 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speech Enhancement by Cross- and Sub-band Processing with State Space Model
Paper and Code
Feb 22, 2025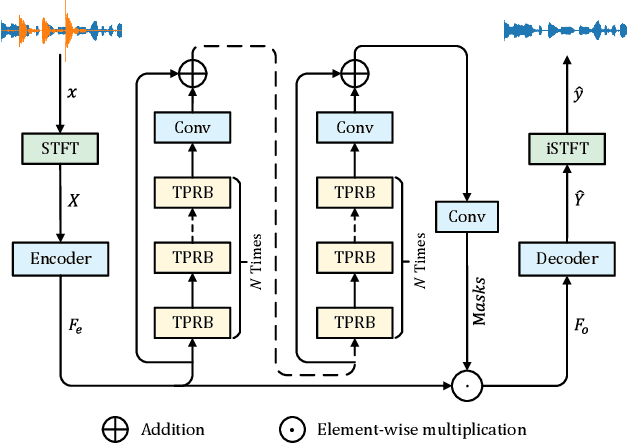
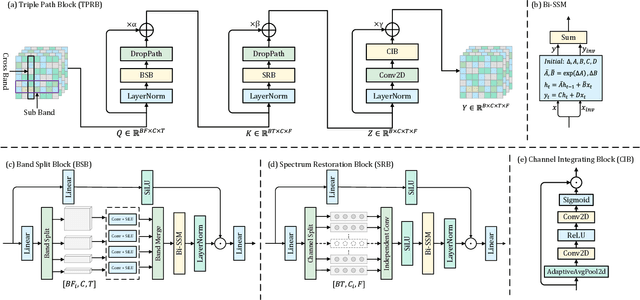

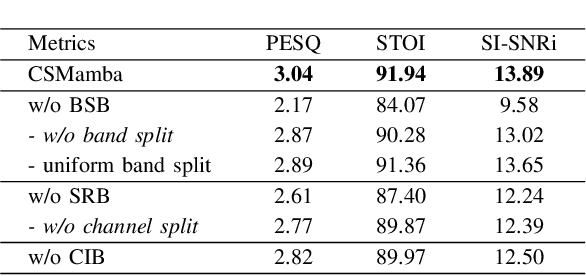
Recently, the state space model (SSM) represented by Mamba has shown remarkable performance in long-term sequence modeling tasks, including speech enhancement. However, due to substantial differences in sub-band features, applying the same SSM to all sub-bands limits its inference capability. Additionally, when processing each time frame of the time-frequency representation, the SSM may forget certain high-frequency information of low energy, making the restoration of structure in the high-frequency bands challenging. For this reason, we propose Cross- and Sub-band Mamba (CSMamba). To assist the SSM in handling different sub-band features flexibly, we propose a band split block that splits the full-band into four sub-bands with different widths based on their information similarity. We then allocate independent weights to each sub-band, thereby reducing the inference burden on the SSM. Furthermore, to mitigate the forgetting of low-energy information in the high-frequency bands by the SSM, we introduce a spectrum restoration block that enhances the representation of the cross-band features from multiple perspectives. Experimental results on the DNS Challenge 2021 dataset demonstrate that CSMamba outperforms several state-of-the-art (SOTA) speech enhancement methods in three objective evaluation metrics with fewer parameters.