 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformTrace: A Deformable State Space Model with Relay Tokens for Temporal Forgery Localization
Mar 05, 2026Temporal Forgery Localization (TFL) aims to precisely identify manipulated segments in video and audio, offering strong interpretability for security and forensics. While recent State Space Models (SSMs) show promise in precise temporal reasoning, their use in TFL is hindered by ambiguous boundaries, sparse forgeries, and limited long-range modeling. We propose DeformTrace, which enhances SSMs with deformable dynamics and relay mechanisms to address these challenges. Specifically, Deformable Self-SSM (DS-SSM) introduces dynamic receptive fields into SSMs for precise temporal localization. To further enhance its capacity for temporal reasoning and mitigate long-range decay, a Relay Token Mechanism is integrated into DS-SSM. Besides, Deformable Cross-SSM (DC-SSM) partitions the global state space into query-specific subspaces, reducing non-forgery information accumulation and boosting sensitivity to sparse forgeries. These components are integrated into a hybrid architecture that combines the global modeling of Transformers with the efficiency of SSMs. Extensive experiments show that DeformTrace achieves state-of-the-art performance with fewer parameters, faster inference, and stronger robustness.
GEM-TFL: Bridging Weak and Full Supervision for Forgery Localization through EM-Guided Decomposition and Temporal Refinement
Mar 05, 2026Temporal Forgery Localization (TFL) aims to precisely identify manipulated segments within videos or audio streams, providing interpretable evidence for multimedia forensics and security. While most existing TFL methods rely on dense frame-level labels in a fully supervised manner, Weakly Supervised TFL (WS-TFL) reduces labeling cost by learning only from binary video-level labels. However, current WS-TFL approaches suffer from mismatched training and inference objectives, limited supervision from binary labels, gradient blockage caused by non-differentiable top-k aggregation, and the absence of explicit modeling of inter-proposal relationships. To address these issues, we propose GEM-TFL (Graph-based EM-powered Temporal Forgery Localization), a two-phase classification-regression framework that effectively bridges the supervision gap between training and inference. Built upon this foundation, (1) we enhance weak supervision by reformulating binary labels into multi-dimensional latent attributes through an EM-based optimization process; (2) we introduce a training-free temporal consistency refinement that realigns frame-level predictions for smoother temporal dynamics; and (3) we design a graph-based proposal refinement module that models temporal-semantic relationships among proposals for globally consistent confidence estimation. Extensive experiments on benchmark datasets demonstrate that GEM-TFL achieves more accurate and robust temporal forgery localization, substantially narrowing the gap with fully supervised methods.
Improving Speech Enhancement by Cross- and Sub-band Processing with State Space Model
Feb 22, 2025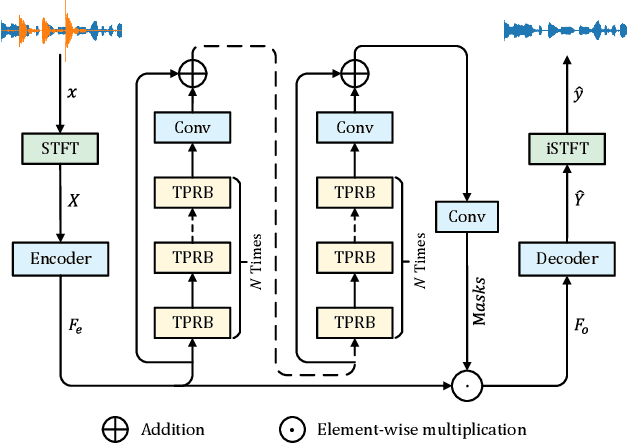
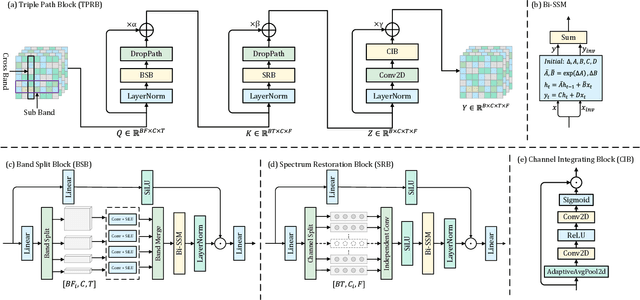

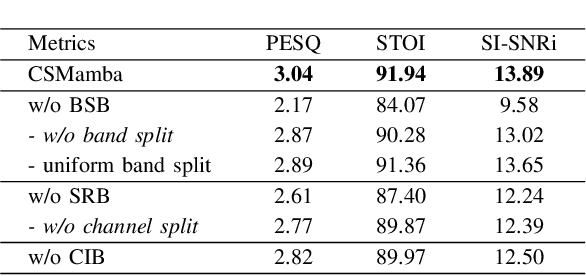
Recently, the state space model (SSM) represented by Mamba has shown remarkable performance in long-term sequence modeling tasks, including speech enhancement. However, due to substantial differences in sub-band features, applying the same SSM to all sub-bands limits its inference capability. Additionally, when processing each time frame of the time-frequency representation, the SSM may forget certain high-frequency information of low energy, making the restoration of structure in the high-frequency bands challenging. For this reason, we propose Cross- and Sub-band Mamba (CSMamba). To assist the SSM in handling different sub-band features flexibly, we propose a band split block that splits the full-band into four sub-bands with different widths based on their information similarity. We then allocate independent weights to each sub-band, thereby reducing the inference burden on the SSM. Furthermore, to mitigate the forgetting of low-energy information in the high-frequency bands by the SSM, we introduce a spectrum restoration block that enhances the representation of the cross-band features from multiple perspectives. Experimental results on the DNS Challenge 2021 dataset demonstrate that CSMamba outperforms several state-of-the-art (SOTA) speech enhancement methods in three objective evaluation metrics with fewer parameters.
FreeCodec: A disentangled neural speech codec with fewer tokens
Dec 02, 2024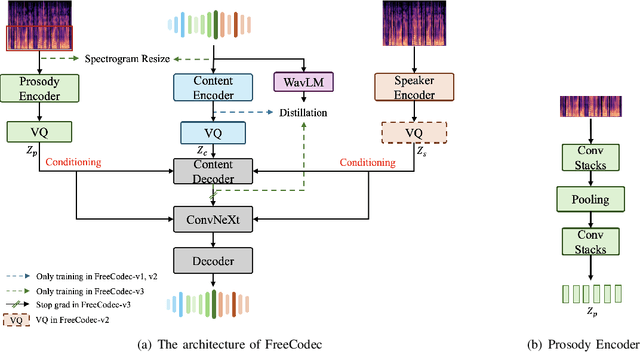
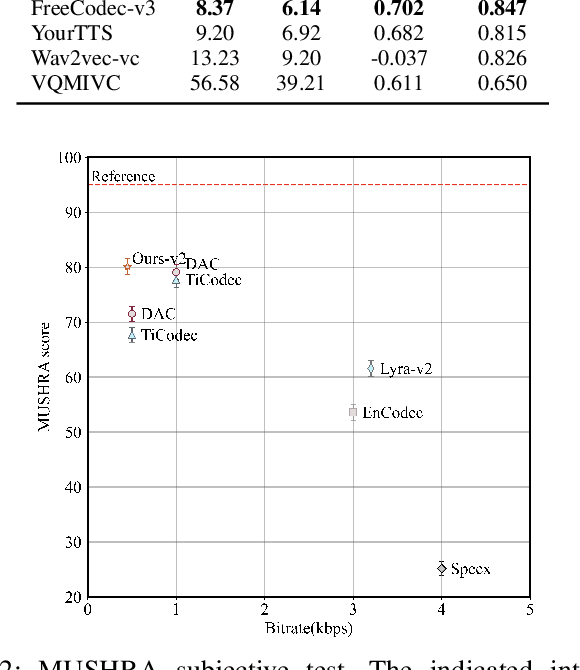
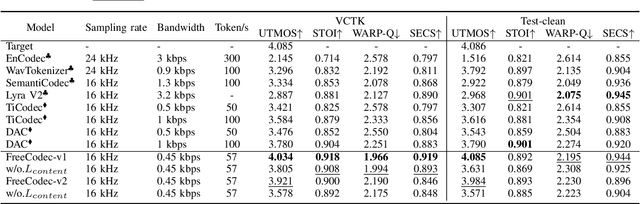
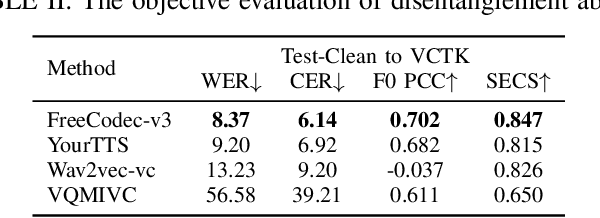
Neural speech codecs have gained great attention for their outstanding reconstruction with discrete token representations. It is a crucial component in generative tasks such as speech coding and large language models (LLM). However, most works based on residual vector quantization perform worse with fewer tokens due to low coding efficiency for modeling complex coupled information. In this paper, we propose a neural speech codec named FreeCodec which employs a more effective encoding framework by decomposing intrinsic properties of speech into different components: 1) a global vector is extracted as the timbre information, 2) a prosody encoder with a long stride level is used to model the prosody information, 3) the content information is from a content encoder. Using different training strategies, FreeCodec achieves state-of-the-art performance in reconstruction and disentanglement scenarios. Results from subjective and objective experiments demonstrate that our framework outperforms existing methods.
SuperCodec: A Neural Speech Codec with Selective Back-Projection Network
Jul 30, 2024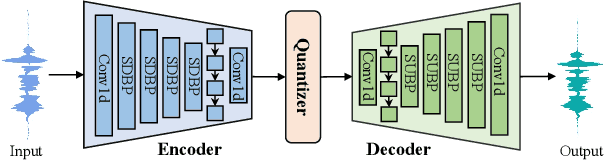
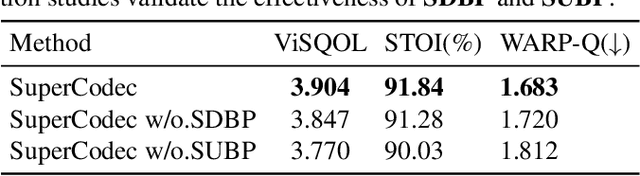
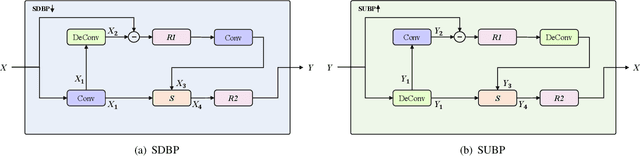

Neural speech coding is a rapidly developing topic, where state-of-the-art approaches now exhibit superior compression performance than conventional methods. Despite significant progress, existing methods still have limitations in preserving and reconstructing fine details for optimal reconstruction, especially at low bitrates. In this study, we introduce SuperCodec, a neural speech codec that achieves state-of-the-art performance at low bitrates. It employs a novel back projection method with selective feature fusion for augmented representation. Specifically, we propose to use Selective Up-sampling Back Projection (SUBP) and Selective Down-sampling Back Projection (SDBP) modules to replace the standard up- and down-sampling layers at the encoder and decoder, respectively. Experimental results show that our method outperforms the existing neural speech codecs operating at various bitrates. Specifically, our proposed method can achieve higher quality reconstructed speech at 1 kbps than Lyra V2 at 3.2 kbps and Encodec at 6 kbps.
Improving Speech Enhancement by Integrating Inter-Channel and Band Features with Dual-branch Conformer
Jul 11, 2024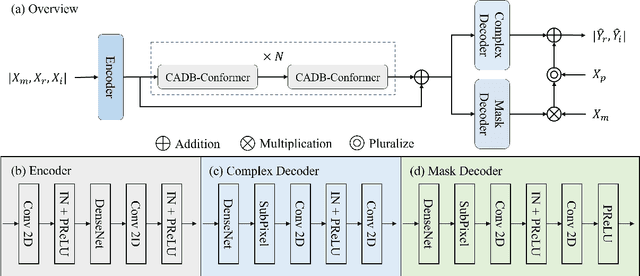
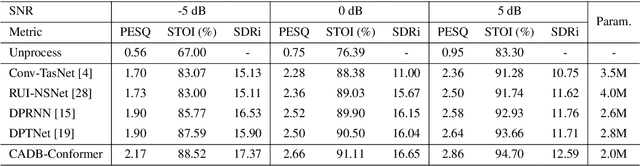
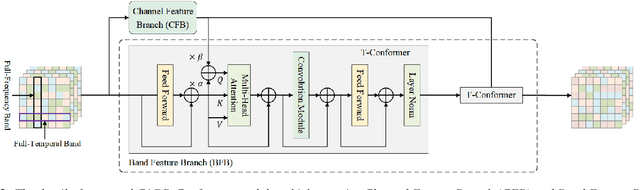
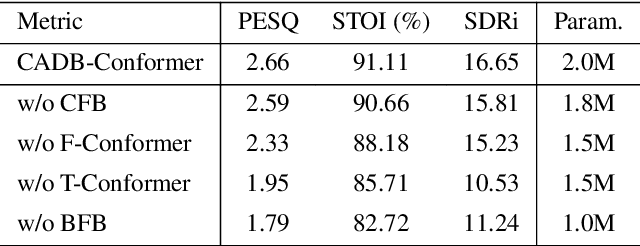
Recent speech enhancement methods based on convolutional neural networks (CNNs) and transformer have been demonstrated to efficaciously capture time-frequency (T-F) information on spectrogram. However, the correlation of each channels of speech features is failed to explore. Theoretically, each channel map of speech features obtained by different convolution kernels contains information with different scales demonstrating strong correlations. To fill this gap, we propose a novel dual-branch architecture named channel-aware dual-branch conformer (CADB-Conformer), which effectively explores the long range time and frequency correlations among different channels, respectively, to extract channel relation aware time-frequency information. Ablation studies conducted on DNS-Challenge 2020 dataset demonstrate the importance of channel feature leveraging while showing the significance of channel relation aware T-F information for speech enhancement. Extensive experiments also show that the proposed model achieves superior performance than recent methods with an attractive computational costs.
SimuSOE: A Simulated Snoring Dataset for Obstructive Sleep Apnea-Hypopnea Syndrome Evaluation during Wakefulness
Jul 10, 2024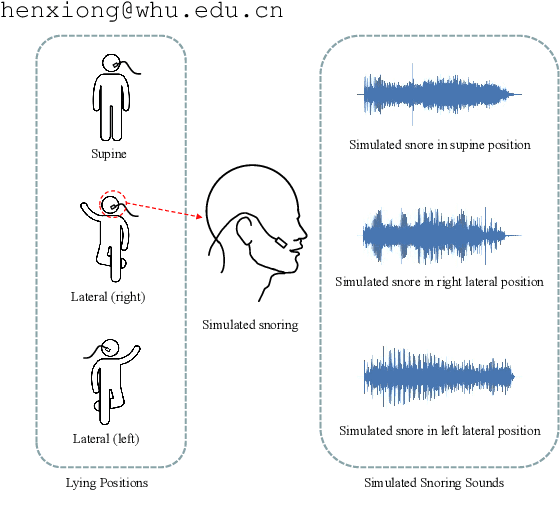

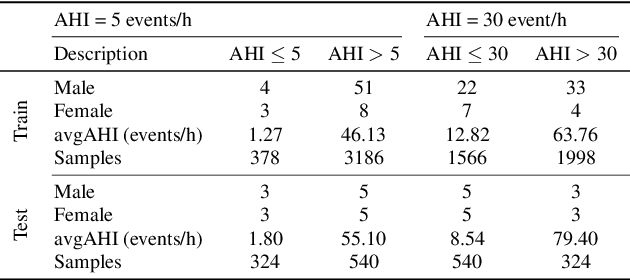
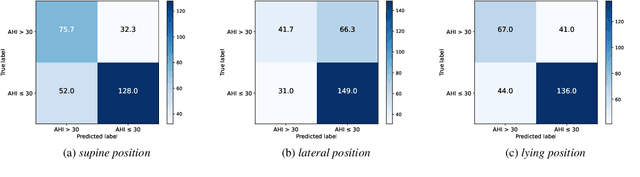
Obstructive Sleep Apnea-Hypopnea Syndrome (OSAHS) is a prevalent chronic breathing disorder caused by upper airway obstruction. Previous studies advanced OSAHS evaluation through machine learning-based systems trained on sleep snoring or speech signal datasets. However, constructing datasets for training a precise and rapid OSAHS evaluation system poses a challenge, since 1) it is time-consuming to collect sleep snores and 2) the speech signal is limited in reflecting upper airway obstruction. In this paper, we propose a new snoring dataset for OSAHS evaluation, named SimuSOE, in which a novel and time-effective snoring collection method is introduced for tackling the above problems. In particular, we adopt simulated snoring which is a type of snore intentionally emitted by patients to replace natural snoring. Experimental results indicate that the simulated snoring signal during wakefulness can serve as an effective feature in OSAHS preliminary screening.
SE Territory: Monaural Speech Enhancement Meets the Fixed Virtual Perceptual Space Mapping
Nov 03, 2023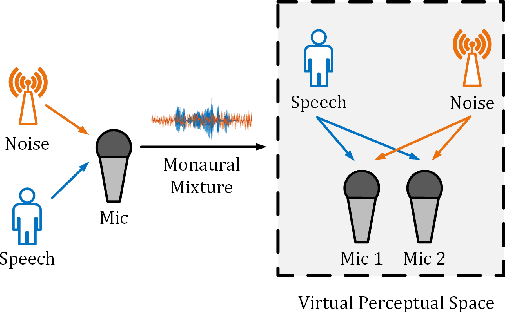



Monaural speech enhancement has achieved remarkable progress recently. However, its performance has been constrained by the limited spatial cues available at a single microphone. To overcome this limitation, we introduce a strategy to map monaural speech into a fixed simulation space for better differentiation between target speech and noise. Concretely, we propose SE-TerrNet, a novel monaural speech enhancement model featuring a virtual binaural speech mapping network via a two-stage multi-task learning framework. In the first stage, monaural noisy input is projected into a virtual space using supervised speech mapping blocks, creating binaural representations. These blocks synthesize binaural noisy speech from monaural input via an ideal binaural room impulse response. The synthesized output assigns speech and noise sources to fixed directions within the perceptual space. In the second stage, the obtained binaural features from the first stage are aggregated. This aggregation aims to decrease pattern discrepancies between the mapped binaural and original monaural features, achieved by implementing an intermediate fusion module. Furthermore, this stage incorporates the utilization of cross-attention to capture the injected virtual spatial information to improve the extraction of the target speech. Empirical studies highlight the effectiveness of virtual spatial cues in enhancing monaural speech enhancement. As a result, the proposed SE-TerrNet significantly surpasses the recent monaural speech enhancement methods in terms of both speech quality and intelligibility.
A comparative study of Grid and Natural sentences effects on Normal-to-Lombard conversion
Sep 19, 2023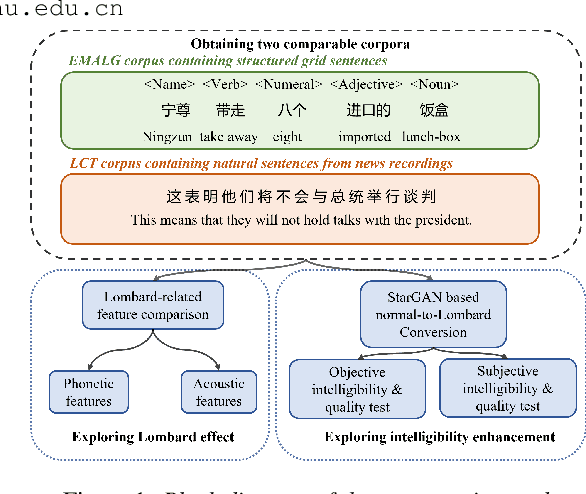
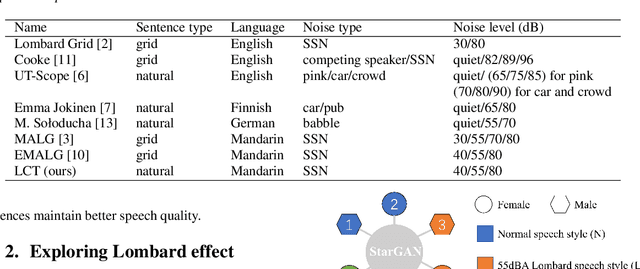
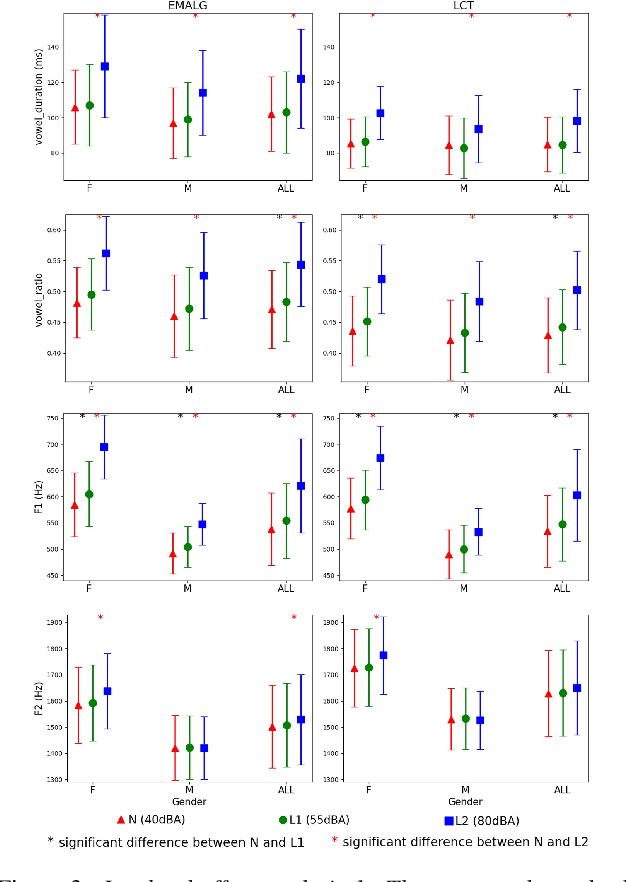
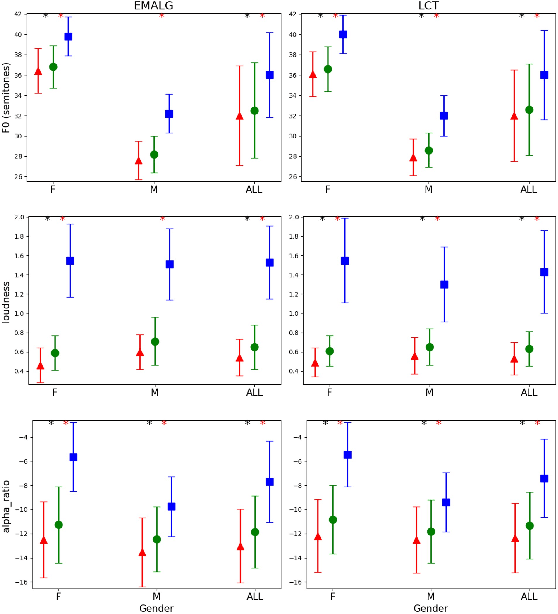
Grid sentence is commonly used for studying the Lombard effect and Normal-to-Lombard conversion. However, it's unclear if Normal-to-Lombard models trained on grid sentences are sufficient for improving natural speech intelligibility in real-world applications. This paper presents the recording of a parallel Lombard corpus (called Lombard Chinese TIMIT, LCT) extracting natural sentences from Chinese TIMIT. Then We compare natural and grid sentences in terms of Lombard effect and Normal-to-Lombard conversion using LCT and Enhanced MAndarin Lombard Grid corpus (EMALG). Through a parametric analysis of the Lombard effect, We find that as the noise level increases, both natural sentences and grid sentences exhibit similar changes in parameters, but in terms of the increase of the alpha ratio, grid sentences show a greater increase. Following a subjective intelligibility assessment across genders and Signal-to-Noise Ratios, the StarGAN model trained on EMALG consistently outperforms the model trained on LCT in terms of improving intelligibility. This superior performance may be attributed to EMALG's larger alpha ratio increase from normal to Lombard speech.
Mandarin Lombard Flavor Classification
Sep 14, 2023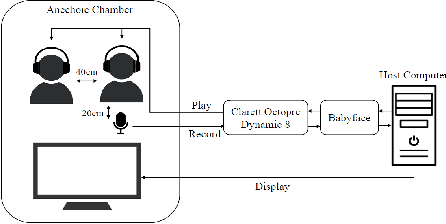
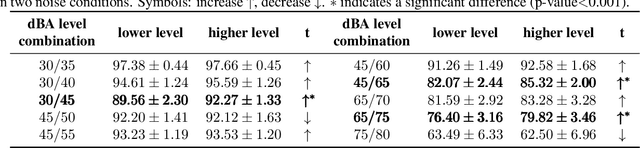
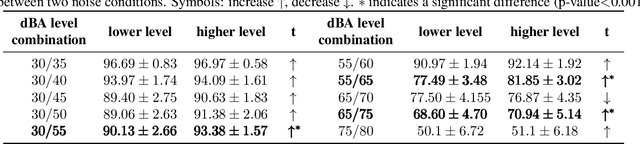
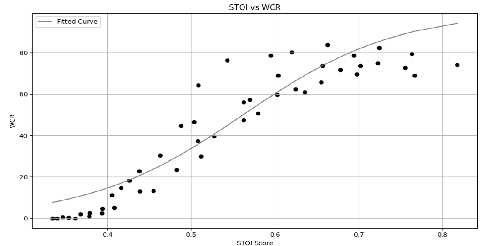
The Lombard effect refers to individuals' unconscious modulation of vocal effort in response to variations in the ambient noise levels, intending to enhance speech intelligibility. The impact of different decibel levels and types of background noise on Lombard effects remains unclear. Building upon the characteristic of Lombard speech that individuals adjust their speech to improve intelligibility dynamically based on the self-feedback speech, we propose a flavor classification approach for the Lombard effect. We first collected Mandarin Lombard speech under different noise conditions, then simulated self-feedback speech, and ultimately conducted the statistical test on the word correct rate. We found that both SSN and babble noise types result in four distinct categories of Mandarin Lombard speech in the range of 30 to 80 dBA with different transition points.