 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeCodec: A disentangled neural speech codec with fewer tokens
Paper and Code
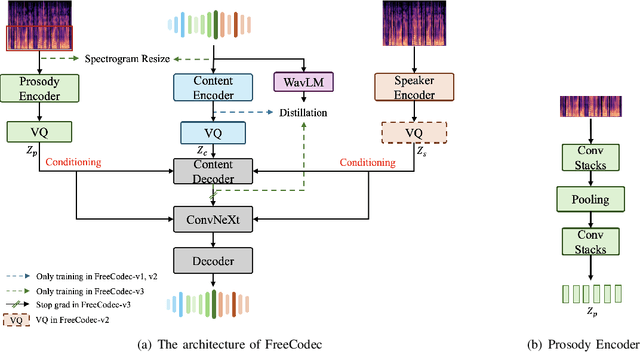
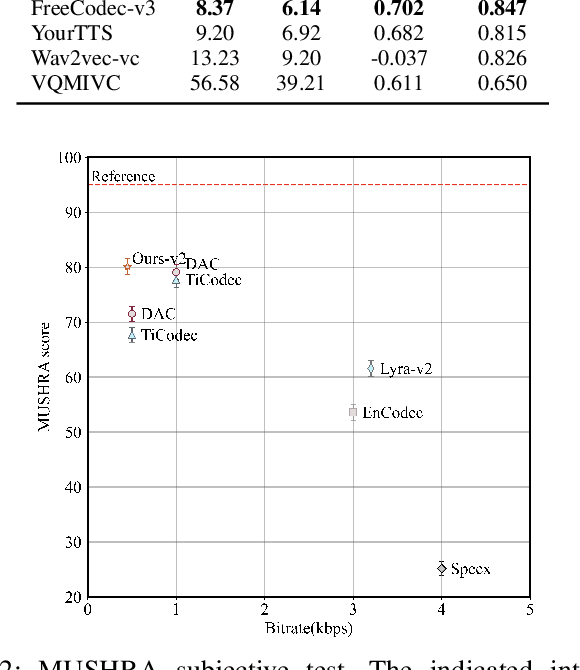
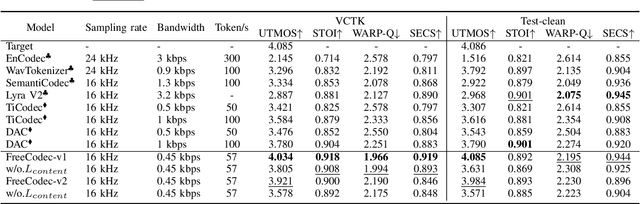
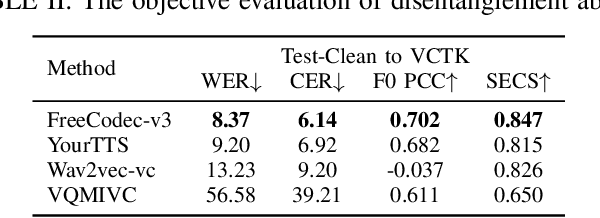
Neural speech codecs have gained great attention for their outstanding reconstruction with discrete token representations. It is a crucial component in generative tasks such as speech coding and large language models (LLM). However, most works based on residual vector quantization perform worse with fewer tokens due to low coding efficiency for modeling complex coupled information. In this paper, we propose a neural speech codec named FreeCodec which employs a more effective encoding framework by decomposing intrinsic properties of speech into different components: 1) a global vector is extracted as the timbre information, 2) a prosody encoder with a long stride level is used to model the prosody information, 3) the content information is from a content encoder. Using different training strategies, FreeCodec achieves state-of-the-art performance in reconstruction and disentanglement scenarios. Results from subjective and objective experiments demonstrate that our framework outperforms existing methods.