 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMCE: Diffusion Model Channel Enhancer for Multi-User Semantic Communication Systems
Jan 29, 2024



To achieve continuous massive data transmission with significantly reduced data payload, the users can adopt semantic communication techniques to compress the redundant information by transmitting semantic features instead. However, current works on semantic communication mainly focus on high compression ratio, neglecting the wireless channel effects including dynamic distortion and multi-user interference, which significantly limit the fidelity of semantic communication. To address this, this paper proposes a diffusion model (DM)-based channel enhancer (DMCE) for improving the performance of multi-user semantic communication, with the DM learning the particular data distribution of channel effects on the transmitted semantic features. In the considered system model, multiple users (such as road cameras) transmit semantic features of multi-source data to a receiver by applying the joint source-channel coding (JSCC) techniques, and the receiver fuses the semantic features from multiple users to complete specific tasks. Then, we propose DMCE to enhance the channel state information (CSI) estimation for improving the restoration of the received semantic features. Finally, the fusion results at the receiver are significantly enhanced, demonstrating a robust performance even under low signal-to-noise ratio (SNR) regimes, enabling the generation of effective object segmentation images. Extensive simulation results with a traffic scenario dataset show that the proposed scheme can improve the mean Intersection over Union (mIoU) by more than 25\% at low SNR regimes, compared with the benchmark schemes.
GLD-Net: Improving Monaural Speech Enhancement by Learning Global and Local Dependency Features with GLD Block
Jun 30, 2022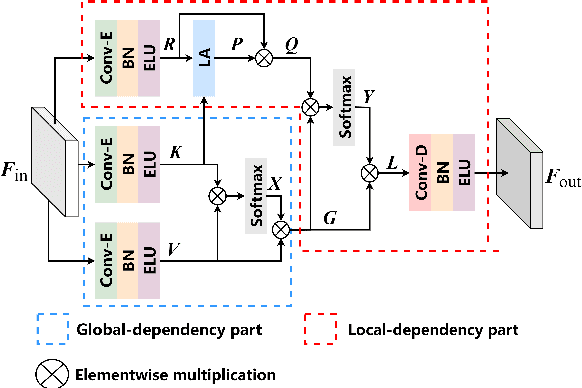
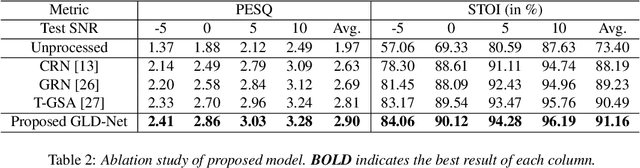
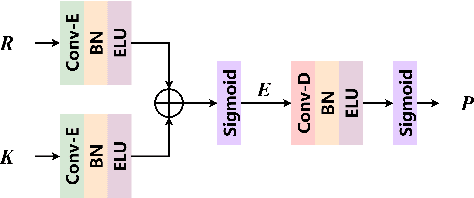

For monaural speech enhancement, contextual information is important for accurate speech estimation. However, commonly used convolution neural networks (CNNs) are weak in capturing temporal contexts since they only build blocks that process one local neighborhood at a time. To address this problem, we learn from human auditory perception to introduce a two-stage trainable reasoning mechanism, referred as global-local dependency (GLD) block. GLD blocks capture long-term dependency of time-frequency bins both in global level and local level from the noisy spectrogram to help detecting correlations among speech part, noise part, and whole noisy input. What is more, we conduct a monaural speech enhancement network called GLD-Net, which adopts encoder-decoder architecture and consists of speech object branch, interference branch, and global noisy branch. The extracted speech feature at global-level and local-level are efficiently reasoned and aggregated in each of the branches. We compare the proposed GLD-Net with existing state-of-art methods on WSJ0 and DEMAND dataset. The results show that GLD-Net outperforms the state-of-the-art methods in terms of PESQ and STOI.
Improving Monaural Speech Enhancement with Multi-head Self and Cross Attention
May 20, 2022
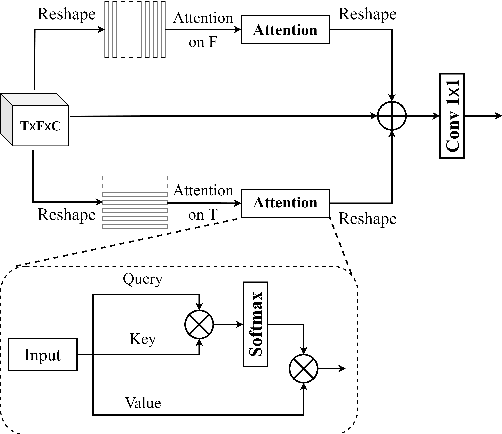
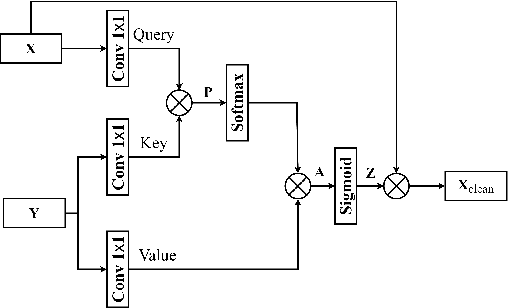

For supervised speech enhancement, contextual information is important for accurate spectral mapping. However, commonly used deep neural networks (DNNs) are limited in capturing temporal contexts. To leverage long-term contexts for tracking a target speaker, this paper treats the speech enhancement as sequence-to-sequence mapping, and propose a novel monaural speech enhancement U-net structure based on Transformer, dubbed U-Former. The key idea is to model long-term correlations and dependencies, which are crucial for accurate noisy speech modeling, through the multi-head attention mechanisms. For this purpose, U-Former incorporates multi-head attention mechanisms at two levels: 1) a multi-head self-attention module which calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps for leveraging global interactions between encoder features, while 2) multi-head cross-attention module which are inserted in the skip connections allows a fine recovery in the decoder by filtering out uncorrelated features. Experimental results illustrate that the U-Former obtains consistently better performance than recent models of PESQ, STOI, and SSNR scores.