 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreferences Order, Ratings Anchor: From Fused Expert Aesthetic Ground Truth to Self-Distillation
May 20, 2026Pairwise preferences and pointwise ratings are the two dominant annotation protocols in image aesthetic assessment (IAA), yet existing benchmarks adopt only one, leaving their complementarity unmeasured under controlled conditions. We introduce PPaint, a matched dual-protocol benchmark in which 15 domain experts, 5 per category, annotate 150 Chinese paintings under both protocols across five aesthetic dimensions, collecting 45,900 pairwise expert judgments through a locally dense preference design alongside the matched ratings. The matched design reveals complementary strengths: preferences yield more consistent ordinal rankings, while ratings anchor the absolute score scale. Fusing both signals via two independent preference-to-score methods yields a fused expert ground truth on which the two constructions converge to nearly identical scores. The same preference-to-score principle extends to label-free VLM training. PSDistill converts VLM pairwise judgments into calibrated pseudo-scores via an Elo reference pool, and trains the same VLM with confidence-weighted ranking optimization to produce a single-pass aesthetic scorer. Trained on a single painting category, the distilled Qwen3-VL-8B improves mean SRCC from 0.504 to 0.709 across all three categories, outperforming all open-source baselines including the dedicated aesthetic model ArtiMuse and matching closed-source Gemini-3.1-Pro within 0.04 SRCC at single-pass inference cost, with cross-domain transfer further validated on APDDv2. We will release the full PPaint dataset and training code.
A scalable neural bundle map for multiphysics prediction in lithium-ion battery across varying configurations
Mar 17, 2026Efficient and accurate prediction of Multiphysics evolution across diverse cell geometries is fundamental to the design, management and safety of lithium-ion batteries. However, existing computational frameworks struggle to capture the coupled electrochemical, thermal, and mechanical dynamics across diverse cell geometries and varying operating conditions. Here, we present a Neural Bundle Map (NBM), a mathematically rigorous framework that reformulates multiphysics evolution as a bundle map over a geometric base manifold. This approach enables the complete decoupling of geometric complexity from underlying physical laws, ensuring strong operator continuity across varying domains. Our framework achieves high-fidelity spatiotemporal predictions with a normalized mean absolute error of less than 1% across varying configurations, while maintaining stability during long-horizon forecasting far beyond the training window and reducing computational costs by two orders of magnitude compared with conventional solvers. Leveraging this capability, we rapidly explored a vast configurational space to identify an optimal battery design that yields a 38% increase in energy density while adhering to thermal safety constraints. Furthermore, the NBM demonstrates remarkable scalability to multi-cell systems through few-shot transfer learning, providing a foundational paradigm for the intelligent design and real-time monitoring of complex energy storage infrastructures.
MSECG: Incorporating Mamba for Robust and Efficient ECG Super-Resolution
Dec 06, 2024Electrocardiogram (ECG) signals play a crucial role in diagnosing cardiovascular diseases. To reduce power consumption in wearable or portable devices used for long-term ECG monitoring, super-resolution (SR) techniques have been developed, enabling these devices to collect and transmit signals at a lower sampling rate. In this study, we propose MSECG, a compact neural network model designed for ECG SR. MSECG combines the strength of the recurrent Mamba model with convolutional layers to capture both local and global dependencies in ECG waveforms, allowing for the effective reconstruction of high-resolution signals. We also assess the model's performance in real-world noisy conditions by utilizing ECG data from the PTB-XL database and noise data from the MIT-BIH Noise Stress Test Database. Experimental results show that MSECG outperforms two contemporary ECG SR models under both clean and noisy conditions while using fewer parameters, offering a more powerful and robust solution for long-term ECG monitoring applications.
Adversarial Detection with a Dynamically Stable System
Nov 11, 2024



Adversarial detection is designed to identify and reject maliciously crafted adversarial examples(AEs) which are generated to disrupt the classification of target models. Presently, various input transformation-based methods have been developed on adversarial example detection, which typically rely on empirical experience and lead to unreliability against new attacks. To address this issue, we propose and conduct a Dynamically Stable System (DSS), which can effectively detect the adversarial examples from normal examples according to the stability of input examples. Particularly, in our paper, the generation of adversarial examples is considered as the perturbation process of a Lyapunov dynamic system, and we propose an example stability mechanism, in which a novel control term is added in adversarial example generation to ensure that the normal examples can achieve dynamic stability while the adversarial examples cannot achieve the stability. Then, based on the proposed example stability mechanism, a Dynamically Stable System (DSS) is proposed, which can utilize the disruption and restoration actions to determine the stability of input examples and detect the adversarial examples through changes in the stability of the input examples. In comparison with existing methods in three benchmark datasets(MNIST, CIFAR10, and CIFAR100), our evaluation results show that our proposed DSS can achieve ROC-AUC values of 99.83%, 97.81% and 94.47%, surpassing the state-of-the-art(SOTA) values of 97.35%, 91.10% and 93.49% in the other 7 methods.
SimuSOE: A Simulated Snoring Dataset for Obstructive Sleep Apnea-Hypopnea Syndrome Evaluation during Wakefulness
Jul 10, 2024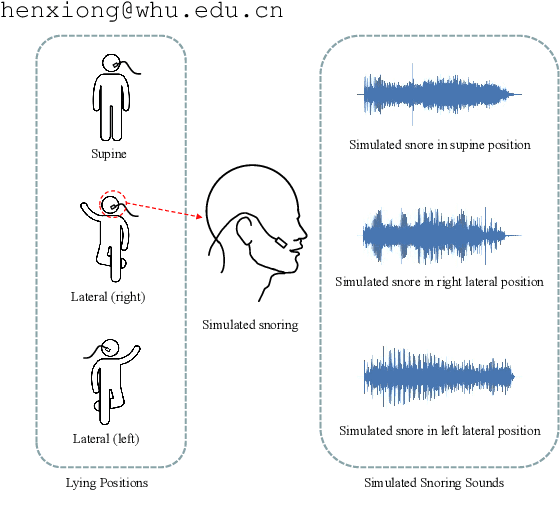

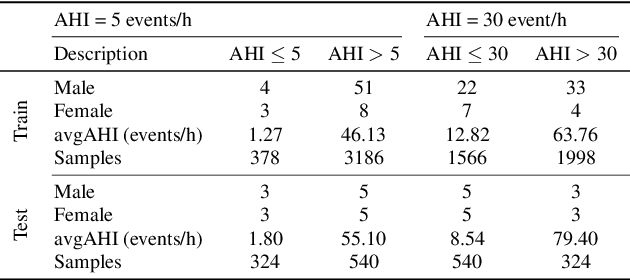
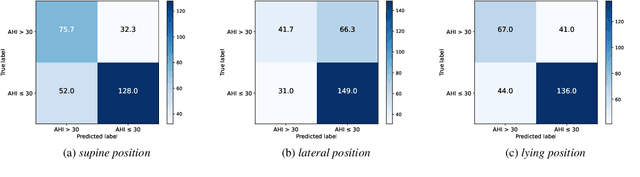
Obstructive Sleep Apnea-Hypopnea Syndrome (OSAHS) is a prevalent chronic breathing disorder caused by upper airway obstruction. Previous studies advanced OSAHS evaluation through machine learning-based systems trained on sleep snoring or speech signal datasets. However, constructing datasets for training a precise and rapid OSAHS evaluation system poses a challenge, since 1) it is time-consuming to collect sleep snores and 2) the speech signal is limited in reflecting upper airway obstruction. In this paper, we propose a new snoring dataset for OSAHS evaluation, named SimuSOE, in which a novel and time-effective snoring collection method is introduced for tackling the above problems. In particular, we adopt simulated snoring which is a type of snore intentionally emitted by patients to replace natural snoring. Experimental results indicate that the simulated snoring signal during wakefulness can serve as an effective feature in OSAHS preliminary screening.
LPViT: Low-Power Semi-structured Pruning for Vision Transformers
Jul 02, 2024
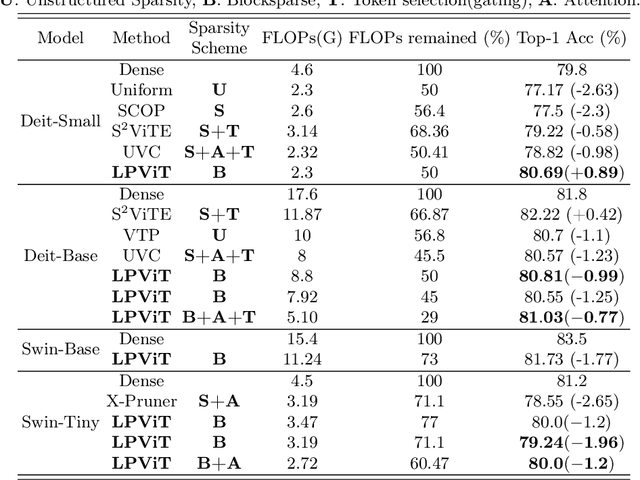

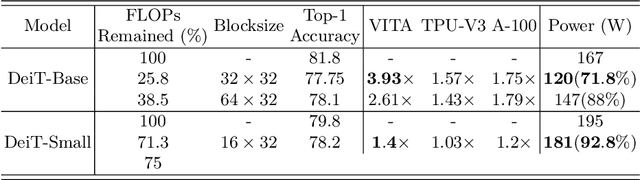
Vision transformers have emerged as a promising alternative to convolutional neural networks for various image analysis tasks, offering comparable or superior performance. However, one significant drawback of ViTs is their resource-intensive nature, leading to increased memory footprint, computation complexity, and power consumption. To democratize this high-performance technology and make it more environmentally friendly, it is essential to compress ViT models, reducing their resource requirements while maintaining high performance. In this paper, we introduce a new block-structured pruning to address the resource-intensive issue for ViTs, offering a balanced trade-off between accuracy and hardware acceleration. Unlike unstructured pruning or channel-wise structured pruning, block pruning leverages the block-wise structure of linear layers, resulting in more efficient matrix multiplications. To optimize this pruning scheme, our paper proposes a novel hardware-aware learning objective that simultaneously maximizes speedup and minimizes power consumption during inference, tailored to the block sparsity structure. This objective eliminates the need for empirical look-up tables and focuses solely on reducing parametrized layer connections. Moreover, our paper provides a lightweight algorithm to achieve post-training pruning for ViTs, utilizing second-order Taylor approximation and empirical optimization to solve the proposed hardware-aware objective. Extensive experiments on ImageNet are conducted across various ViT architectures, including DeiT-B and DeiT-S, demonstrating competitive performance with other pruning methods and achieving a remarkable balance between accuracy preservation and power savings. Especially, we achieve up to 3.93x and 1.79x speedups on dedicated hardware and GPUs respectively for DeiT-B, and also observe an inference power reduction by 1.4x on real-world GPUs.
Graph-based multi-Feature fusion method for speech emotion recognition
Jun 11, 2024Exploring proper way to conduct multi-speech feature fusion for cross-corpus speech emotion recognition is crucial as different speech features could provide complementary cues reflecting human emotion status. While most previous approaches only extract a single speech feature for emotion recognition, existing fusion methods such as concatenation, parallel connection, and splicing ignore heterogeneous patterns in the interaction between features and features, resulting in performance of existing systems. In this paper, we propose a novel graph-based fusion method to explicitly model the relationships between every pair of speech features. Specifically, we propose a multi-dimensional edge features learning strategy called Graph-based multi-Feature fusion method for speech emotion recognition. It represents each speech feature as a node and learns multi-dimensional edge features to explicitly describe the relationship between each feature-feature pair in the context of emotion recognition. This way, the learned multi-dimensional edge features encode speech feature-level information from both the vertex and edge dimensions. Our Approach consists of three modules: an Audio Feature Generation(AFG)module, an Audio-Feature Multi-dimensional Edge Feature(AMEF) module and a Speech Emotion Recognition (SER) module. The proposed methodology yielded satisfactory outcomes on the SEWA dataset. Furthermore, the method demonstrated enhanced performance compared to the baseline in the AVEC 2019 Workshop and Challenge. We used data from two cultures as our training and validation sets: two cultures containing German and Hungarian on the SEWA dataset, the CCC scores for German are improved by 17.28% for arousal and 7.93% for liking. The outcomes of our methodology demonstrate a 13% improvement over alternative fusion techniques, including those employing one dimensional edge-based feature fusion approach.
Timbre Perception, Representation, and its Neuroscientific Exploration: A Comprehensive Review
May 22, 2024Timbre, the sound's unique "color", is fundamental to how we perceive and appreciate music. This review explores the multifaceted world of timbre perception and representation. It begins by tracing the word's origin, offering an intuitive grasp of the concept. Building upon this foundation, the article delves into the complexities of defining and measuring timbre. It then explores the concept and techniques of timbre space, a powerful tool for visualizing how we perceive different timbres. The review further examines recent advancements in timbre manipulation and representation, including the increasingly utilized machine learning techniques. While the underlying neural mechanisms remain partially understood, the article discusses current neuroimaging techniques used to investigate this aspect of perception. Finally, it summarizes key takeaways, identifies promising future research directions, and emphasizes the potential applications of timbre research in music technology, assistive technologies, and our overall understanding of auditory perception.
From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
May 09, 2024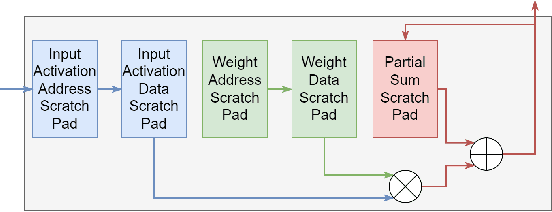
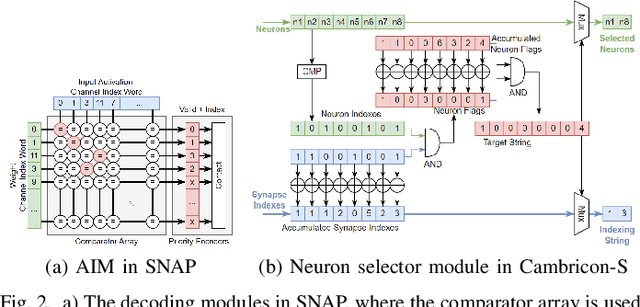
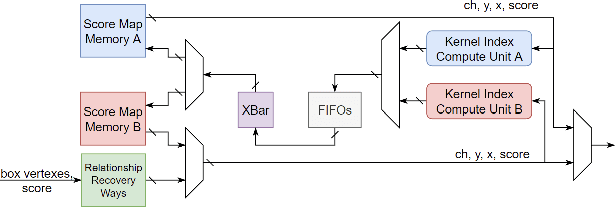

Deep neural networks (DNNs) have been widely used in many artificial intelligence (AI) tasks. However, deploying them brings significant challenges due to the huge cost of memory, energy, and computation. To address these challenges, researchers have developed various model compression techniques such as model quantization and model pruning. Recently, there has been a surge in research of compression methods to achieve model efficiency while retaining the performance. Furthermore, more and more works focus on customizing the DNN hardware accelerators to better leverage the model compression techniques. In addition to efficiency, preserving security and privacy is critical for deploying DNNs. However, the vast and diverse body of related works can be overwhelming. This inspires us to conduct a comprehensive survey on recent research toward the goal of high-performance, cost-efficient, and safe deployment of DNNs. Our survey first covers the mainstream model compression techniques such as model quantization, model pruning, knowledge distillation, and optimizations of non-linear operations. We then introduce recent advances in designing hardware accelerators that can adapt to efficient model compression approaches. Additionally, we discuss how homomorphic encryption can be integrated to secure DNN deployment. Finally, we discuss several issues, such as hardware evaluation, generalization, and integration of various compression approaches. Overall, we aim to provide a big picture of efficient DNNs, from algorithm to hardware accelerators and security perspectives.
Improving Group Connectivity for Generalization of Federated Deep Learning
Feb 29, 2024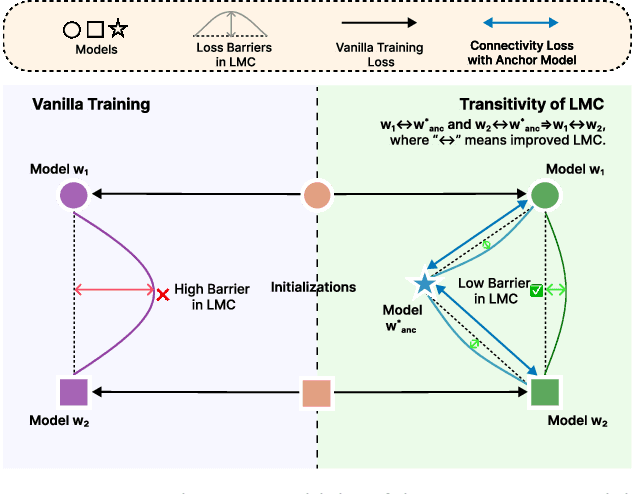

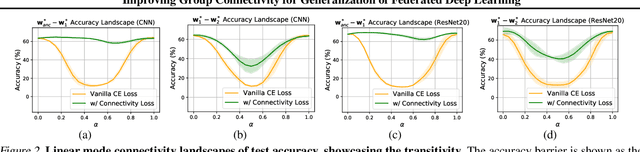

Federated learning (FL) involves multiple heterogeneous clients collaboratively training a global model via iterative local updates and model fusion. The generalization of FL's global model has a large gap compared with centralized training, which is its bottleneck for broader applications. In this paper, we study and improve FL's generalization through a fundamental ``connectivity'' perspective, which means how the local models are connected in the parameter region and fused into a generalized global model. The term ``connectivity'' is derived from linear mode connectivity (LMC), studying the interpolated loss landscape of two different solutions (e.g., modes) of neural networks. Bridging the gap between LMC and FL, in this paper, we leverage fixed anchor models to empirically and theoretically study the transitivity property of connectivity from two models (LMC) to a group of models (model fusion in FL). Based on the findings, we propose FedGuCci and FedGuCci+, improving group connectivity for better generalization. It is shown that our methods can boost the generalization of FL under client heterogeneity across various tasks (4 CV datasets and 6 NLP datasets), models (both convolutional and transformer-based), and training paradigms (both from-scratch and pretrain-finetune).