 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Monaural Speech Enhancement with Multi-head Self and Cross Attention
Paper and Code

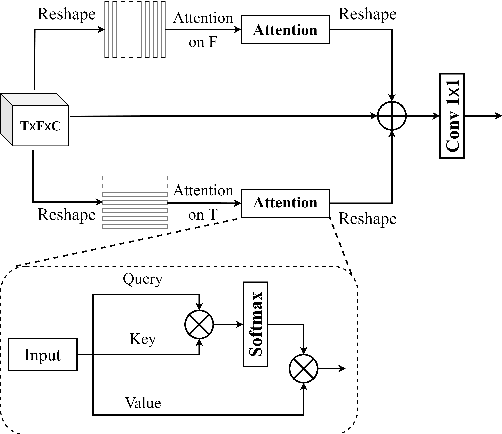
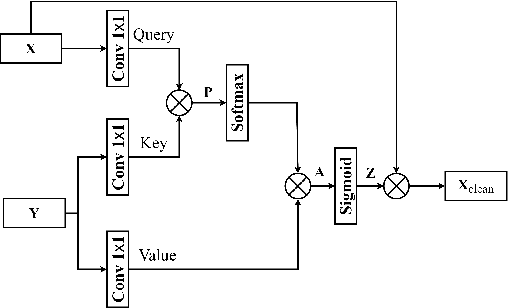

For supervised speech enhancement, contextual information is important for accurate spectral mapping. However, commonly used deep neural networks (DNNs) are limited in capturing temporal contexts. To leverage long-term contexts for tracking a target speaker, this paper treats the speech enhancement as sequence-to-sequence mapping, and propose a novel monaural speech enhancement U-net structure based on Transformer, dubbed U-Former. The key idea is to model long-term correlations and dependencies, which are crucial for accurate noisy speech modeling, through the multi-head attention mechanisms. For this purpose, U-Former incorporates multi-head attention mechanisms at two levels: 1) a multi-head self-attention module which calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps for leveraging global interactions between encoder features, while 2) multi-head cross-attention module which are inserted in the skip connections allows a fine recovery in the decoder by filtering out uncorrelated features. Experimental results illustrate that the U-Former obtains consistently better performance than recent models of PESQ, STOI, and SSNR scores.