 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeedup Patch: Learning a Plug-and-Play Policy to Accelerate Embodied Manipulation
Mar 21, 2026While current embodied policies exhibit remarkable manipulation skills, their execution remains unsatisfactorily slow as they inherit the tardy pacing of human demonstrations. Existing acceleration methods typically require policy retraining or costly online interactions, limiting their scalability for large-scale foundation models. In this paper, we propose Speedup Patch (SuP), a lightweight, policy-agnostic framework that enables plug-and-play acceleration using solely offline data. SuP introduces an external scheduler that adaptively downsamples action chunks provided by embodied policies to eliminate redundancies. Specifically, we formalize the optimization of our scheduler as a Constrained Markov Decision Process (CMDP) aimed at maximizing efficiency without compromising task performance. Since direct success evaluation is infeasible in offline settings, SuP introduces World Model based state deviation as a surrogate metric to enforce safety constraints. By leveraging a learned world model as a virtual evaluator to predict counterfactual trajectories, the scheduler can be optimized via offline reinforcement learning. Empirical results on simulation benchmarks (Libero, Bigym) and real-world tasks validate that SuP achieves an overall 1.8x execution speedup for diverse policies while maintaining their original success rates.
Towards Practical World Model-based Reinforcement Learning for Vision-Language-Action Models
Mar 21, 2026Vision-Language-Action (VLA) models show strong generalization for robotic control, but finetuning them with reinforcement learning (RL) is constrained by the high cost and safety risks of real-world interaction. Training VLA models in interactive world models avoids these issues but introduces several challenges, including pixel-level world modeling, multi-view consistency, and compounding errors under sparse rewards. Building on recent advances across large multimodal models and model-based RL, we propose VLA-MBPO, a practical framework to tackle these problems in VLA finetuning. Our approach has three key design choices: (i) adapting unified multimodal models (UMMs) for data-efficient world modeling; (ii) an interleaved view decoding mechanism to enforce multi-view consistency; and (iii) chunk-level branched rollout to mitigate error compounding. Theoretical analysis and experiments across simulation and real-world tasks demonstrate that VLA-MBPO significantly improves policy performance and sample efficiency, underscoring its robustness and scalability for real-world robotic deployment.
MPE-TTS: Customized Emotion Zero-Shot Text-To-Speech Using Multi-Modal Prompt
May 24, 2025Most existing Zero-Shot Text-To-Speech(ZS-TTS) systems generate the unseen speech based on single prompt, such as reference speech or text descriptions, which limits their flexibility. We propose a customized emotion ZS-TTS system based on multi-modal prompt. The system disentangles speech into the content, timbre, emotion and prosody, allowing emotion prompts to be provided as text, image or speech. To extract emotion information from different prompts, we propose a multi-modal prompt emotion encoder. Additionally, we introduce an prosody predictor to fit the distribution of prosody and propose an emotion consistency loss to preserve emotion information in the predicted prosody. A diffusion-based acoustic model is employed to generate the target mel-spectrogram. Both objective and subjective experiments demonstrate that our system outperforms existing systems in terms of naturalness and similarity. The samples are available at https://mpetts-demo.github.io/mpetts_demo/.
DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-speech Generation
Sep 13, 2023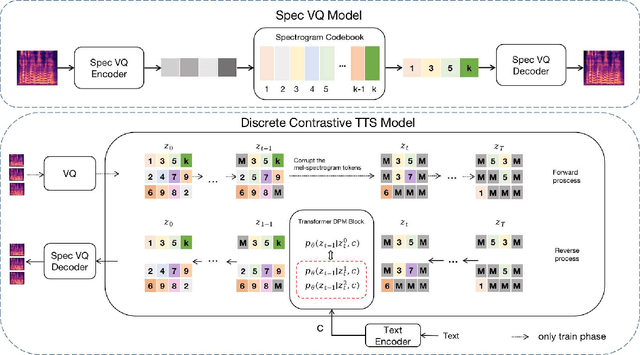
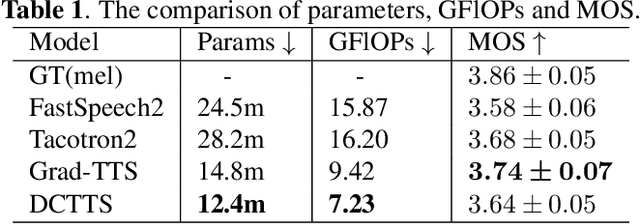
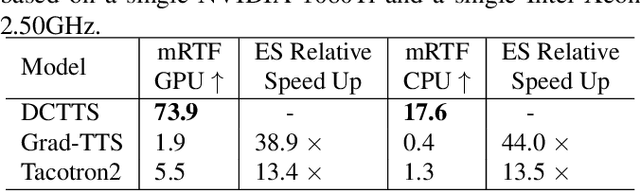

In the Text-to-speech(TTS) task, the latent diffusion model has excellent fidelity and generalization, but its expensive resource consumption and slow inference speed have always been a challenging. This paper proposes Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation(DCTTS). The following contributions are made by DCTTS: 1) The TTS diffusion model based on discrete space significantly lowers the computational consumption of the diffusion model and improves sampling speed; 2) The contrastive learning method based on discrete space is used to enhance the alignment connection between speech and text and improve sampling quality; and 3) It uses an efficient text encoder to simplify the model's parameters and increase computational efficiency. The experimental results demonstrate that the approach proposed in this paper has outstanding speech synthesis quality and sampling speed while significantly reducing the resource consumption of diffusion model. The synthesized samples are available at https://github.com/lawtherWu/DCTTS.
A deep learning framework for the detection and quantification of drusen and reticular pseudodrusen on optical coherence tomography
Apr 05, 2022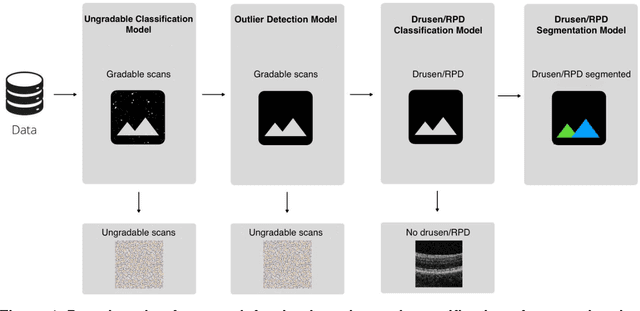
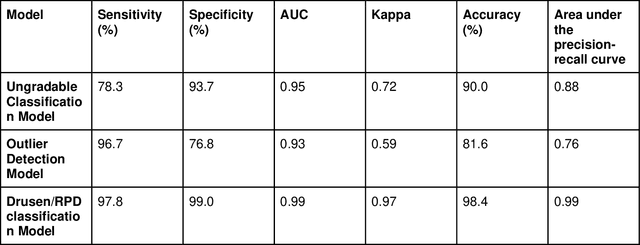
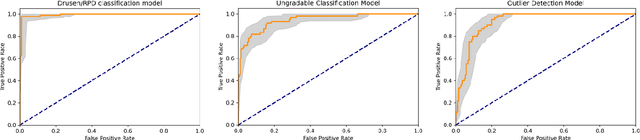

Purpose - To develop and validate a deep learning (DL) framework for the detection and quantification of drusen and reticular pseudodrusen (RPD) on optical coherence tomography scans. Design - Development and validation of deep learning models for classification and feature segmentation. Methods - A DL framework was developed consisting of a classification model and an out-of-distribution (OOD) detection model for the identification of ungradable scans; a classification model to identify scans with drusen or RPD; and an image segmentation model to independently segment lesions as RPD or drusen. Data were obtained from 1284 participants in the UK Biobank (UKBB) with a self-reported diagnosis of age-related macular degeneration (AMD) and 250 UKBB controls. Drusen and RPD were manually delineated by five retina specialists. The main outcome measures were sensitivity, specificity, area under the ROC curve (AUC), kappa, accuracy and intraclass correlation coefficient (ICC). Results - The classification models performed strongly at their respective tasks (0.95, 0.93, and 0.99 AUC, respectively, for the ungradable scans classifier, the OOD model, and the drusen and RPD classification model). The mean ICC for drusen and RPD area vs. graders was 0.74 and 0.61, respectively, compared with 0.69 and 0.68 for intergrader agreement. FROC curves showed that the model's sensitivity was close to human performance. Conclusions - The models achieved high classification and segmentation performance, similar to human performance. Application of this robust framework will further our understanding of RPD as a separate entity from drusen in both research and clinical settings.
Unsupervised Image Segmentation using Mutual Mean-Teaching
Dec 16, 2020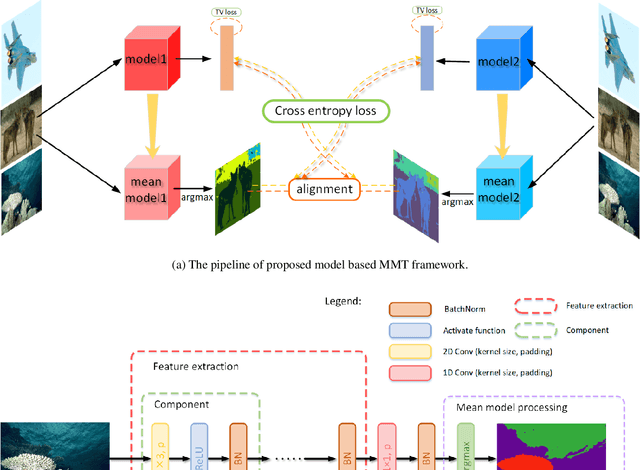
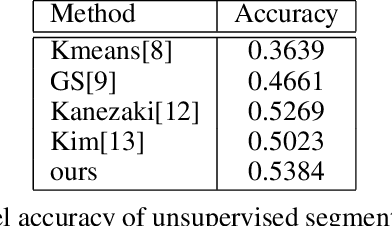
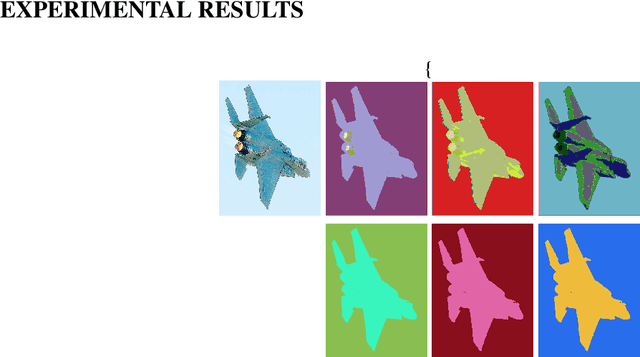

Unsupervised image segmentation aims at assigning the pixels with similar feature into a same cluster without annotation, which is an important task in computer vision. Due to lack of prior knowledge, most of existing model usually need to be trained several times to obtain suitable results. To address this problem, we propose an unsupervised image segmentation model based on the Mutual Mean-Teaching (MMT) framework to produce more stable results. In addition, since the labels of pixels from two model are not matched, a label alignment algorithm based on the Hungarian algorithm is proposed to match the cluster labels. Experimental results demonstrate that the proposed model is able to segment various types of images and achieves better performance than the existing methods.
Modeling Disease Progression In Retinal OCTs With Longitudinal Self-Supervised Learning
Oct 24, 2019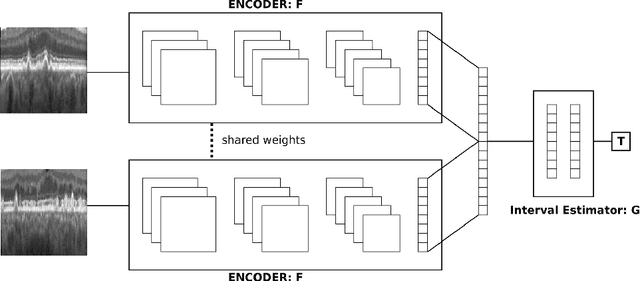
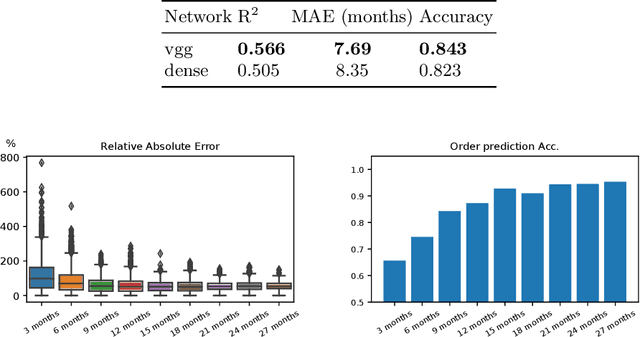
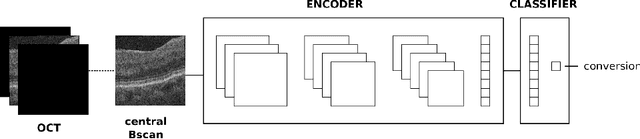
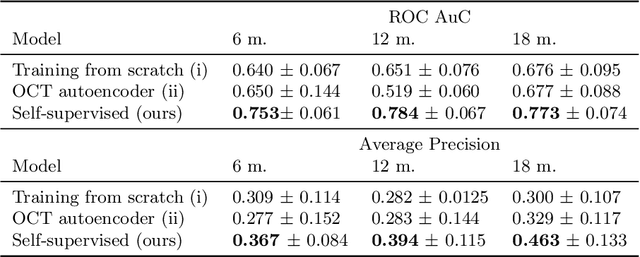
Longitudinal imaging is capable of capturing the static ana\-to\-mi\-cal structures and the dynamic changes of the morphology resulting from aging or disease progression. Self-supervised learning allows to learn new representation from available large unlabelled data without any expert knowledge. We propose a deep learning self-supervised approach to model disease progression from longitudinal retinal optical coherence tomography (OCT). Our self-supervised model takes benefit from a generic time-related task, by learning to estimate the time interval between pairs of scans acquired from the same patient. This task is (i) easy to implement, (ii) allows to use irregularly sampled data, (iii) is tolerant to poor registration, and (iv) does not rely on additional annotations. This novel method learns a representation that focuses on progression specific information only, which can be transferred to other types of longitudinal problems. We transfer the learnt representation to a clinically highly relevant task of predicting the onset of an advanced stage of age-related macular degeneration within a given time interval based on a single OCT scan. The boost in prediction accuracy, in comparison to a network learned from scratch or transferred from traditional tasks, demonstrates that our pretrained self-supervised representation learns a clinically meaningful information.