 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatNet: Effective FDR Control in LSTM with Gaussian Mirrors and SHAP Feature Importance
Nov 26, 2024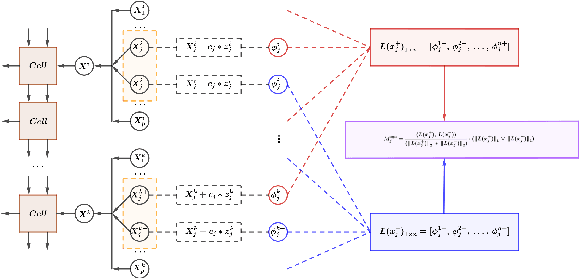
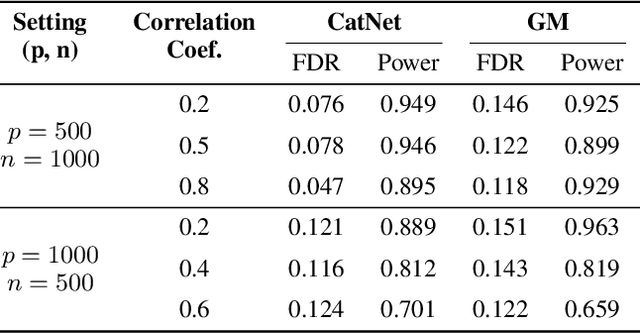
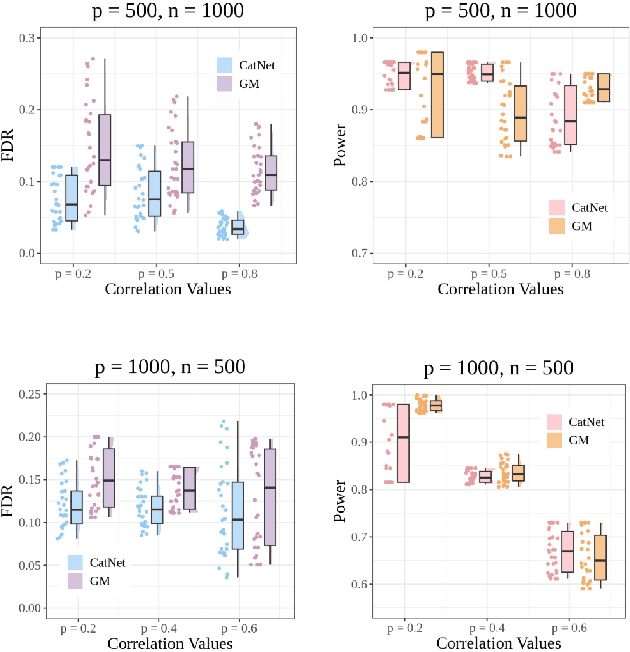
We introduce CatNet, an algorithm that effectively controls False Discovery Rate (FDR) and selects significant features in LSTM with the Gaussian Mirror (GM) method. To evaluate the feature importance of LSTM in time series, we introduce a vector of the derivative of the SHapley Additive exPlanations (SHAP) to measure feature importance. We also propose a new kernel-based dependence measure to avoid multicollinearity in the GM algorithm, to make a robust feature selection with controlled FDR. We use simulated data to evaluate CatNet's performance in both linear models and LSTM models with different link functions. The algorithm effectively controls the FDR while maintaining a high statistical power in all cases. We also evaluate the algorithm's performance in different low-dimensional and high-dimensional cases, demonstrating its robustness in various input dimensions. To evaluate CatNet's performance in real world applications, we construct a multi-factor investment portfolio to forecast the prices of S\&P 500 index components. The results demonstrate that our model achieves superior predictive accuracy compared to traditional LSTM models without feature selection and FDR control. Additionally, CatNet effectively captures common market-driving features, which helps informed decision-making in financial markets by enhancing the interpretability of predictions. Our study integrates of the Gaussian Mirror algorithm with LSTM models for the first time, and introduces SHAP values as a new feature importance metric for FDR control methods, marking a significant advancement in feature selection and error control for neural networks.
DistillW2V2: A Small and Streaming Wav2vec 2.0 Based ASR Model
Mar 16, 2023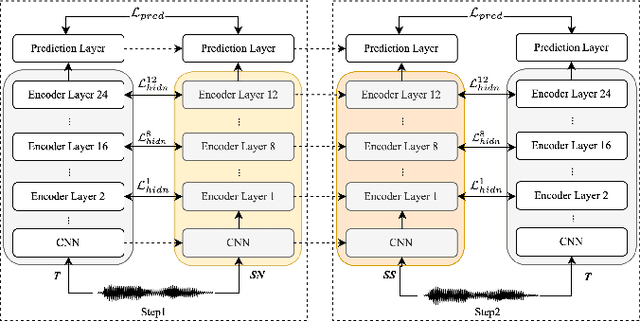
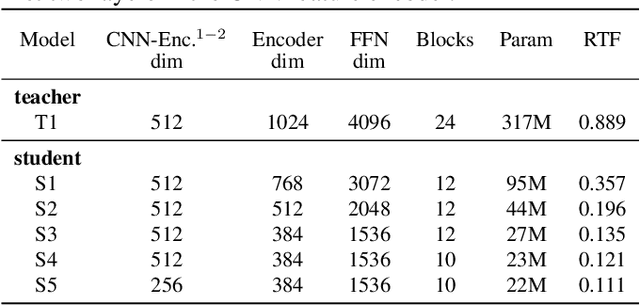
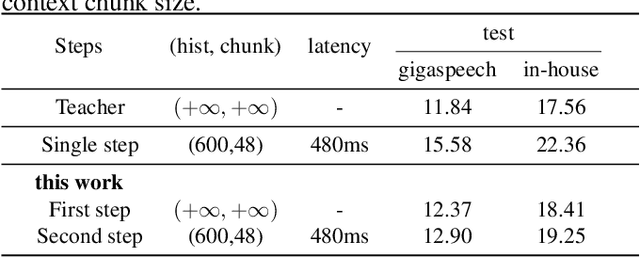
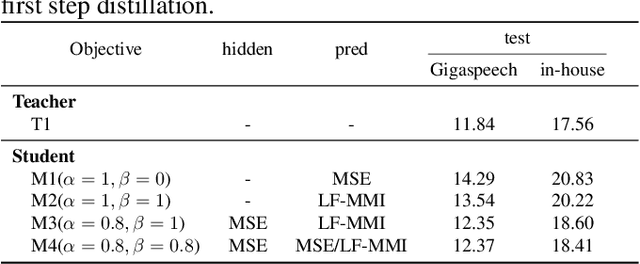
Wav2vec 2.0 (W2V2) has shown impressive performance in automatic speech recognition (ASR). However, the large model size and the non-streaming architecture make it hard to be used under low-resource or streaming scenarios. In this work, we propose a two-stage knowledge distillation method to solve these two problems: the first step is to make the big and non-streaming teacher model smaller, and the second step is to make it streaming. Specially, we adopt the MSE loss for the distillation of hidden layers and the modified LF-MMI loss for the distillation of the prediction layer. Experiments are conducted on Gigaspeech, Librispeech, and an in-house dataset. The results show that the distilled student model (DistillW2V2) we finally get is 8x faster and 12x smaller than the original teacher model. For the 480ms latency setup, the DistillW2V2's relative word error rate (WER) degradation varies from 9% to 23.4% on test sets, which reveals a promising way to extend the W2V2's application scope.
Improving Streaming Transformer Based ASR Under a Framework of Self-supervised Learning
Sep 15, 2021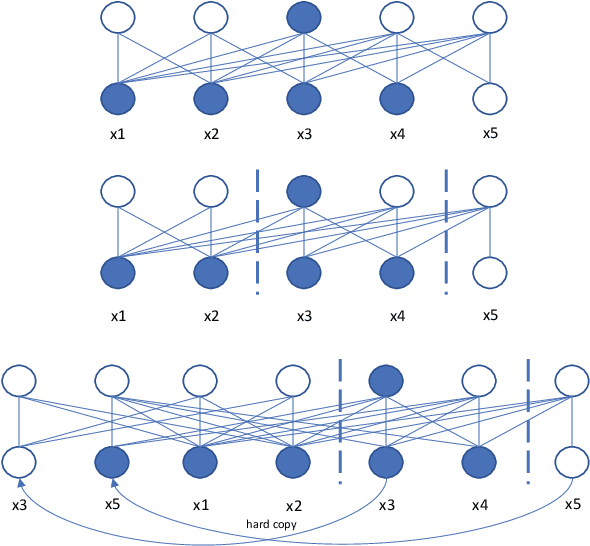
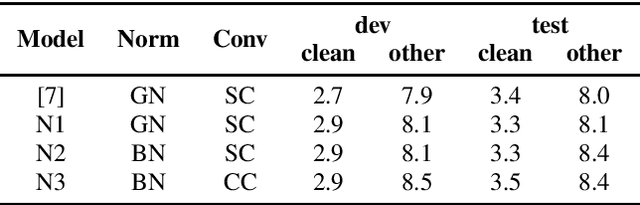
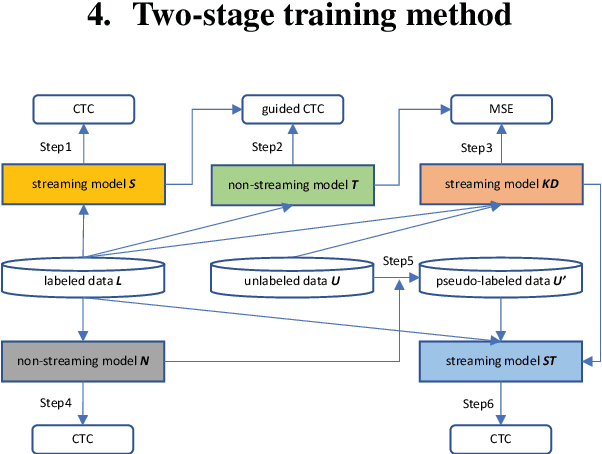
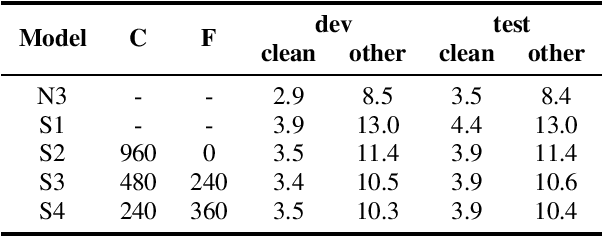
Recently self-supervised learning has emerged as an effective approach to improve the performance of automatic speech recognition (ASR). Under such a framework, the neural network is usually pre-trained with massive unlabeled data and then fine-tuned with limited labeled data. However, the non-streaming architecture like bidirectional transformer is usually adopted by the neural network to achieve competitive results, which can not be used in streaming scenarios. In this paper, we mainly focus on improving the performance of streaming transformer under the self-supervised learning framework. Specifically, we propose a novel two-stage training method during fine-tuning, which combines knowledge distilling and self-training. The proposed training method achieves 16.3% relative word error rate (WER) reduction on Librispeech noisy test set. Finally, by only using the 100h clean subset of Librispeech as the labeled data and the rest (860h) as the unlabeled data, our streaming transformer based model obtains competitive WERs 3.5/8.7 on Librispeech clean/noisy test sets.