 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Semantic-based Agent Communication Networks: Vision, Technologies, and Challenges
Mar 25, 2026The International Telecommunication Union (ITU) identifies "Artificial Intelligence (AI) and Communication" as one of six key usage scenarios for 6G. Agentic AI, characterized by its ca-pabilities in multi-modal environmental sensing, complex task coordination, and continuous self-optimization, is anticipated to drive the evolution toward agent-based communication net-works. Semantic communication (SemCom), in turn, has emerged as a transformative paradigm that offers task-oriented efficiency, enhanced reliability in complex environments, and dynamic adaptation in resource allocation. However, comprehensive reviews that trace their technologi-cal evolution in the contexts of agent communications remain scarce. Addressing this gap, this paper systematically explores the role of semantics in agent communication networks. We first propose a novel architecture for semantic-based agent communication networks, structured into three layers, four entities, and four stages. Three wireless agent network layers define the logical structure and organization of entity interactions: the intention extraction and understanding layer, the semantic encoding and processing layer, and the distributed autonomy and collabora-tion layer. Across these layers, four AI agent entities, namely embodied agents, communication agents, network agents, and application agents, coexist and perform distinct tasks. Furthermore, four operational stages of semantic-enhanced agentic AI systems, namely perception, memory, reasoning, and action, form a cognitive cycle guiding agent behavior. Based on the proposed architecture, we provide a comprehensive review of the state-of-the-art on how semantics en-hance agent communication networks. Finally, we identify key challenges and present potential solutions to offer directional guidance for future research in this emerging field.
Perception-Enhanced Multitask Multimodal Semantic Communication for UAV-Assisted Integrated Sensing and Communication System
Mar 25, 2025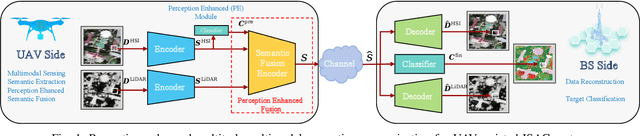
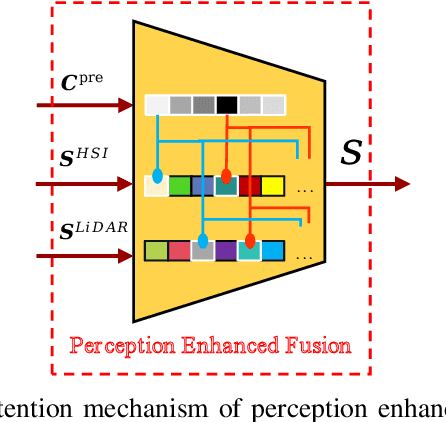


Recent advances in integrated sensing and communication (ISAC) unmanned aerial vehicles (UAVs) have enabled their widespread deployment in critical applications such as emergency management. This paper investigates the challenge of efficient multitask multimodal data communication in UAV-assisted ISAC systems, in the considered system model, hyperspectral (HSI) and LiDAR data are collected by UAV-mounted sensors for both target classification and data reconstruction at the terrestrial BS. The limited channel capacity and complex environmental conditions pose significant challenges to effective air-to-ground communication. To tackle this issue, we propose a perception-enhanced multitask multimodal semantic communication (PE-MMSC) system that strategically leverages the onboard computational and sensing capabilities of UAVs. In particular, we first propose a robust multimodal feature fusion method that adaptively combines HSI and LiDAR semantics while considering channel noise and task requirements. Then the method introduces a perception-enhanced (PE) module incorporating attention mechanisms to perform coarse classification on UAV side, thereby optimizing the attention-based multimodal fusion and transmission. Experimental results demonstrate that the proposed PE-MMSC system achieves 5\%--10\% higher target classification accuracy compared to conventional systems without PE module, while maintaining comparable data reconstruction quality with acceptable computational overheads.
DMCE: Diffusion Model Channel Enhancer for Multi-User Semantic Communication Systems
Jan 29, 2024



To achieve continuous massive data transmission with significantly reduced data payload, the users can adopt semantic communication techniques to compress the redundant information by transmitting semantic features instead. However, current works on semantic communication mainly focus on high compression ratio, neglecting the wireless channel effects including dynamic distortion and multi-user interference, which significantly limit the fidelity of semantic communication. To address this, this paper proposes a diffusion model (DM)-based channel enhancer (DMCE) for improving the performance of multi-user semantic communication, with the DM learning the particular data distribution of channel effects on the transmitted semantic features. In the considered system model, multiple users (such as road cameras) transmit semantic features of multi-source data to a receiver by applying the joint source-channel coding (JSCC) techniques, and the receiver fuses the semantic features from multiple users to complete specific tasks. Then, we propose DMCE to enhance the channel state information (CSI) estimation for improving the restoration of the received semantic features. Finally, the fusion results at the receiver are significantly enhanced, demonstrating a robust performance even under low signal-to-noise ratio (SNR) regimes, enabling the generation of effective object segmentation images. Extensive simulation results with a traffic scenario dataset show that the proposed scheme can improve the mean Intersection over Union (mIoU) by more than 25\% at low SNR regimes, compared with the benchmark schemes.
Importance-Aware Image Segmentation-based Semantic Communication for Autonomous Driving
Jan 16, 2024This article studies the problem of image segmentation-based semantic communication in autonomous driving. In real traffic scenes, detecting the key objects (e.g., vehicles, pedestrians and obstacles) is more crucial than that of other objects to guarantee driving safety. Therefore, we propose a vehicular image segmentation-oriented semantic communication system, termed VIS-SemCom, where image segmentation features of important objects are transmitted to reduce transmission redundancy. First, to accurately extract image semantics, we develop a semantic codec based on Swin Transformer architecture, which expands the perceptual field thus improving the segmentation accuracy. Next, we propose a multi-scale semantic extraction scheme via assigning the number of Swin Transformer blocks for diverse resolution features, thus highlighting the important objects' accuracy. Furthermore, the importance-aware loss is invoked to emphasize the important objects, and an online hard sample mining (OHEM) strategy is proposed to handle small sample issues in the dataset. Experimental results demonstrate that the proposed VIS-SemCom can achieve a coding gain of nearly 6 dB with a 60% mean intersection over union (mIoU), reduce the transmitted data amount by up to 70% with a 60% mIoU, and improve the segmentation intersection over union (IoU) of important objects by 4%, compared to traditional transmission scheme.
Attention-based UNet enabled Lightweight Image Semantic Communication System over Internet of Things
Jan 14, 2024This paper studies the problem of the lightweight image semantic communication system that is deployed on Internet of Things (IoT) devices. In the considered system model, devices must use semantic communication techniques to support user behavior recognition in ultimate video service with high data transmission efficiency. However, it is computationally expensive for IoT devices to deploy semantic codecs due to the complex calculation processes of deep learning (DL) based codec training and inference. To make it affordable for IoT devices to deploy semantic communication systems, we propose an attention-based UNet enabled lightweight image semantic communication (LSSC) system, which achieves low computational complexity and small model size. In particular, we first let the LSSC system train the codec at the edge server to reduce the training computation load on IoT devices. Then, we introduce the convolutional block attention module (CBAM) to extract the image semantic features and decrease the number of downsampling layers thus reducing the floating-point operations (FLOPs). Finally, we experimentally adjust the structure of the codec and find out the optimal number of downsampling layers. Simulation results show that the proposed LSSC system can reduce the semantic codec FLOPs by 14%, and reduce the model size by 55%, with a sacrifice of 3% accuracy, compared to the baseline. Moreover, the proposed scheme can achieve a higher transmission accuracy than the traditional communication scheme in the low channel signal-to-noise (SNR) region.
Near-Field Beam Training of Intelligent Reflecting Surface: A Novel Two-Layer Codebook
Mar 13, 2023This paper investigates the codebook based near-field beam training of Intelligent Reflecting Surface (IRS). In the considered model, near-field beam training should be performed to focus the signals at the location of user equipment (UE) to obtain the prominent IRS array gain. However, existing codebook schemes can not realize low training overhead and high receiving power, simultaneously. To tackle this issue, a novel two-layer codebook is proposed. Specifically, the layer-1 codebook is designed based on the omnidirectivity of random-phase beam pattern, which estimates the UE distance with training overhead equivalent to that of a DFT codeword. Then, based on the estimated distance of UE, the layer-2 codebook is generated to scan the candidate locations of UE, and finally obtain the optimal codeword for IRS beamforming. Numerical results show that, compared with the benchmarks, the proposed codebook scheme makes more accurate estimation of UE distances and angles, achieving higher date rate, yet with a smaller training overhead.
Transfer-Learning Oriented Class Imbalance Learning for Cross-Project Defect Prediction
Jan 24, 2019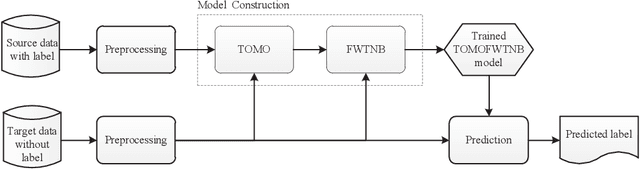
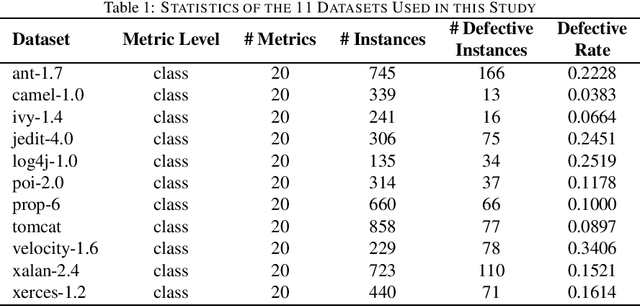
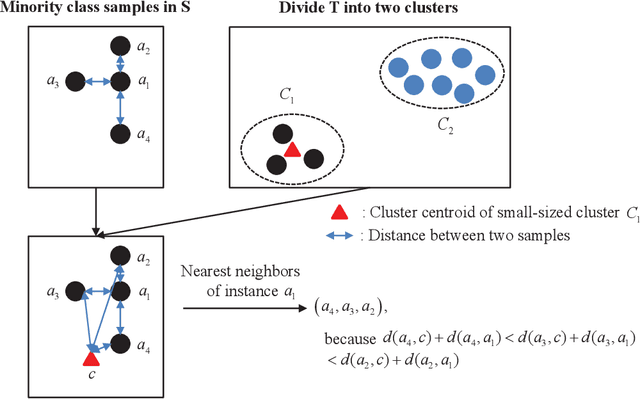
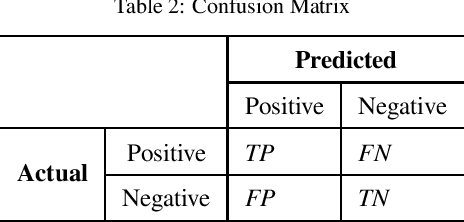
Cross-project defect prediction (CPDP) aims to predict defects of projects lacking training data by using prediction models trained on historical defect data from other projects. However, since the distribution differences between datasets from different projects, it is still a challenge to build high-quality CPDP models. Unfortunately, class imbalanced nature of software defect datasets further increases the difficulty. In this paper, we propose a transferlearning oriented minority over-sampling technique (TOMO) based feature weighting transfer naive Bayes (FWTNB) approach (TOMOFWTNB) for CPDP by considering both classimbalance and feature importance problems. Differing from traditional over-sampling techniques, TOMO not only can balance the data but reduce the distribution difference. And then FWTNB is used to further increase the similarity of two distributions. Experiments are performed on 11 public defect datasets. The experimental results show that (1) TOMO improves the average G-Measure by 23.7\%$\sim$41.8\%, and the average MCC by 54.2\%$\sim$77.8\%. (2) feature weighting (FW) strategy improves the average G-Measure by 11\%, and the average MCC by 29.2\%. (3) TOMOFWTNB improves the average G-Measure value by at least 27.8\%, and the average MCC value by at least 71.5\%, compared with existing state-of-theart CPDP approaches. It can be concluded that (1) TOMO is very effective for addressing class-imbalance problem in CPDP scenario; (2) our FW strategy is helpful for CPDP; (3) TOMOFWTNB outperforms previous state-of-the-art CPDP approaches.