 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillW2V2: A Small and Streaming Wav2vec 2.0 Based ASR Model
Paper and Code
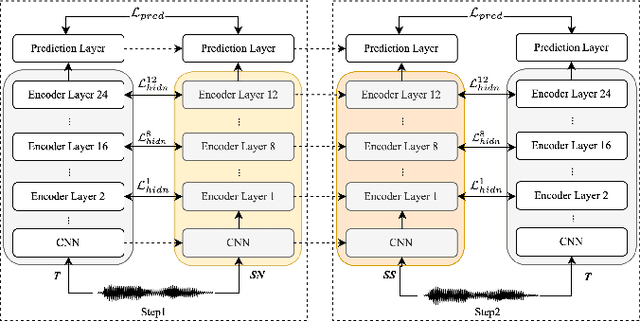
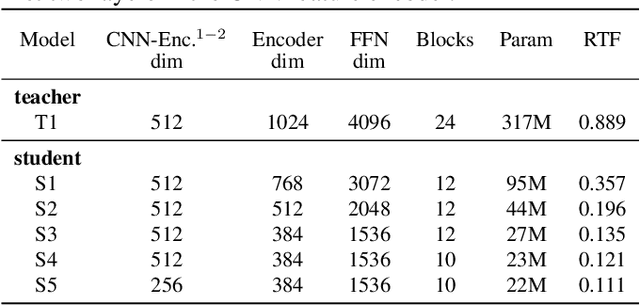
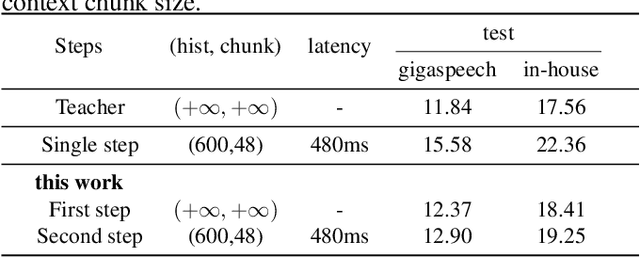
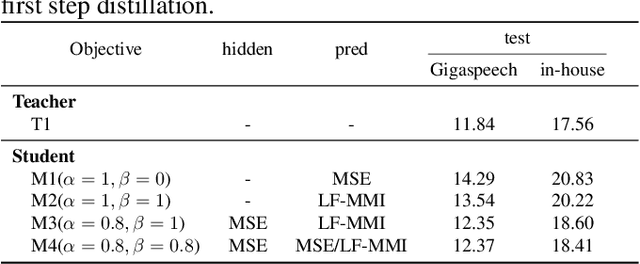
Wav2vec 2.0 (W2V2) has shown impressive performance in automatic speech recognition (ASR). However, the large model size and the non-streaming architecture make it hard to be used under low-resource or streaming scenarios. In this work, we propose a two-stage knowledge distillation method to solve these two problems: the first step is to make the big and non-streaming teacher model smaller, and the second step is to make it streaming. Specially, we adopt the MSE loss for the distillation of hidden layers and the modified LF-MMI loss for the distillation of the prediction layer. Experiments are conducted on Gigaspeech, Librispeech, and an in-house dataset. The results show that the distilled student model (DistillW2V2) we finally get is 8x faster and 12x smaller than the original teacher model. For the 480ms latency setup, the DistillW2V2's relative word error rate (WER) degradation varies from 9% to 23.4% on test sets, which reveals a promising way to extend the W2V2's application scope.