 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeCodec: A disentangled neural speech codec with fewer tokens
Dec 02, 2024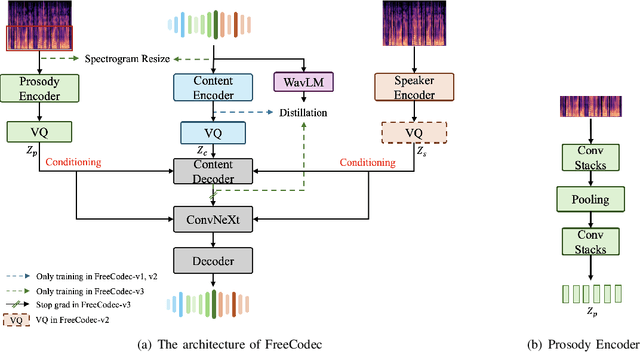
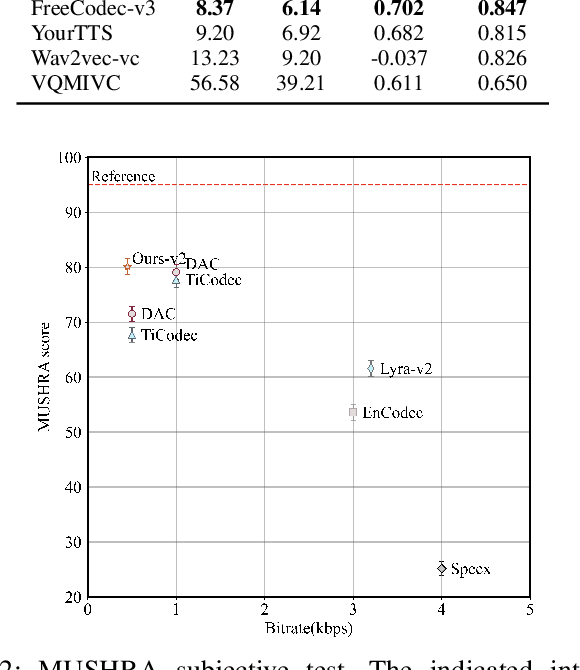
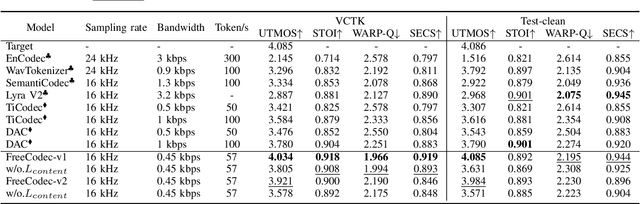
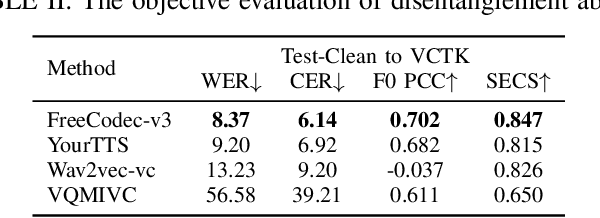
Neural speech codecs have gained great attention for their outstanding reconstruction with discrete token representations. It is a crucial component in generative tasks such as speech coding and large language models (LLM). However, most works based on residual vector quantization perform worse with fewer tokens due to low coding efficiency for modeling complex coupled information. In this paper, we propose a neural speech codec named FreeCodec which employs a more effective encoding framework by decomposing intrinsic properties of speech into different components: 1) a global vector is extracted as the timbre information, 2) a prosody encoder with a long stride level is used to model the prosody information, 3) the content information is from a content encoder. Using different training strategies, FreeCodec achieves state-of-the-art performance in reconstruction and disentanglement scenarios. Results from subjective and objective experiments demonstrate that our framework outperforms existing methods.
SuperCodec: A Neural Speech Codec with Selective Back-Projection Network
Jul 30, 2024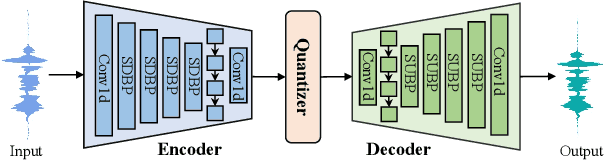
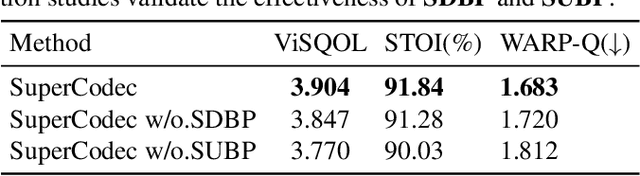
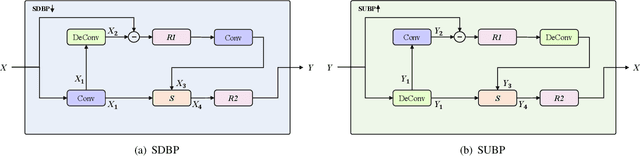

Neural speech coding is a rapidly developing topic, where state-of-the-art approaches now exhibit superior compression performance than conventional methods. Despite significant progress, existing methods still have limitations in preserving and reconstructing fine details for optimal reconstruction, especially at low bitrates. In this study, we introduce SuperCodec, a neural speech codec that achieves state-of-the-art performance at low bitrates. It employs a novel back projection method with selective feature fusion for augmented representation. Specifically, we propose to use Selective Up-sampling Back Projection (SUBP) and Selective Down-sampling Back Projection (SDBP) modules to replace the standard up- and down-sampling layers at the encoder and decoder, respectively. Experimental results show that our method outperforms the existing neural speech codecs operating at various bitrates. Specifically, our proposed method can achieve higher quality reconstructed speech at 1 kbps than Lyra V2 at 3.2 kbps and Encodec at 6 kbps.
CQNV: A combination of coarsely quantized bitstream and neural vocoder for low rate speech coding
Jul 25, 2023



Recently, speech codecs based on neural networks have proven to perform better than traditional methods. However, redundancy in traditional parameter quantization is visible within the codec architecture of combining the traditional codec with the neural vocoder. In this paper, we propose a novel framework named CQNV, which combines the coarsely quantized parameters of a traditional parametric codec to reduce the bitrate with a neural vocoder to improve the quality of the decoded speech. Furthermore, we introduce a parameters processing module into the neural vocoder to enhance the application of the bitstream of traditional speech coding parameters to the neural vocoder, further improving the reconstructed speech's quality. In the experiments, both subjective and objective evaluations demonstrate the effectiveness of the proposed CQNV framework. Specifically, our proposed method can achieve higher quality reconstructed speech at 1.1 kbps than Lyra and Encodec at 3 kbps.