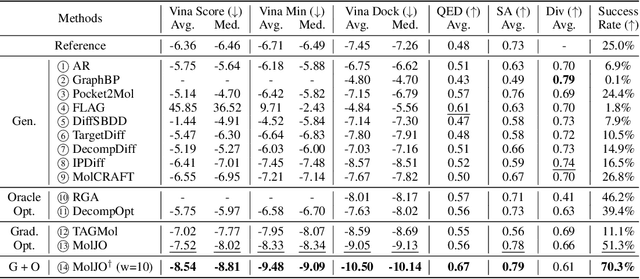
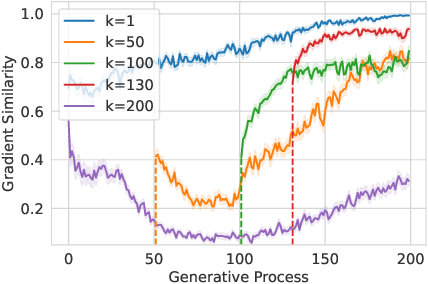
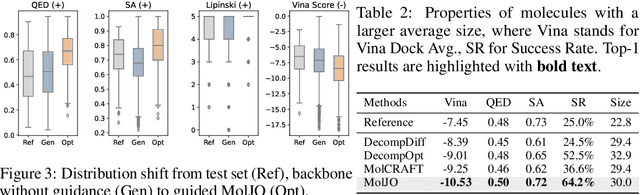
Structure-based molecule optimization (SBMO) aims to optimize molecules with both continuous coordinates and discrete types against protein targets. A promising direction is to exert gradient guidance on generative models given its remarkable success in images, but it is challenging to guide discrete data and risks inconsistencies between modalities. To this end, we leverage a continuous and differentiable space derived through Bayesian inference, presenting Molecule Joint Optimization (MolJO), the first gradient-based SBMO framework that facilitates joint guidance signals across different modalities while preserving SE(3)-equivariance. We introduce a novel backward correction strategy that optimizes within a sliding window of the past histories, allowing for a seamless trade-off between explore-and-exploit during optimization. Our proposed MolJO achieves state-of-the-art performance on CrossDocked2020 benchmark (Success Rate 51.3% , Vina Dock -9.05 and SA 0.78), more than 4x improvement in Success Rate compared to the gradient-based counterpart, and 2x "Me-Better" Ratio as much as 3D baselines. Furthermore, we extend MolJO to a wide range of optimization settings, including multi-objective optimization and challenging tasks in drug design such as R-group optimization and scaffold hopping, further underscoring its versatility and potential.
Stable Continual Reinforcement Learning via Diffusion-based Trajectory Replay
Nov 16, 2024



Given the inherent non-stationarity prevalent in real-world applications, continual Reinforcement Learning (RL) aims to equip the agent with the capability to address a series of sequentially presented decision-making tasks. Within this problem setting, a pivotal challenge revolves around \textit{catastrophic forgetting} issue, wherein the agent is prone to effortlessly erode the decisional knowledge associated with past encountered tasks when learning the new one. In recent progresses, the \textit{generative replay} methods have showcased substantial potential by employing generative models to replay data distribution of past tasks. Compared to storing the data from past tasks directly, this category of methods circumvents the growing storage overhead and possible data privacy concerns. However, constrained by the expressive capacity of generative models, existing \textit{generative replay} methods face challenges in faithfully reconstructing the data distribution of past tasks, particularly in scenarios with a myriad of tasks or high-dimensional data. Inspired by the success of diffusion models in various generative tasks, this paper introduces a novel continual RL algorithm DISTR (Diffusion-based Trajectory Replay) that employs a diffusion model to memorize the high-return trajectory distribution of each encountered task and wakeups these distributions during the policy learning on new tasks. Besides, considering the impracticality of replaying all past data each time, a prioritization mechanism is proposed to prioritize the trajectory replay of pivotal tasks in our method. Empirical experiments on the popular continual RL benchmark \texttt{Continual World} demonstrate that our proposed method obtains a favorable balance between \textit{stability} and \textit{plasticity}, surpassing various existing continual RL baselines in average success rate.
WHALE: Towards Generalizable and Scalable World Models for Embodied Decision-making
Nov 08, 2024



World models play a crucial role in decision-making within embodied environments, enabling cost-free explorations that would otherwise be expensive in the real world. To facilitate effective decision-making, world models must be equipped with strong generalizability to support faithful imagination in out-of-distribution (OOD) regions and provide reliable uncertainty estimation to assess the credibility of the simulated experiences, both of which present significant challenges for prior scalable approaches. This paper introduces WHALE, a framework for learning generalizable world models, consisting of two key techniques: behavior-conditioning and retracing-rollout. Behavior-conditioning addresses the policy distribution shift, one of the primary sources of the world model generalization error, while retracing-rollout enables efficient uncertainty estimation without the necessity of model ensembles. These techniques are universal and can be combined with any neural network architecture for world model learning. Incorporating these two techniques, we present Whale-ST, a scalable spatial-temporal transformer-based world model with enhanced generalizability. We demonstrate the superiority of Whale-ST in simulation tasks by evaluating both value estimation accuracy and video generation fidelity. Additionally, we examine the effectiveness of our uncertainty estimation technique, which enhances model-based policy optimization in fully offline scenarios. Furthermore, we propose Whale-X, a 414M parameter world model trained on 970K trajectories from Open X-Embodiment datasets. We show that Whale-X exhibits promising scalability and strong generalizability in real-world manipulation scenarios using minimal demonstrations.
Provably and Practically Efficient Adversarial Imitation Learning with General Function Approximation
Nov 01, 2024



As a prominent category of imitation learning methods, adversarial imitation learning (AIL) has garnered significant practical success powered by neural network approximation. However, existing theoretical studies on AIL are primarily limited to simplified scenarios such as tabular and linear function approximation and involve complex algorithmic designs that hinder practical implementation, highlighting a gap between theory and practice. In this paper, we explore the theoretical underpinnings of online AIL with general function approximation. We introduce a new method called optimization-based AIL (OPT-AIL), which centers on performing online optimization for reward functions and optimism-regularized Bellman error minimization for Q-value functions. Theoretically, we prove that OPT-AIL achieves polynomial expert sample complexity and interaction complexity for learning near-expert policies. To our best knowledge, OPT-AIL is the first provably efficient AIL method with general function approximation. Practically, OPT-AIL only requires the approximate optimization of two objectives, thereby facilitating practical implementation. Empirical studies demonstrate that OPT-AIL outperforms previous state-of-the-art deep AIL methods in several challenging tasks.
Energy-Guided Diffusion Sampling for Offline-to-Online Reinforcement Learning
Jul 17, 2024



Combining offline and online reinforcement learning (RL) techniques is indeed crucial for achieving efficient and safe learning where data acquisition is expensive. Existing methods replay offline data directly in the online phase, resulting in a significant challenge of data distribution shift and subsequently causing inefficiency in online fine-tuning. To address this issue, we introduce an innovative approach, \textbf{E}nergy-guided \textbf{DI}ffusion \textbf{S}ampling (EDIS), which utilizes a diffusion model to extract prior knowledge from the offline dataset and employs energy functions to distill this knowledge for enhanced data generation in the online phase. The theoretical analysis demonstrates that EDIS exhibits reduced suboptimality compared to solely utilizing online data or directly reusing offline data. EDIS is a plug-in approach and can be combined with existing methods in offline-to-online RL setting. By implementing EDIS to off-the-shelf methods Cal-QL and IQL, we observe a notable 20% average improvement in empirical performance on MuJoCo, AntMaze, and Adroit environments. Code is available at \url{https://github.com/liuxhym/EDIS}.