 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPE-TTS: Customized Emotion Zero-Shot Text-To-Speech Using Multi-Modal Prompt
May 24, 2025Most existing Zero-Shot Text-To-Speech(ZS-TTS) systems generate the unseen speech based on single prompt, such as reference speech or text descriptions, which limits their flexibility. We propose a customized emotion ZS-TTS system based on multi-modal prompt. The system disentangles speech into the content, timbre, emotion and prosody, allowing emotion prompts to be provided as text, image or speech. To extract emotion information from different prompts, we propose a multi-modal prompt emotion encoder. Additionally, we introduce an prosody predictor to fit the distribution of prosody and propose an emotion consistency loss to preserve emotion information in the predicted prosody. A diffusion-based acoustic model is employed to generate the target mel-spectrogram. Both objective and subjective experiments demonstrate that our system outperforms existing systems in terms of naturalness and similarity. The samples are available at https://mpetts-demo.github.io/mpetts_demo/.
FreeCodec: A disentangled neural speech codec with fewer tokens
Dec 02, 2024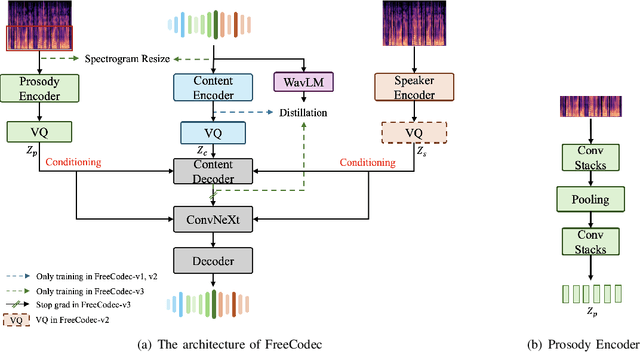
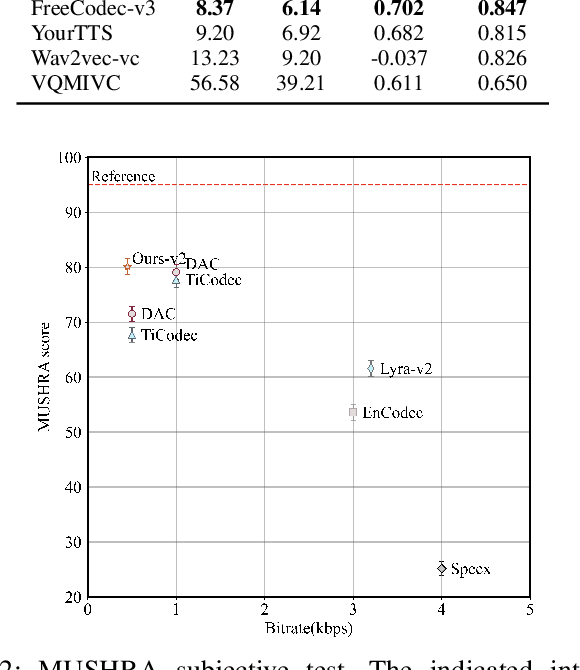
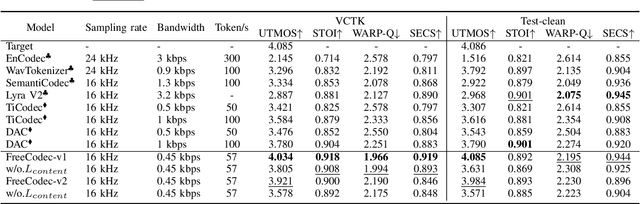
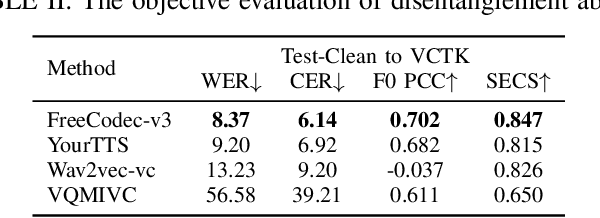
Neural speech codecs have gained great attention for their outstanding reconstruction with discrete token representations. It is a crucial component in generative tasks such as speech coding and large language models (LLM). However, most works based on residual vector quantization perform worse with fewer tokens due to low coding efficiency for modeling complex coupled information. In this paper, we propose a neural speech codec named FreeCodec which employs a more effective encoding framework by decomposing intrinsic properties of speech into different components: 1) a global vector is extracted as the timbre information, 2) a prosody encoder with a long stride level is used to model the prosody information, 3) the content information is from a content encoder. Using different training strategies, FreeCodec achieves state-of-the-art performance in reconstruction and disentanglement scenarios. Results from subjective and objective experiments demonstrate that our framework outperforms existing methods.
DistillW2V2: A Small and Streaming Wav2vec 2.0 Based ASR Model
Mar 16, 2023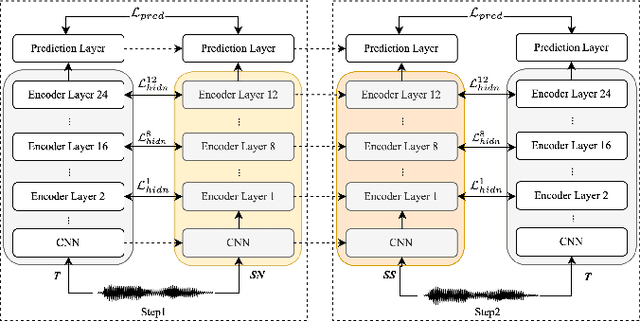
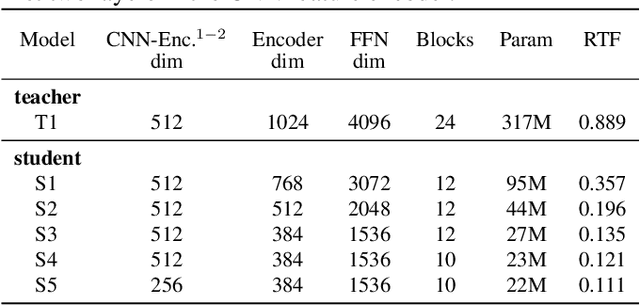
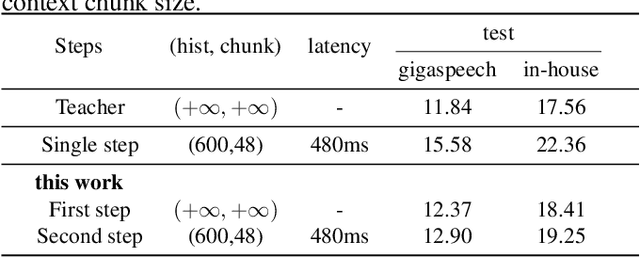
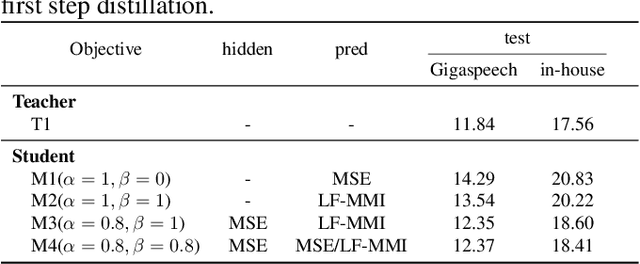
Wav2vec 2.0 (W2V2) has shown impressive performance in automatic speech recognition (ASR). However, the large model size and the non-streaming architecture make it hard to be used under low-resource or streaming scenarios. In this work, we propose a two-stage knowledge distillation method to solve these two problems: the first step is to make the big and non-streaming teacher model smaller, and the second step is to make it streaming. Specially, we adopt the MSE loss for the distillation of hidden layers and the modified LF-MMI loss for the distillation of the prediction layer. Experiments are conducted on Gigaspeech, Librispeech, and an in-house dataset. The results show that the distilled student model (DistillW2V2) we finally get is 8x faster and 12x smaller than the original teacher model. For the 480ms latency setup, the DistillW2V2's relative word error rate (WER) degradation varies from 9% to 23.4% on test sets, which reveals a promising way to extend the W2V2's application scope.
Improving Streaming Transformer Based ASR Under a Framework of Self-supervised Learning
Sep 15, 2021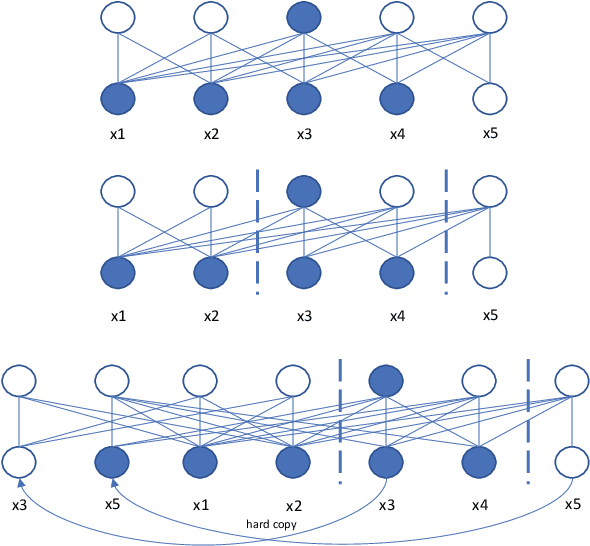
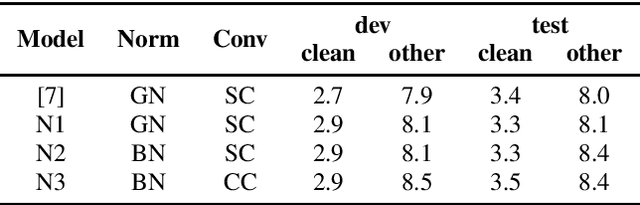
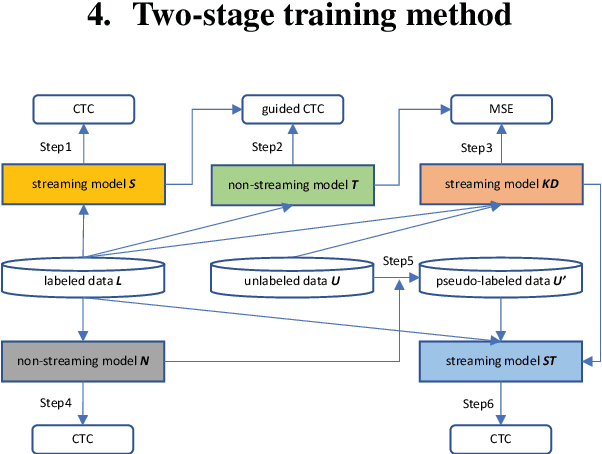
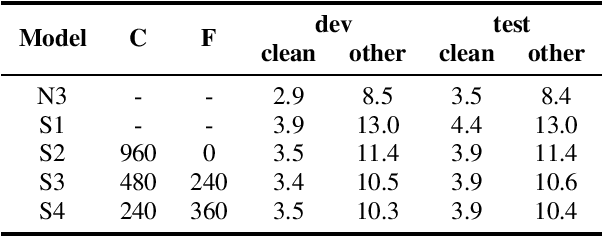
Recently self-supervised learning has emerged as an effective approach to improve the performance of automatic speech recognition (ASR). Under such a framework, the neural network is usually pre-trained with massive unlabeled data and then fine-tuned with limited labeled data. However, the non-streaming architecture like bidirectional transformer is usually adopted by the neural network to achieve competitive results, which can not be used in streaming scenarios. In this paper, we mainly focus on improving the performance of streaming transformer under the self-supervised learning framework. Specifically, we propose a novel two-stage training method during fine-tuning, which combines knowledge distilling and self-training. The proposed training method achieves 16.3% relative word error rate (WER) reduction on Librispeech noisy test set. Finally, by only using the 100h clean subset of Librispeech as the labeled data and the rest (860h) as the unlabeled data, our streaming transformer based model obtains competitive WERs 3.5/8.7 on Librispeech clean/noisy test sets.