 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatNet: Effective FDR Control in LSTM with Gaussian Mirrors and SHAP Feature Importance
Nov 26, 2024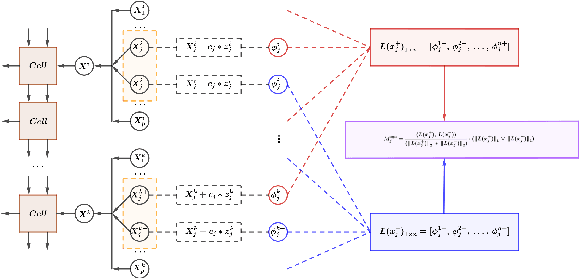
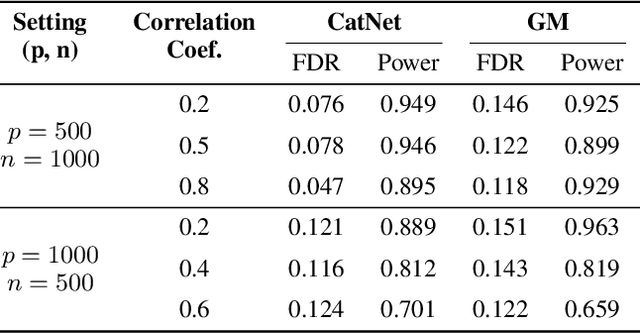
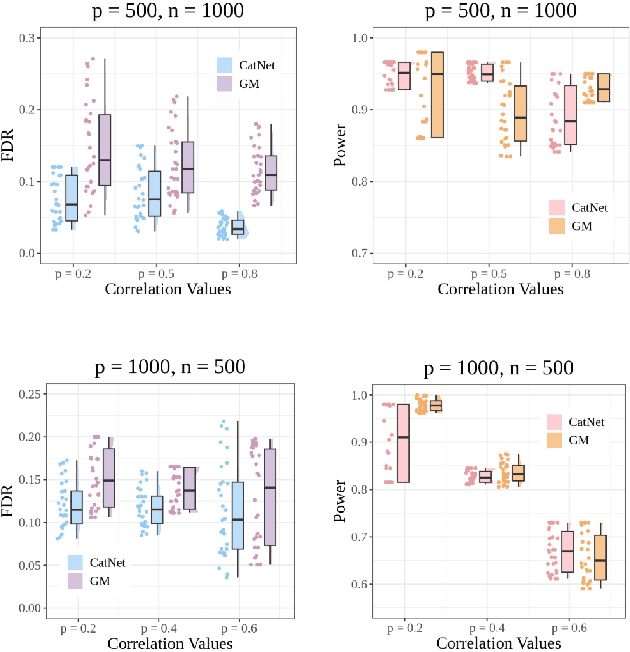
We introduce CatNet, an algorithm that effectively controls False Discovery Rate (FDR) and selects significant features in LSTM with the Gaussian Mirror (GM) method. To evaluate the feature importance of LSTM in time series, we introduce a vector of the derivative of the SHapley Additive exPlanations (SHAP) to measure feature importance. We also propose a new kernel-based dependence measure to avoid multicollinearity in the GM algorithm, to make a robust feature selection with controlled FDR. We use simulated data to evaluate CatNet's performance in both linear models and LSTM models with different link functions. The algorithm effectively controls the FDR while maintaining a high statistical power in all cases. We also evaluate the algorithm's performance in different low-dimensional and high-dimensional cases, demonstrating its robustness in various input dimensions. To evaluate CatNet's performance in real world applications, we construct a multi-factor investment portfolio to forecast the prices of S\&P 500 index components. The results demonstrate that our model achieves superior predictive accuracy compared to traditional LSTM models without feature selection and FDR control. Additionally, CatNet effectively captures common market-driving features, which helps informed decision-making in financial markets by enhancing the interpretability of predictions. Our study integrates of the Gaussian Mirror algorithm with LSTM models for the first time, and introduces SHAP values as a new feature importance metric for FDR control methods, marking a significant advancement in feature selection and error control for neural networks.
TarGAN: Target-Aware Generative Adversarial Networks for Multi-modality Medical Image Translation
May 19, 2021
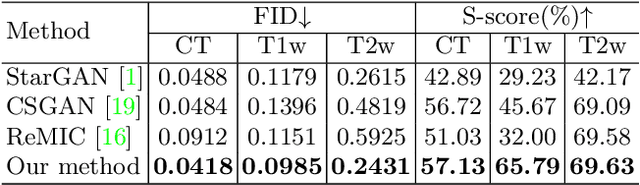
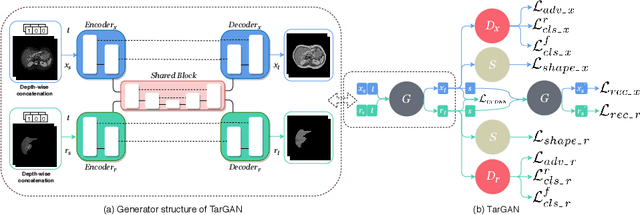
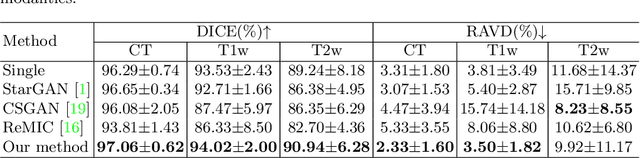
Paired multi-modality medical images, can provide complementary information to help physicians make more reasonable decisions than single modality medical images. But they are difficult to generate due to multiple factors in practice (e.g., time, cost, radiation dose). To address these problems, multi-modality medical image translation has aroused increasing research interest recently. However, the existing works mainly focus on translation effect of a whole image instead of a critical target area or Region of Interest (ROI), e.g., organ and so on. This leads to poor-quality translation of the localized target area which becomes blurry, deformed or even with extra unreasonable textures. In this paper, we propose a novel target-aware generative adversarial network called TarGAN, which is a generic multi-modality medical image translation model capable of (1) learning multi-modality medical image translation without relying on paired data, (2) enhancing quality of target area generation with the help of target area labels. The generator of TarGAN jointly learns mapping at two levels simultaneously - whole image translation mapping and target area translation mapping. These two mappings are interrelated through a proposed crossing loss. The experiments on both quantitative measures and qualitative evaluations demonstrate that TarGAN outperforms the state-of-the-art methods in all cases. Subsequent segmentation task is conducted to demonstrate effectiveness of synthetic images generated by TarGAN in a real-world application. Our code is available at https://github.com/2165998/TarGAN.