 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speech Enhancement by Cross- and Sub-band Processing with State Space Model
Feb 22, 2025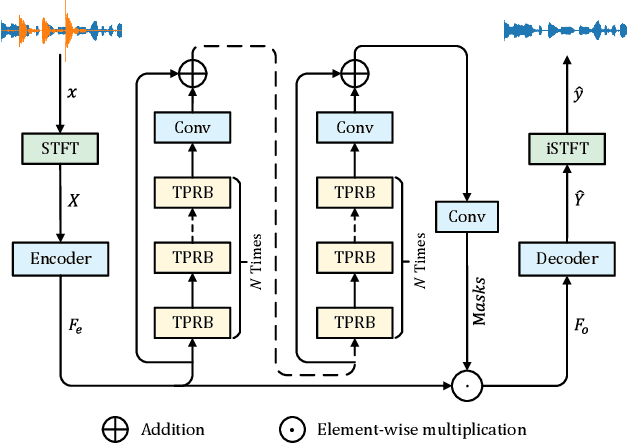
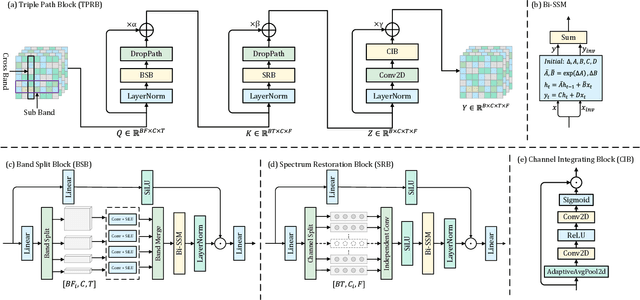

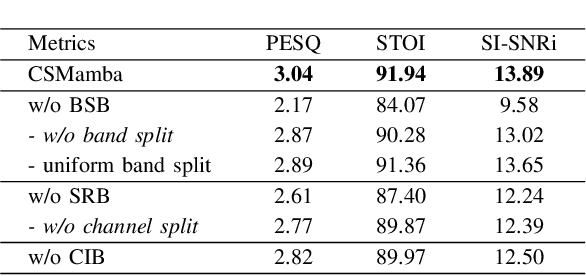
Recently, the state space model (SSM) represented by Mamba has shown remarkable performance in long-term sequence modeling tasks, including speech enhancement. However, due to substantial differences in sub-band features, applying the same SSM to all sub-bands limits its inference capability. Additionally, when processing each time frame of the time-frequency representation, the SSM may forget certain high-frequency information of low energy, making the restoration of structure in the high-frequency bands challenging. For this reason, we propose Cross- and Sub-band Mamba (CSMamba). To assist the SSM in handling different sub-band features flexibly, we propose a band split block that splits the full-band into four sub-bands with different widths based on their information similarity. We then allocate independent weights to each sub-band, thereby reducing the inference burden on the SSM. Furthermore, to mitigate the forgetting of low-energy information in the high-frequency bands by the SSM, we introduce a spectrum restoration block that enhances the representation of the cross-band features from multiple perspectives. Experimental results on the DNS Challenge 2021 dataset demonstrate that CSMamba outperforms several state-of-the-art (SOTA) speech enhancement methods in three objective evaluation metrics with fewer parameters.
SuperCodec: A Neural Speech Codec with Selective Back-Projection Network
Jul 30, 2024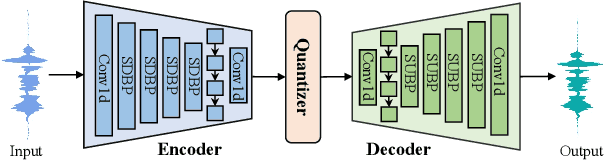
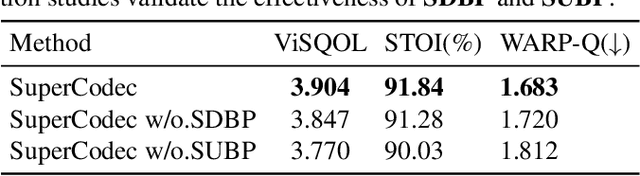
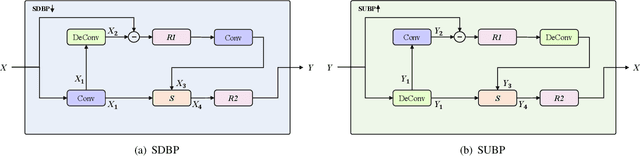

Neural speech coding is a rapidly developing topic, where state-of-the-art approaches now exhibit superior compression performance than conventional methods. Despite significant progress, existing methods still have limitations in preserving and reconstructing fine details for optimal reconstruction, especially at low bitrates. In this study, we introduce SuperCodec, a neural speech codec that achieves state-of-the-art performance at low bitrates. It employs a novel back projection method with selective feature fusion for augmented representation. Specifically, we propose to use Selective Up-sampling Back Projection (SUBP) and Selective Down-sampling Back Projection (SDBP) modules to replace the standard up- and down-sampling layers at the encoder and decoder, respectively. Experimental results show that our method outperforms the existing neural speech codecs operating at various bitrates. Specifically, our proposed method can achieve higher quality reconstructed speech at 1 kbps than Lyra V2 at 3.2 kbps and Encodec at 6 kbps.
Improving Speech Enhancement by Integrating Inter-Channel and Band Features with Dual-branch Conformer
Jul 11, 2024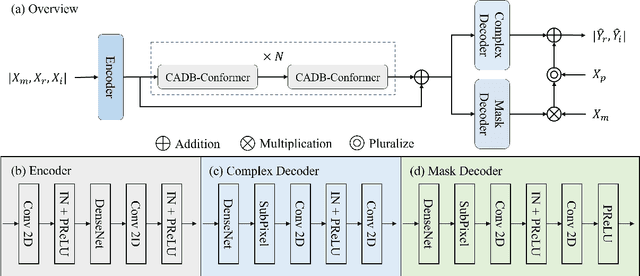
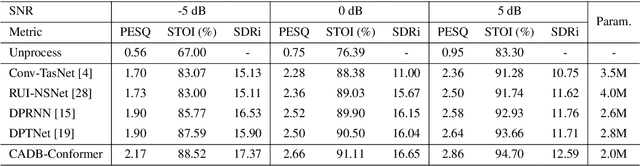
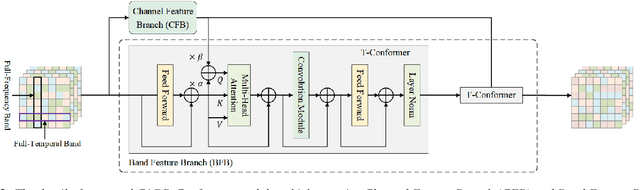
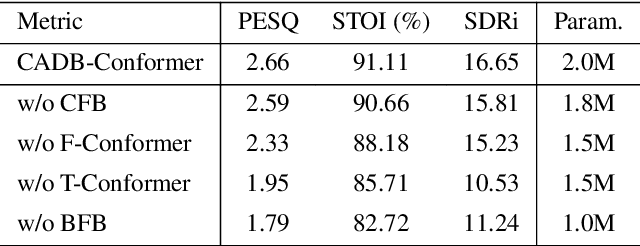
Recent speech enhancement methods based on convolutional neural networks (CNNs) and transformer have been demonstrated to efficaciously capture time-frequency (T-F) information on spectrogram. However, the correlation of each channels of speech features is failed to explore. Theoretically, each channel map of speech features obtained by different convolution kernels contains information with different scales demonstrating strong correlations. To fill this gap, we propose a novel dual-branch architecture named channel-aware dual-branch conformer (CADB-Conformer), which effectively explores the long range time and frequency correlations among different channels, respectively, to extract channel relation aware time-frequency information. Ablation studies conducted on DNS-Challenge 2020 dataset demonstrate the importance of channel feature leveraging while showing the significance of channel relation aware T-F information for speech enhancement. Extensive experiments also show that the proposed model achieves superior performance than recent methods with an attractive computational costs.
SE Territory: Monaural Speech Enhancement Meets the Fixed Virtual Perceptual Space Mapping
Nov 03, 2023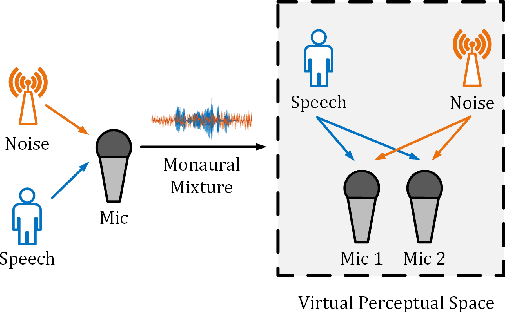



Monaural speech enhancement has achieved remarkable progress recently. However, its performance has been constrained by the limited spatial cues available at a single microphone. To overcome this limitation, we introduce a strategy to map monaural speech into a fixed simulation space for better differentiation between target speech and noise. Concretely, we propose SE-TerrNet, a novel monaural speech enhancement model featuring a virtual binaural speech mapping network via a two-stage multi-task learning framework. In the first stage, monaural noisy input is projected into a virtual space using supervised speech mapping blocks, creating binaural representations. These blocks synthesize binaural noisy speech from monaural input via an ideal binaural room impulse response. The synthesized output assigns speech and noise sources to fixed directions within the perceptual space. In the second stage, the obtained binaural features from the first stage are aggregated. This aggregation aims to decrease pattern discrepancies between the mapped binaural and original monaural features, achieved by implementing an intermediate fusion module. Furthermore, this stage incorporates the utilization of cross-attention to capture the injected virtual spatial information to improve the extraction of the target speech. Empirical studies highlight the effectiveness of virtual spatial cues in enhancing monaural speech enhancement. As a result, the proposed SE-TerrNet significantly surpasses the recent monaural speech enhancement methods in terms of both speech quality and intelligibility.
PCNN: A Lightweight Parallel Conformer Neural Network for Efficient Monaural Speech Enhancement
Jul 28, 2023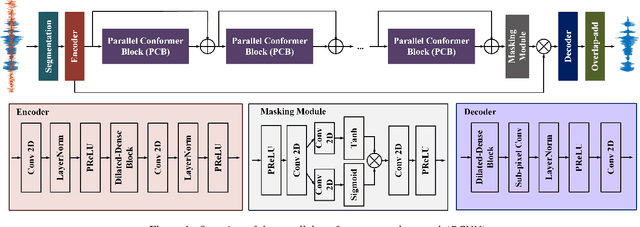
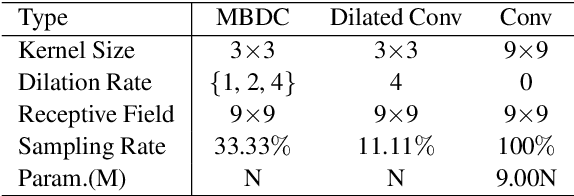
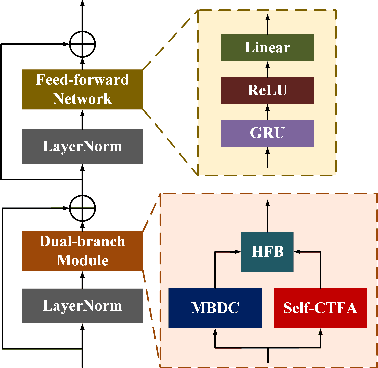
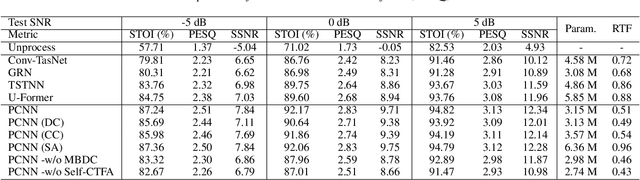
Convolutional neural networks (CNN) and Transformer have wildly succeeded in multimedia applications. However, more effort needs to be made to harmonize these two architectures effectively to satisfy speech enhancement. This paper aims to unify these two architectures and presents a Parallel Conformer for speech enhancement. In particular, the CNN and the self-attention (SA) in the Transformer are fully exploited for local format patterns and global structure representations. Based on the small receptive field size of CNN and the high computational complexity of SA, we specially designed a multi-branch dilated convolution (MBDC) and a self-channel-time-frequency attention (Self-CTFA) module. MBDC contains three convolutional layers with different dilation rates for the feature from local to non-local processing. Experimental results show that our method performs better than state-of-the-art methods in most evaluation criteria while maintaining the lowest model parameters.
Exploring the Interactions between Target Positive and Negative Information for Acoustic Echo Cancellation
Jul 26, 2023



Acoustic echo cancellation (AEC) aims to remove interference signals while leaving near-end speech least distorted. As the indistinguishable patterns between near-end speech and interference signals, near-end speech can't be separated completely, causing speech distortion and interference signals residual. We observe that besides target positive information, e.g., ground-truth speech and features, the target negative information, such as interference signals and features, helps make pattern of target speech and interference signals more discriminative. Therefore, we present a novel AEC model encoder-decoder architecture with the guidance of negative information termed as CMNet. A collaboration module (CM) is designed to establish the correlation between the target positive and negative information in a learnable manner via three blocks: target positive, target negative, and interactive block. Experimental results demonstrate our CMNet achieves superior performance than recent methods.
CQNV: A combination of coarsely quantized bitstream and neural vocoder for low rate speech coding
Jul 25, 2023



Recently, speech codecs based on neural networks have proven to perform better than traditional methods. However, redundancy in traditional parameter quantization is visible within the codec architecture of combining the traditional codec with the neural vocoder. In this paper, we propose a novel framework named CQNV, which combines the coarsely quantized parameters of a traditional parametric codec to reduce the bitrate with a neural vocoder to improve the quality of the decoded speech. Furthermore, we introduce a parameters processing module into the neural vocoder to enhance the application of the bitstream of traditional speech coding parameters to the neural vocoder, further improving the reconstructed speech's quality. In the experiments, both subjective and objective evaluations demonstrate the effectiveness of the proposed CQNV framework. Specifically, our proposed method can achieve higher quality reconstructed speech at 1.1 kbps than Lyra and Encodec at 3 kbps.
All Information is Necessary: Integrating Speech Positive and Negative Information by Contrastive Learning for Speech Enhancement
Apr 26, 2023Monaural speech enhancement (SE) is an ill-posed problem due to the irreversible degradation process. Recent methods to achieve SE tasks rely solely on positive information, e.g., ground-truth speech and speech-relevant features. Different from the above, we observe that the negative information, such as original speech mixture and speech-irrelevant features, are valuable to guide the SE model training procedure. In this study, we propose a SE model that integrates both speech positive and negative information for improving SE performance by adopting contrastive learning, in which two innovations have consisted. (1) We design a collaboration module (CM), which contains two parts, contrastive attention for separating relevant and irrelevant features via contrastive learning and interactive attention for establishing the correlation between both speech features in a learnable and self-adaptive manner. (2) We propose a contrastive regularization (CR) built upon contrastive learning to ensure that the estimated speech is pulled closer to the clean speech and pushed far away from the noisy speech in the representation space by integrating self-supervised models. We term the proposed SE network with CM and CR as CMCR-Net. Experimental results demonstrate that our CMCR-Net achieves comparable and superior performance to recent approaches.
Selector-Enhancer: Learning Dynamic Selection of Local and Non-local Attention Operation for Speech Enhancement
Dec 07, 2022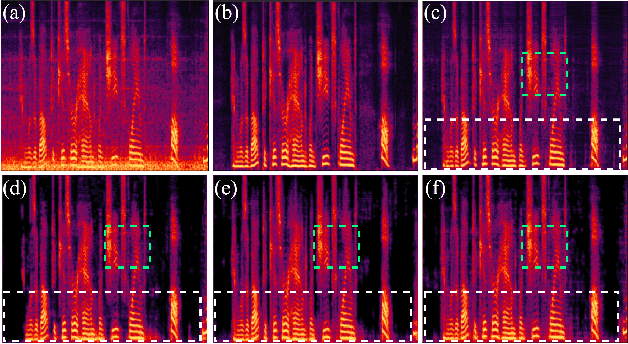
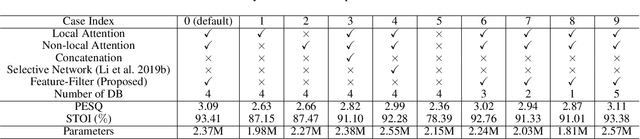
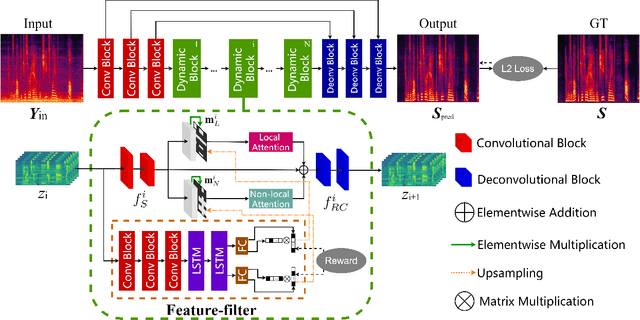

Attention mechanisms, such as local and non-local attention, play a fundamental role in recent deep learning based speech enhancement (SE) systems. However, natural speech contains many fast-changing and relatively brief acoustic events, therefore, capturing the most informative speech features by indiscriminately using local and non-local attention is challenged. We observe that the noise type and speech feature vary within a sequence of speech and the local and non-local operations can respectively extract different features from corrupted speech. To leverage this, we propose Selector-Enhancer, a dual-attention based convolution neural network (CNN) with a feature-filter that can dynamically select regions from low-resolution speech features and feed them to local or non-local attention operations. In particular, the proposed feature-filter is trained by using reinforcement learning (RL) with a developed difficulty-regulated reward that is related to network performance, model complexity, and "the difficulty of the SE task". The results show that our method achieves comparable or superior performance to existing approaches. In particular, Selector-Enhancer is potentially effective for real-world denoising, where the number and types of noise are varies on a single noisy mixture.
Injecting Spatial Information for Monaural Speech Enhancement via Knowledge Distillation
Dec 02, 2022Monaural speech enhancement (SE) provides a versatile and cost-effective approach to SE tasks by utilizing recordings from a single microphone. However, the monaural SE lags performance behind multi-channel SE as the monaural SE methods are unable to extract spatial information from one-channel recordings, which greatly limits their application scenarios. To address this issue, we inject spatial information into the monaural SE model and propose a knowledge distillation strategy to enable the monaural SE model to learn binaural speech features from the binaural SE model, which makes monaural SE model possible to reconstruct higher intelligibility and quality enhanced speeches under low signal-to-noise ratio (SNR) conditions. Extensive experiments show that our proposed monaural SE model by injecting spatial information via knowledge distillation achieves favorable performance against other monaural SE models with fewer parameters.